|
HADOOP_NAMENODE_OPTS
|
-Dcom.sun.management.jmxremote $HADOOP_NAMENODE_OPTS
|
该选项的值会附加到HADOOP_OPTS之后。在启动NameNode时设置的JVM參数。
如想手动设置NameNode的堆、垃圾回收等信息,能够在这里设置:
,我的内存没有这么大而且測试用例不会用到那么大的堆,所以我也设置了一个这个值。
|
export HADOOP_HEAPSIZE=20
|
HADOOP_PID_DIR:
Hadoop PID文件的存放文件夹,这个最好是改动一下,由于/tmp文件夹通常来说是不论什么人都能够訪问的。有可能存在符合链接攻击的风险。
|
export HADOOP_PID_DIR=/home/fenglibin/hadoop_tmp
|
2、配置$HADOOP_HOME/conf/core-site.xml
參数例如以下(部分):
|
參数
|
默认值
|
说明
|
|
fs.default.name
|
file:///
|
NameNode的URI,如:
hdfs://locahost:9000/
|
|
hadoop.tmp.dir
|
/tmp/hadoop-${user.name}
|
其他暂时文件夹的基本文件夹,
/home/fenglibin/hadoop_tmp
|
|
hadoop.native.lib
|
true
|
是否使用hadoop的本地库
|
|
hadoop.http.filter.initializers
|
空
|
设置Filter初使器,这些Filter必须是hadoop.http.filter.initializers的子类。能够同一时候设置多个,以逗号分隔。这些设置的Filter,将会对全部用户的jsp及servlet页面起作用。Filter的顺序与配置的顺序同样。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
配置演示样例:
|
<configuration>
<property>
<!-- 用于设置Hadoop的文件系统。由URI指定 -->
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<!-- 配置Hadoop的暂时文件夹,默认在/tmp文件夹下,可是/tmp上面可能会被系统自己主动清理掉。-->
<name>hadoop.tmp.dir</name>
<!-- 文件夹假设不存在。须要手动创建 -->
<value>/home/fenglibin/hadoop_tmp</value>
<description>A base for other temperary directory</description>
</property>
</configuration>
|
3、配置$HADOOP_HOME/conf/mapred-site.xml文件
參数例如以下(部分):
|
參数
|
说明
|
演示样例
|
|
mapred.job.tracker
|
配置JobTracker,以Host和IP的形式
|
localhost:9001
|
|
mapred.system.dir
|
MapReduce框架在HDFS存放系统文件的路径。必须能够被server及client訪问得到,默认值:
${hadoop.tmp.dir}/mapred/system
|
${hadoop.tmp.dir}/mapred/system
|
|
mapred.local.dir
|
MapReduce框架在本地的暂时文件夹,能够是多个,以逗号作分隔符,多个路径有助于分散IO的读写,默认值:
${hadoop.tmp.dir}/mapred/local
|
${hadoop.tmp.dir}/mapred/local
|
|
mapred.tasktracker.{map|reduce}.tasks.maximum
|
在同一台指定的TaskTacker上面同一时候独立的运行的MapReduce任务的最大数量,默认值是2(2个maps及2个reduces),这个与你所在硬件环境有非常大的关系,可分别设定。
|
2
|
|
dfs.hosts/dfs.hosts.exclude
|
同意/排除的NataNodes。假设有必要。使用这些文件控制同意的DataNodes。
|
|
|
mapred.hosts/mapred.hosts.exclude
|
同意/排除的MapReduces,假设有必要,使用这些文件控制同意的MapReduces。
|
|
|
mapred.queue.names
|
可用于提交Job的队列,多个以逗号分隔。MapReduce系统中至少存在一个名为“default”的队列,默认值就是“default”。
Hadoop中支持的一些任务定时器,如“Capacity Scheduler”。能够同一时候支持多个队列,假设使用了这样的定时器,那么使用的队列名称就必须在这里指定了。一旦指定了这些队列。用户在提交任务,通过在任务配置时指定“。而系统默认的复制份数为3。例如以下:
|
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
|
6、格式化namenode
7、启动Hadoop
假设是出现例如以下结果,那就说明Hadoop已经成功启动了:
|
fenglibin@ubuntu1110:/usr/local/hadoop-1.2.1$ jps
29339 SecondaryNameNode
29661 Jps
28830 JobTracker
29208 DataNode
28503 NameNode
29514 TaskTracker
|
此时我们能够通过WEB方式查看NameNode及Jobtracker的状态了:
NameNode:http://localhost:50070/
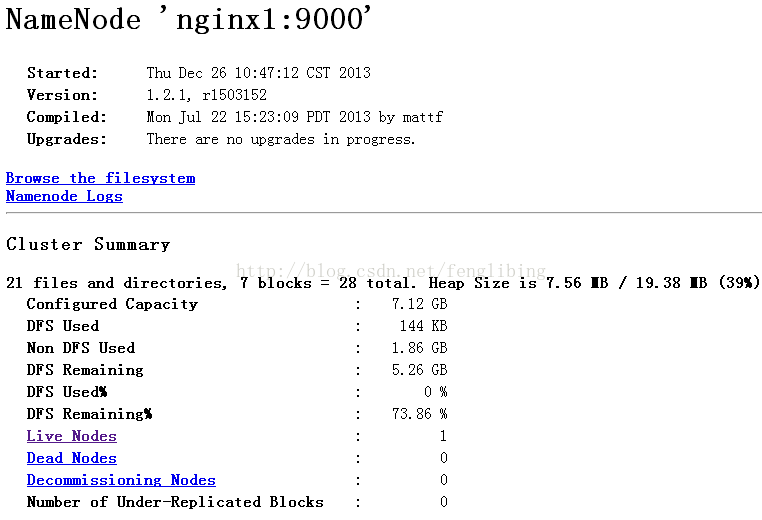
JobTracker:http://localhost:50030/
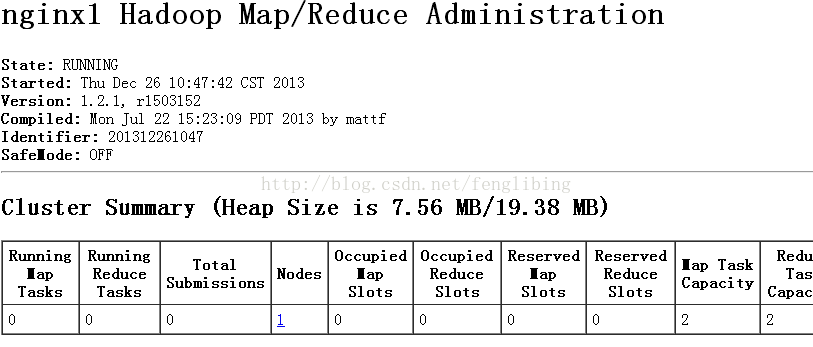
假设仅仅是測试map/reduce,这里仅仅须要启动例如以下命令:
8、启动Hadoop可能会遇到的问题
后面会提到。
- Hadoop入门进阶步步高(一)-环境准备
前言 Hadoop从存储上来说,是相似于冗余磁盘阵列(RAID)的存储方式.将数据分散存储并提供以提供吞吐量,它的存储系统就是HDFS(Hadoop Distuibute Fils System).从 ...
- Hadoop入门进阶步步高(六)-Hadoop1.x与Hadoop2的差别
六.Hadoop1.x与Hadoop2的差别 1.变更介绍 Hadoop2相比較于Hadoop1.x来说,HDFS的架构与MapReduce的都有较大的变化,且速度上和可用性上都有了非常大的提高,Ha ...
- Hadoop入门进阶步步高(五)-搭建Hadoop集群
五.搭建Hadoop集群 上面的步骤,确认了单机能够运行Hadoop的伪分布运行,真正的分布式运行无非也就是多几台slave机器而已,配置方面的有一点点差别,配置起来就很easy了. 1.准备三台se ...
- Hadoop入门进阶步步高(二)-文件夹介绍
二.Hadoop文件夹结构 这里重点介绍几个文件夹bin.conf及lib文件夹. 1.$HADOOP_HOME/bin文件夹 文件名 说明 hadoop 用于运行hadoop脚本命令,被hadoop ...
- Hadoop入门进阶课程4--HDFS原理及操作
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,博主为石山园,博客地址为 http://www.cnblogs.com/shishanyuan ...
- Hadoop入门进阶课程3--Hadoop2.X64位环境搭建
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,博主为石山园,博客地址为 http://www.cnblogs.com/shishanyuan ...
- Hadoop入门进阶课程1--Hadoop1.X伪分布式安装
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,博主为石山园,博客地址为 http://www.cnblogs.com/shishanyuan ...
- 分布式计算开源框架Hadoop入门实践(三)
Hadoop基本流程 一个图片太大了,只好分割成为两部分.根据流程图来说一下具体一个任务执行的情况. 在分布式环境中客户端创建任务并提交. InputFormat做Map前的预处理,主要负责以下工作: ...
- (转)Hadoop入门进阶课程
http://blog.csdn.net/yirenboy/article/details/46800855 1.Hadoop介绍 1.1Hadoop简介 Apache Hadoop软件库是一个框架, ...
随机推荐
- Web前端开发的就业前景怎么样,薪资待遇如何
信息技术的迅速发展,使IT技术者们赶上了一个百年难遇的好机会,尤其是国家出台了“互联网+”的政策后,更是催生了IT行业的就业空间,使其呈现爆发性增长. 如今,微信逐渐成为了大家主要的交流工具,随着各种 ...
- Java review-basic5
1. How would you write a socket client/server in Java The server DateServer.java package edu.lmu.cs. ...
- What every computer science major should know 每一个计算机科学专业的毕业生都应该都知道的
Given the expansive growth in the field, it's become challenging to discern what belongs in a modern ...
- WebBrowser修改默认白色背景
背景:在使用Winform的WebBrowser显示网页的时候,在网页还未加载完成之前会显示白色,刚好网页内容呈现黑色,这样视觉效果上就十分差,想把这层白色的去掉. 试了很久之后发现根本去不掉,应 ...
- vmware 与Device/Credential Guard不兼容
解决办法 关闭hv 重启就完了
- hystrix熔断器
在一个具有多服务的应用中,假如由于其中某一个服务出现问题,导致响应速度变慢,或是根本没有响应返回,会导致它的服务消费者由于长时间的等待,消耗尽线程,进而影响到对其他服务的线程调用,进而会转变为整个应用 ...
- set的基本使用
构造一个集合 现在我们来构造一个集合. C++ 中直接构造一个 set的语句为: sets.这样我们定义了一个名为 s的.储存 T类型数据的 集合,其中 T是集合要储存的数据类型.初始的时候 s是空集 ...
- web前端学习(三)css学习笔记部分(5)-- CSS动画--页面特效、HTML与CSS3简单页面效果实例
CSS动画--页面特效部分内容目前仅仅观看了解内容,记录简单笔记,之后工作了进行内容的补充 7. CSS动画--页面特效 7.1 2D.3D转换 7.1.1 通过CSS3转换,我们能够对元素进行 ...
- 高维护性的javascript
养成良好的编码习惯,提高代码的可维护性 避免定义全局变量或函数 定义全局的变量和函数,会影响代码的可维护性.如果在页面中运行的javascript 代码是在相同的作用域里面,那就可能代码之间存在互相影 ...
- LintCode_173 链表插入排序
题目 用插入排序对链表排序 样例 Given 1->3->2->0->null, return 0->1->2->3->null C++代码 ListN ...
| |