Hadoop入门进阶课程3--Hadoop2.X64位环境搭建
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,博主为石山园,博客地址为 http://www.cnblogs.com/shishanyuan 。该系列课程是应邀实验楼整理编写的,这里需要赞一下实验楼提供了学习的新方式,可以边看博客边上机实验,课程地址为 https://www.shiyanlou.com/courses/237
【注】该系列所使用到安装包、测试数据和代码均可在百度网盘下载,具体地址为 http://pan.baidu.com/s/10PnDs,下载该PDF文件
、搭建环境
部署节点操作系统为CentOS,防火墙和SElinux禁用,创建了一个shiyanlou用户并在系统根目录下创建/app目录,用于存放Hadoop等组件运行包。因为该目录用于安装hadoop等组件程序,用户对shiyanlou必须赋予rwx权限(一般做法是root用户在根目录下创建/app目录,并修改该目录拥有者为shiyanlou(chown –R shiyanlou:shiyanlou /app)。
Hadoop搭建环境:
l 虚拟机操作系统: CentOS6.6 64位,单核,1G内存
l JDK:1.7.0_55 64位
个实验所编译完成)
、部署Hadooop2.X
2.1配置Hadoop环境
位操作系统安装,在64位服务器安装会出现3.1的错误异常。这里我们使用上一步骤编译好的hadoop-2.2.0-bin.tar.gz文件作为安装包(也可以在/home/shiyanlou/install-pack目录中找到hadoop-2.2.0.tar.gz安装包)
2.1.1 下载并解压hadoop安装包
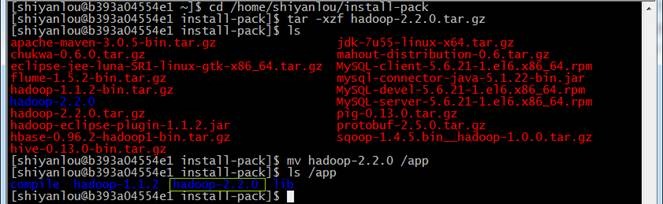
解压缩并移动到/app目录下
cd /home/shiyanlou/install-pack
tar -xzf hadoop-2.2.0.tar.gz
mv hadoop-2.2.0 /app
2.1.2 在Hadoop目录下创建子目录
在hadoop-2.2.0目录下创建tmp、name和data目录
cd /app/hadoop-2.2.0
mkdir tmp
mkdir hdfs
mkdir hdfs/name
mkdir hdfs/data

2.1.3配置hadoop-env.sh
1. 打开配置文件hadoop-env.sh
cd /app/hadoop-2.2.0/etc/hadoop
sudo vi hadoop-env.sh
2. 加入配置内容,设置了hadoop中jdk和hadoop/bin路径
export HADOOP_CONF_DIR=/app/hadoop2.2.0/etc/hadoop
export JAVA_HOME=/app/lib/jdk1.7.0_55
export PATH=$PATH:/app/hadoop-2.2.0/bin

3. 编译配置文件hadoop-env.sh,并确认生效
source hadoop-env.sh
hadoop version

2.1.4配置yarn-env.sh
打开配置文件yarn-env.sh,设置了hadoop中jdk路径,配置完毕后使用source yarn-env.sh编译该文件
export JAVA_HOME=/app/lib/jdk1.7.0_55

2.1.5配置core-site.xml
1. 使用如下命令打开core-site.xml配置文件
cd /app/hadoop-2.2.0/etc/hadoop
sudo vi core-site.xml
2. 在配置文件中,按照如下内容进行配置
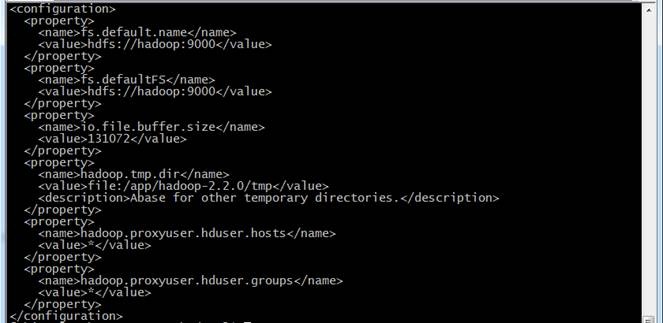
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop:9000</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/app/hadoop-2.2.0/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>hadoop.proxyuser.hduser.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hduser.groups</name>
<value>*</value>
</property>
</configuration>
2.1.6配置hdfs-site.xml
1. 使用如下命令打开hdfs-site.xml配置文件
cd /app/hadoop-2.2.0/etc/hadoop
sudo vi hdfs-site.xml
2.在配置文件中,按照如下内容进行配置
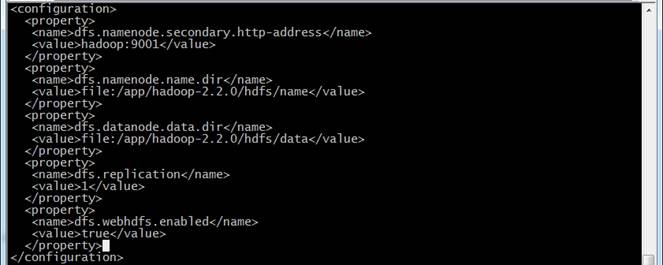
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/app/hadoop-2.2.0/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/app/hadoop-2.2.0/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
2.1.7配置mapred-site.xml
1.默认情况下不存在mapred-site.xml文件,可以从模板拷贝一份,并使用如下命令打开mapred-site.xml配置文件
cd /app/hadoop-2.2.0/etc/hadoop
cp mapred-site.xml.template mapred-site.xml
sudo vi mapred-site.xml
2.在配置文件中,按照如下内容进行配置
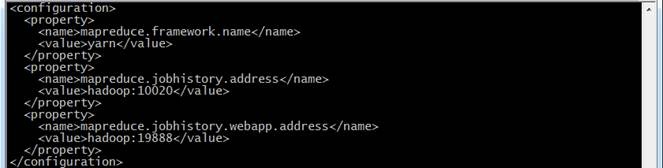
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop:19888</value>
</property>
</configuration>
2.1.8配置yarn-site.xml
1.使用如下命令打开yarn-site.xml配置文件
cd /app/hadoop-2.2.0/etc/hadoop
sudo vi yarn-site.xml
2.在配置文件中,按照如下内容进行配置
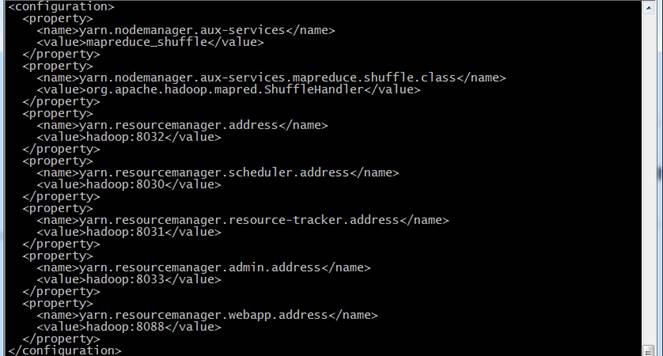
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop:8088</value>
</property>
</configuration>
2.1.9配置slaves文件
在slaves配置文件中设置从节点,这里设置为hadoop,与Hadoop1.X区别的是Hadoop2.X不需要设置Master
cd /app/hadoop-2.2.0/etc/hadoop
vi slaves

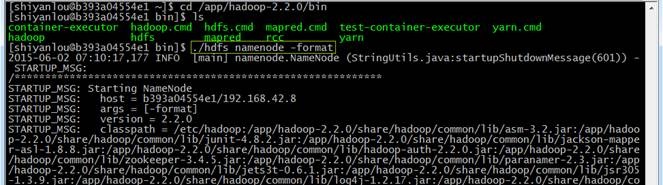
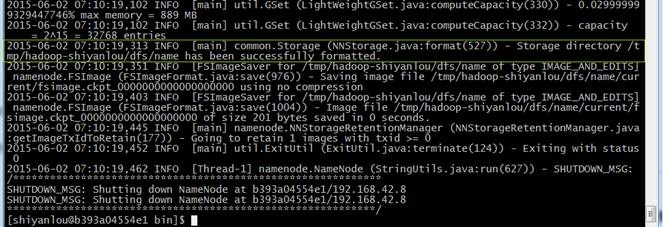
2.1.10格式化namenode
cd /app/hadoop-2.2.0/bin
./hdfs namenode -format
2.2启动Hadoop
2.2.1启动hdfs
cd /app/hadoop-2.2.0/sbin
./start-dfs.sh
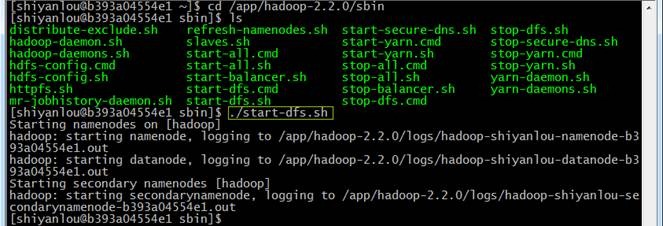
2.2.2验证当前进行
使用jps命令查看运行进程,此时在hadoop上面运行的进程有:namenode、secondarynamenode和datanode三个进行

2.2.3启动yarn
cd /app/hadoop-2.2.0/sbin
./start-yarn.sh

2.2.4验证当前进行
使用jps命令查看运行进程,此时在hadoop上运行的进程除了:namenode、secondarynamenode和datanode,增加了resourcemanager和nodemanager两个进程:

2.3测试Hadoop
2.3.1创建测试目录
cd /app/hadoop-2.2.0/bin
./hadoop fs -mkdir -p /class3/input

2.3.2准备测试数据
./hadoop fs -copyFromLocal ../etc/hadoop/* /class3/input

2.3.3运行wordcount例子
cd /app/hadoop-2.2.0/bin
./hadoop jar ../share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar wordcount /class3/input /class3/output
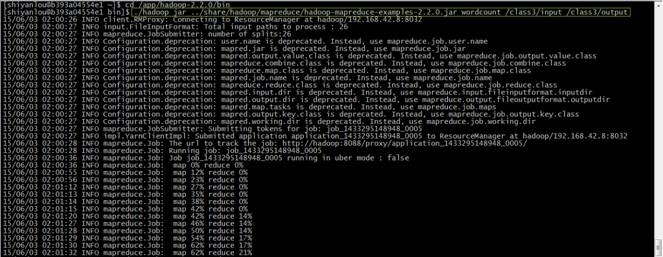
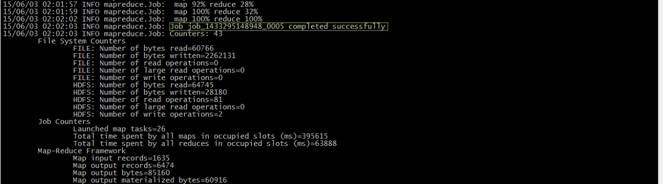
2.3.4查看结果
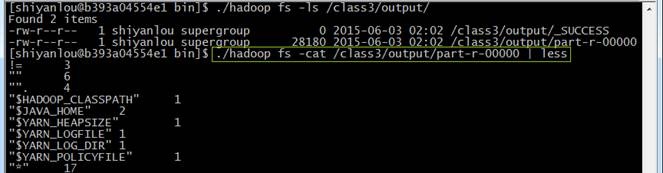
使用如下命令查看运行结果:
./hadoop fs -ls /class3/output/
./hadoop fs -cat /class3/output/part-r-00000 | less
、问题解决
3.1CentOS 64bit安装Hadoop2.2.0中出现文件编译位数异常
在安装hadoop2.2.0过程中出现如下异常:Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
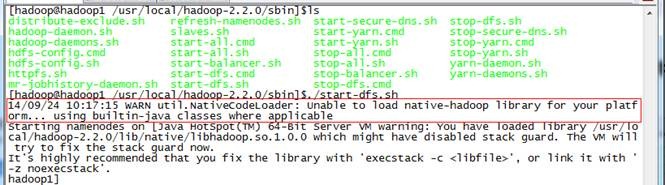
位编译,无法适应CentOS 64位环境造成

有两种办法解决:
l 重新编译hadoop,然后重新部署
l 暂时办法是修改配置,忽略有问题的文件

Hadoop入门进阶课程3--Hadoop2.X64位环境搭建的更多相关文章
- Hadoop入门进阶课程2--Hadoop2.X 64位编译
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,博主为石山园,博客地址为 http://www.cnblogs.com/shishanyuan ...
- (转)Hadoop入门进阶课程
http://blog.csdn.net/yirenboy/article/details/46800855 1.Hadoop介绍 1.1Hadoop简介 Apache Hadoop软件库是一个框架, ...
- Hadoop入门进阶课程1--Hadoop1.X伪分布式安装
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,博主为石山园,博客地址为 http://www.cnblogs.com/shishanyuan ...
- Hadoop入门进阶课程13--Chukwa介绍与安装部署
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,博主为石山园,博客地址为 http://www.cnblogs.com/shishanyuan ...
- Hadoop入门进阶课程12--Flume介绍、安装与应用案例
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,博主为石山园,博客地址为 http://www.cnblogs.com/shishanyuan ...
- Hadoop入门进阶课程11--Sqoop介绍、安装与操作
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,博主为石山园,博客地址为 http://www.cnblogs.com/shishanyuan ...
- Hadoop入门进阶课程10--HBase介绍、安装与应用案例
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,博主为石山园,博客地址为 http://www.cnblogs.com/shishanyuan ...
- Hadoop入门进阶课程9--Mahout介绍、安装与应用案例
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,博主为石山园,博客地址为 http://www.cnblogs.com/shishanyuan ...
- Hadoop入门进阶课程8--Hive介绍和安装部署
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,博主为石山园,博客地址为 http://www.cnblogs.com/shishanyuan ...
随机推荐
- android: 使用 AsyncTask
9.2.4 使用 AsyncTask 不过为了更加方便我们在子线程中对 UI 进行操作,Android 还提供了另外一些好用的工 具,AsyncTask 就是其中之一.借助 AsyncTask, ...
- iPhone屏幕尺寸、分辨率及适配
转:http://blog.csdn.net/phunxm/article/details/42174937 目录(?)[+] 1.iPhone尺寸规格 设备 iPhone 宽 Width 高 H ...
- MyBatis crud操作
Test2.java package com.mycom.mybatis_1.crud; import java.util.List; import org.apache.ibatis.session ...
- ubuntu 16.04 有道词典
依赖环境 sudo apt install \ python3-pyqt5 \ python3-requests \ python3-xlib \ python3-pil \ tesseract-oc ...
- xml转换之
1.XStream public static <T> T toBean(String xmlStr, Class<T> cls) { XStream xstream = ne ...
- 第六章 - 图像变换 - 图像拉伸、收缩、扭曲、旋转[2] - 透视变换(cvWarpPerspective)
透视变换(单应性?)能提供更大的灵活性,但是一个透视投影并不是线性变换,因此所采用的映射矩阵是3*3,且控点变为4个,其他方面与仿射变换完全类似,下面的例程是针对密集变换,稀疏图像变换则采用cvPer ...
- nodejs 的安全
1.connect中间件csrf 原理:在express框架中csrf 是通过connect 模块的中间件来解决的.其原理是在前端构造一个隐藏的表单域“_csrf” ,后端生成一个值,作为该表单域,然 ...
- 如何使Session永不过期
转载:http://blog.csdn.net/wygyhm/article/details/2819128 先说明情况:公司做监控系统,B/S结构,主要用在局域网内部!监控系统开机可能要开好长时间, ...
- Enclosure POJ
0:Enclosure http://poj.openjudge.cn/challenge3/0/ 查看 提交 统计 提问 总时间限制: 1000ms 内存限制: 131072kB 描述 为了防止 ...
- linux red hat 安装svn
安装步骤如下: 1.yum install subversion 2.输入rpm -ql subversion查看安装位置,如下图: 我们知道svn在bin目录下生成了几个二进制文件. 输入 ...