优化器,SGD+Momentum;Adagrad;RMSProp;Adam
Optimization
随机梯度下降(SGD):


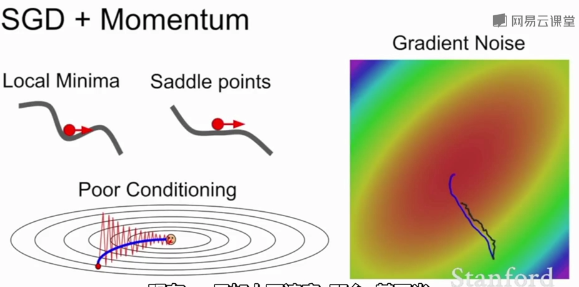
当损失函数在一个方向很敏感在另一个方向不敏感时,会产生上面的问题,红色的点以“Z”字形梯度下降,而不是以最短距离下降;这种情况在高维空间更加普遍。
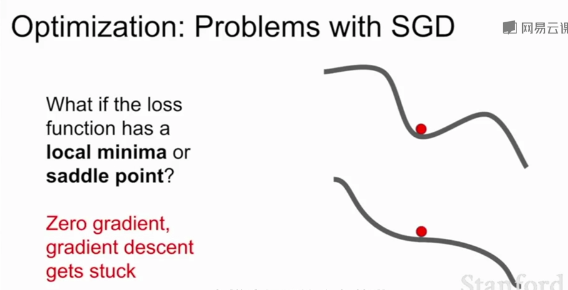
SGD的另一个问题:损失函数容易卡在局部最优或鞍点(梯度为0)不再更新。在高维空间鞍点更加普遍
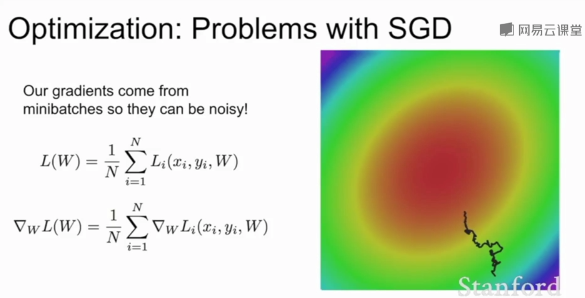
当模型较大时SGD耗费庞大计算量,添加随机均匀噪声时SGD需要花费大量的时间才能找到极小值。
SGD+Momentum:
带动量的SGD,基本思想是:保持一个不随时间变化的速度,并将梯度估计添加到这个速度上,在这个速度方向上前进,而不是随梯度变化方向,给一个摩擦系数作为这个速度的衰减项。

这种方法解决了局部极小值和鞍点问题,尽管在局部极小值和鞍点任会有朝预定速度方向步进,且速度会随着时间的速度增加。
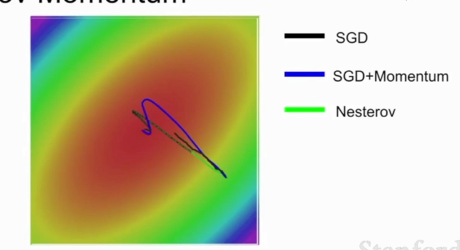
普通的Momentum更新是先估计当前梯度向量,取其和速度向量的和的方向作为真实参数更新的方向
Nesterov Momentum则相反,先取得速度方向的步进,再估计当前位置的梯度,随后回到原来位置,再根据两者的和作为真实参数更新的方向。在凸优化问题有良好表现


Nesterov Momentum不会剧烈的越过局部最小值
AdaGrad:
在优化过程中,需要保持一个在训练过程中的每一步的梯度的平方和的持续估计;与速度项不同,梯度平方项在训练时,会一直累加当前梯度的平方到这个梯度平方项,在更新参数向量时,会除以这个梯度平方项。

当一个维度上的梯度更新很小时会除以很小的平方项,梯度很大时则会除以很大的平方项;在一个维度上(梯度下降很慢的)训练会加快,在另一个维度方向上训练减慢;让各个参数得到相同程度的收敛。
随着时间的推移,梯度更新的步长会越来越小(梯度平方项随时间单调递增);在学习目标是一个凸函数的情况下,效果很好,到达极值点,步长越来越小最终收敛;非凸函数则会变得复杂
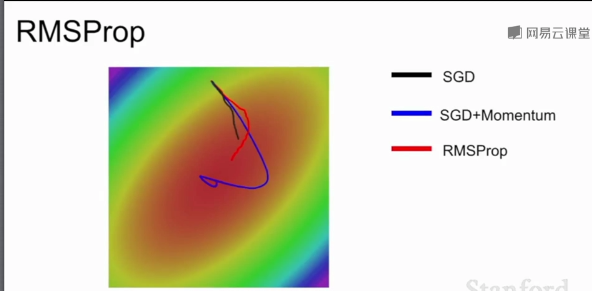
RMSProp:
不仅加上平方项,并让平方梯度按照一定比率下降,然后用1减去衰减了乘以梯度平方加上之前的结果。
随着训练的进行,步长会有一个良好的性质,与AdaGrad类似在一个维度上(梯度下降很慢的)训练会加快,在另一个维度方向上训练减慢,RMSProp让梯度平方衰减了,可能会造成训练一直在变慢。

RMSProp会慢慢调整梯度更新方向,SGD效果不好,SGD+Momentum会先绕过极小值再朝极小值方向前进,AdaGrad在较小学习率时可能会卡住。(凸优化问题)
Adam:
更新第一动量(类似SGD+Momentum中的速度)和第二动量(类似AdaGrad、RMSProp中的梯度的平方项)的估计值,第一动量的估计值等于梯度的加权和,第二动量的动态估计值是梯度平方的动态估计值,相当于速度项与梯度平方项的结合。

在最初的第一步,第二动量的初始值为0,第一步之后衰减值beta2=0.9或0.99,第二动量还是接近于0,除以第二动量后会得到很大的步长,可能导致初始化到一个难以收敛的区域。1e-7为的是分母不为0。
因此,Adam增加了一个偏置校正项避免出现开始时得到很大步长。

一般网络的都会使用Adam算法作为优化算法,它结合了SGD和RMSProp的优点。

学习率的选择:

一般选择学习率衰减策略,在训练的开始选择较大的学习率,然后随着步长衰减或指数衰减。

SGD+Momentum的学习率衰减很常见,Adam一般不使用学习率衰减,学习率衰减相当于二阶超参数,在开始时不使用,在训练达到一定瓶颈时再考虑使用。
一阶优化与二阶优化:




L-BFGS是一个二阶优化器

Adam是大多数情况下的默认选择,如果能承受整个批次的更新且没有很多随机性(如风格迁移),可以考虑L-BFGS
模型集成是提高测试集准确率的有效办法,通常选择一批不同的随机初始值上训练N个模型,测试时平均N个模型的结果,能够缓解过拟合。

Q1:随机梯度下降的随机指得是什么?
Q2:尝试解释为什么Adam通常会是一个更好的选择?(可以结合Momentum和RMSProb的优点解释)
1.随机梯度下降指的是从批量样本中随机选取一个样本,按照该样本梯度下降的方向进行梯度下降,
2.Adam的优点:可以解决局部最优和鞍点问题,且下降速度较快,平衡各特征梯度的大小
https://blog.csdn.net/weixin_40170902/article/details/80092628
优化器,SGD+Momentum;Adagrad;RMSProp;Adam的更多相关文章
- 深度学习笔记:优化方法总结(BGD,SGD,Momentum,AdaGrad,RMSProp,Adam)
深度学习笔记:优化方法总结(BGD,SGD,Momentum,AdaGrad,RMSProp,Adam) 深度学习笔记(一):logistic分类 深度学习笔记(二):简单神经网络,后向传播算法及实现 ...
- [DeeplearningAI笔记]改善深层神经网络_优化算法2.6_2.9Momentum/RMSprop/Adam优化算法
Optimization Algorithms优化算法 觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.6 动量梯度下降法(Momentum) 另一种成本函数优化算法,优化速度一般快于标准 ...
- 优化深度神经网络(二)优化算法 SGD Momentum RMSprop Adam
Coursera吴恩达<优化深度神经网络>课程笔记(2)-- 优化算法 深度机器学习中的batch的大小 深度机器学习中的batch的大小对学习效果有何影响? 1. Mini-batch ...
- 简单认识Adam优化器
转载地址 https://www.jianshu.com/p/aebcaf8af76e 基于随机梯度下降(SGD)的优化算法在科研和工程的很多领域里都是极其核心的.很多理论或工程问题都可以转化为对目标 ...
- Pytorch1.0深度学习:损失函数、优化器、常见激活函数、批归一化详解
不用相当的独立功夫,不论在哪个严重的问题上都不能找出真理:谁怕用功夫,谁就无法找到真理. —— 列宁 本文主要介绍损失函数.优化器.反向传播.链式求导法则.激活函数.批归一化. 1 经典损失函数 1. ...
- Tensorflow-各种优化器总结与比较
优化器总结 机器学习中,有很多优化方法来试图寻找模型的最优解.比如神经网络中可以采取最基本的梯度下降法. 梯度下降法(Gradient Descent) 梯度下降法是最基本的一类优化器,目前主要分为三 ...
- Tensorflow 2.0 深度学习实战 —— 详细介绍损失函数、优化器、激活函数、多层感知机的实现原理
前言 AI 人工智能包含了机器学习与深度学习,在前几篇文章曾经介绍过机器学习的基础知识,包括了监督学习和无监督学习,有兴趣的朋友可以阅读< Python 机器学习实战 >.而深度学习开始只 ...
- 优化器Optimizer
目前最流行的5种优化器:Momentum(动量优化).NAG(Nesterov梯度加速).AdaGrad.RMSProp.Adam,所有的优化算法都是在原始梯度下降算法的基础上增加惯性和环境感知因素进 ...
- 『PyTorch』第十一弹_torch.optim优化器
一.简化前馈网络LeNet import torch as t class LeNet(t.nn.Module): def __init__(self): super(LeNet, self).__i ...
- Pytorch torch.optim优化器个性化使用
一.简化前馈网络LeNet 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 im ...
随机推荐
- HDU-1024_Max Sum Plus Plus
Max Sum Plus Plus Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) P ...
- Request中getContextPath、getServletPath、getRequestURI、request.getRealPath的区别
1 区别 假定你的web application 名称为news,你在浏览器中输入请求路径: http://localhost:8080/news/main/list.jsp 1.1 System.o ...
- async/await运用-前端表单弹窗验证同步书写方式(React)
在前端项目中,我们经常会碰到这样的场景: 当前我们有一个表单需要填写,在完成表单填写后经过校验之后会弹出短信或者其他形式验证码,进行补充校验,然后一起提交给接口. 场景如下图: 当前为创建操作,编辑操 ...
- 利用伪类选择器与better-scroll的on事件所完成的上拉加载
之前给大家分享过一篇上拉加载 利用了better-scroll的pullUpDown 和DOM元素的删除添加 感觉那样不太好 今天给大家分享一个不同的上拉加载思想 代码如下 class List { ...
- linux 一些简单操作
vim ----三种模式 1.命令模式 2.输出模式 3.底线命令模式 w(e) 移动光标到下一个单词 b 移动到光标上一个单词 数字0 移动到本行开头 $ 移动光 ...
- SuperSocket SuperWebSocket并发数100限制的问题
var wsSer = new WebSocketServer(); wsSer.NewMessageReceived += wsSer_NewMessageReceived;//有消息传入时事件 w ...
- [C#] ServiceStack.Redis如何批量的pop数据?
要安全的批量pop数据,有两个办法: 1.用事务(不用事务的话可能导致重复读.ServiceStack的pipeline是没有自带事务的.) 2.执行lua脚本 我这里提供用事务的实现方法: publ ...
- 【原生JS】动态分页样式效果
效果图如下: html: <body> <div> <table id="btnbox"> <tbody> <tr>&l ...
- Java RandomAccessFile用法(转载)
RandomAccessFile RandomAccessFile是用来访问那些保存数据记录的文件的,你就可以用seek( )方法来访问记录,并进行读写了.这些记录的大小不必相同:但是其大小和位置必须 ...
- 蝶式套利(butterfly spread)
多头蝶式套利.预期市场价格趋于稳定,希望在这个价格区间内能获利,可选用多头蝶式套利,以较低的议定价格买进一个看涨期权,又以较高的议定价格买进一个看涨期权,同时又以介于上述2个议定价格之间的中等的议定价 ...