urllib的高级用法
Handler简介
我们可以把他理解为各种处理器,有专门处理登录验证的,有处理cookies的,有处理代理设置的。利用他们,我们几乎可以做到HTTP请求中的所有事情。
首先,介绍一下 urllib.request模块里的 BaseHandler 类,它是所有其他 Handler 的父类,它提供了最基本的方法,例如 default_open ()、 protocol_request ()等。
接下来,就有各种Handler子类继承这个BaseHandler类,举例如下。
HTTPDefaultErrorHandler: 用于处理HTTPError类型的异常。
HTTPRedirectHandler:用于处理重定向。
HTTPCookiesProcessor:用于处理cookies。
ProxyHandler:用于设置代理,默认代理为空。
HTTPpasswordMgr:用于管理密码,它维护了用户名和密码的表。
HTTPBasicAuthHandler:用于管理认证,如果一个了解打开时需要认证,那么可以用它来解决认证问题。
另外,还有其他的Handler类,这里就不一一举例了,详情可以参考官方文档:https://docs.python.org/3/library/urllib.request.html#urllib.request.BaseHandler.
关于怎么使用它们,现在先不用着急,后面会有实例演示 。
另一个比较重要的类就是 Op enerDirector ,我们可以称为 Opener 。 我们之前用过 urlopen ()这个
方法,实际上它就是 urllib 为我们提供的一个 Opener 。
那么,为什么要引人 Opener 呢?因为需要实现更高级的功能 。 之前使用的 Request 和 urlopen( )
相当于类库为你封装好了极其常用的请求方法,利用它们可以完成基本的请求,但是现在不一样了,
我们需要实现更高级的功能,所以需要深入一层进行配置,使用更底层的实例来完成操作,所以这里
就用到了 Opener 。
Opener 可以使用 open ()方法,返回的类型和 urlopen ()如出 一辙 。 那么,它和 Handler 有什么关
系呢?简而言之,就是利用 Handler 来构建 Opener 。
下面用几个实例来看看它们的用法 。
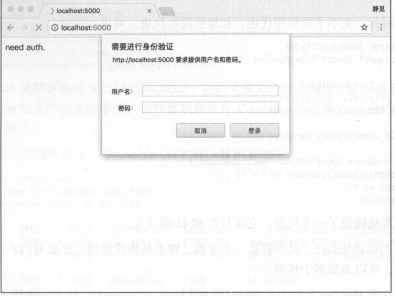
那么,如果要请求这样的页面,该怎么办呢?借助 HTTPBasicAuthHandler 就可以完成,相关代码
如下:
from urllib.request import HTTPPasswordMgrWithDefaultRealm, HTTPBasicAuthHandler, build_opener
from urllib.error import URLError
username = username
password =’ password ’
url = ’ http: //localhost:sooo/'
p = HTTPPasswordMgrWithDefaultRealm()
p.add_password(None, url, username , password)
auth_handler = HTTPBasicAuthHandler(p)
opener = build_opener(auth_handler) try:
result = opener.open(url)
html = result. read(). decode (’ utf 8 ’)
print(html)
except URLError as e:
print(e.reason)
这里首先实例化 HTTPBasicAuthHandler 对象,其参数是 HTTPPasswordMgrWithDefaultRealm 对象,
它利用 add_password ()添加进去用户名和密码,这样就建立了一个处理验证的 Handler.
接下来,利用这个 Handler 并使用 build_opener ()方法构建一个 Opener ,这个 Opener 在发送请求
时就相当于已经验证成功了 。
接下来,利用 Opener 的 open ()方法打开链接,就可以完成验证了 。 这里获取到的结果就是验证
后的页面源码内容 。
#·代理
#在做爬虫的时候,免不了要使用代理,如果要添加代理,可以这样做:
from urllib.error import URLError
from urllib.request import ProxyHandler, build opener
proxy _handler = ProxyHandler({
'http':’ http://127.0.0.1:9743',
'https':'https://127.0 .0.1:9743'
})
opener = build_opener(proxy_handler)
try:
response = opener.open (’ https://www.baidu.com')
print(response.read() .decode (’ utf-8'))
except URLError as e:
print(e.reason)
这里我们在本地搭建了一个代理,它运行在 9743 端口上 。
这里使用了 ProxyHand l er ,其参数是一个字典,键名是协议类型(比如 HTTP 或者 HTTPS 等),
键值是代理链接,可以添加多个代理。
然后,利用这个 Handler 及 build_opener ()方法构造一个 Opener ,之后发送请求即可 。
•
Cookies
Cookies 的处理就需要相关的 Handler 了 。
我们先用实例来看看怎样将网站的 Cookies 获取下来,相关代码如下:
import http .cookiejar, urllib.request
cookie = http. cookie jar. CookieJar()
handler = urllib . request.HTTPCookieProcessor (cookie)
opener = urllib.request . build opener(handler )
response = opener. open (’ http://www.baidu.com')
for item in cookie:
print(item.name +”= ”+ i tem.value)
首先 ,我们必须声 明一个 CookieJar 对象 。 接下来,就需要利用 HTTPCookieProcessor 来构建一个
Handler ,最后利用 build_opener ()方法构建出 Opener ,执行 open () 函数即可 。
BAIDUID=2E6SA683F8A8BA3DF521469DF8EFF1E1 :FG=1
BIDUPSID=2E6SA683F8A8BA3DF521469DF8EFF1E1
H PS PSSID=20987 1421 18282 17949 21122 17001 21227 21189 21161 20927
PST问= 1474900615
BDSVRTM=O
BD HOME=O
可以看到,这里输州了每条 Cookie 的名称和值 。
不过既然能输出,那可不可以输出成文件格式呢?我们知道 Cookies 实际上也是以文本形式保存
的。
答案当然是肯定的,这里通过下面 的实例来看看:
filename = 'cookies. txt ’
cookie = http.cookiejar.MozillaCookieJar(filename)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open (’ http://www .baidu.com')
cookie.save(ignore_discard=True , ignore_expires=True)
这时 CookieJar 就需要换成问ozillaCookieJar ,它在生成文件时会用到,是 CookieJar 的子类,可
以用来处理 Cookies 和文件相关的事件,比如读取和保存 Cookies ,可以将 Cookies 保存成 Mozilla 型
浏览器的 Cookies 格式 。
运行之后,可 以发现生成了一个 cookies.txt 文件,其内容如下:

另外, LWPCookieJar 同样可以读取和保存 Cookies ,但是保存的格式和 MozillaCookieJar 不一样,
它会保存成 libwww-perl(LWP)格式的 Cookies 文件 。
要保存成 LWP 格式的 Cookies 文件,可以在声明时就改为:
cookie = http. cookiejar. LWPCookieJar (filename)
此时生成的内容如下:
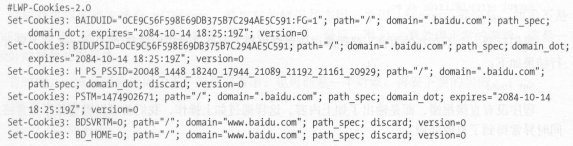
由此看来,生成的格式还是有比较大差异的 。
那么,生成了 Cookies 文件后,怎样从文件中读取并利用呢?
下面我们以 LWPCookieJar 格式为例来看一下:

可以看到,这里调用 load ()方法来读取本地的 Cookies 文件,获取到了 Cookies 的内容 。 不过前
提是我们首先生成了 LWPCooki eJar 格式的 Cookies ,并保存成文件,然后读取 Cookies 之后使用同样
的方法构建 Handler 和l Opener 即可完成操作 。
运行结果正常的话,会输出百度网页的源代码 。
通过上面的方法,我们可以实现绝大多数请求功能的设置了 。
这便是 urllib 库中 request 模块的基本用法,如果想实现更多的功能,可以参考官方文档的说明:
https ://docs. p ython.org/3/library/urllib . request.html#basehandler-objects 。
urllib的高级用法的更多相关文章
- Python爬虫入门之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- Python爬虫Urllib库的高级用法
Python爬虫Urllib库的高级用法 设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Head ...
- Python爬虫入门四之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- 转 Python爬虫入门四之Urllib库的高级用法
静觅 » Python爬虫入门四之Urllib库的高级用法 1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我 ...
- 爬虫 requests模块高级用法
一 介绍 #介绍:使用requests可以模拟浏览器的请求,比起之前用到的urllib,requests模块的api更加便捷(本质就是封装了urllib3) #注意:requests库发送请求将网页内 ...
- Visual Studio 宏的高级用法
因为自 Visual Studio 2012 开始,微软已经取消了对宏的支持,所以本篇文章所述内容只适用于 Visual Studio 2010 或更早期版本的 VS. 在上一篇中,我已经介绍了如何编 ...
- SolrNet高级用法(分页、Facet查询、任意分组)
前言 如果你在系统中用到了Solr的话,那么肯定会碰到从Solr中反推数据的需求,基于数据库数据生产索引后,那么Solr索引的数据相对准确,在电商需求中经常会碰到菜单.导航分类(比如电脑.PC的话会有 ...
- sqlalchemy(二)高级用法
sqlalchemy(二)高级用法 本文将介绍sqlalchemy的高级用法. 外键以及relationship 首先创建数据库,在这里一个user对应多个address,因此需要在address上增 ...
- Solr学习总结(六)SolrNet的高级用法(复杂查询,分页,高亮,Facet查询)
上一篇,讲到了SolrNet的基本用法及CURD,这个算是SolrNet 的入门知识介绍吧,昨天写完之后,有朋友评论说,这些感觉都被写烂了.没错,这些基本的用法,在网上百度,资料肯定一大堆,有一些写的 ...
随机推荐
- 【转】Wireshark技巧-过滤规则和显示规则
原文: http://www.cnblogs.com/icez/p/3973873.html ----------------------------------------------------- ...
- Oracle APEX 4.2安装和配置
A standard Oracle 11.2.0.3 database installation comes bundled with Application Express (APEX) 3.2.1 ...
- MySQL InnoDB类型数据库的恢复
MySQL的数据库文件直接复制便可以使用,但是那是指“MyISAM”类型的表. 而使用MySQL-Front直接创建表,默认是“InnoDB”类型,这种类型的一个表在磁盘上只对应一个“*.frm”文 ...
- 初探active mq
mq(message queue),即消息队列,目前比较流行消息队列是active mq 和kafka.本文介绍如何简单的使用active mq. ActiveMQ官网下载地址:http://acti ...
- (八)Java 修饰符
Java 修饰符 Java语言提供了很多修饰符,主要分为以下两类: 访问修饰符 非访问修饰符 修饰符用来定义类.方法或者变量,通常放在语句的最前端.我们通过下面的例子来说明: public class ...
- C语言进入界面编程准备篇
Win视窗编程和DOS下编程不同,但是类似.Windows应用程序也有它的入口函数,DOS程序中的入口函数是main函数,Windows程序的入口函数是WinMain函数.新建Win32 Applic ...
- CXF 中自定义SOAPHeader
Interceptor是CXF架构中一个很有特色的模式.你可以在不对核心模块进行修改的情况下,动态添加很多功能.这对于CXF这个以处理消息为中心的服务框架来说是非常有用的,CXF通过在Intercep ...
- Chart.js docs
原文链接:http://www.bootcss.com/p/chart.js/docs/ 引入Chart.js文件 首先我们需要在页面中引入Chart.js文件.此工具库在全局命名空间中定义了Char ...
- next数组求最小循环节
1.kmp产生的next数组: 最小循环节(长度)=len-next[len]; 证明: ----------------------- ----------------------- k m ...
- 四.OC基础--1.文档安装和方法重载,2.self和super&static,3.继承和派生,4.实例变量修饰符 ,5.私有变量&私有方法,6.description方法
四.OC基础--1.文档安装和方法重载, 1. 在线安装 xcode-> 系统偏好设置->DownLoads->Doucument->下载 2. 离线安装 百度xcode文档 ...