腾讯云+阿里云 搭建hadoop + hbase
历时两天,踩了无数坑最后搭建成功。。。
准备
服务器配置
以下1-3步骤中两台服务器都要配置
1、修改hostname
主节点修改成master
从节点修改成slave1
使用命令:vim /etc/hostname
master
# or slave1
重启服务器:reboot
2、修改服务器hosts
假如主节点是阿里云。则在阿里配置
命令: vi /etc/hosts
ip master
ip1 slave1
其中 ip=阿里的内网ip;ip1=腾讯的外网ip
在腾讯配置
ip master
ip1 slave1
其中 ip=阿里的外网ip;ip1=腾讯的内网ip。
3、安装jdk1.8,并配置环境变量
4、ssh配置(master主机)
输入命令生成密匙对
ssh-keygen -t rsa
一路回车
上述命令将在/root/.ssh目录下生成公钥文件id_rsa.pub。将此文件拷贝到.ssh目录下的authorized_keys:
cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
使用ssh登录本机

将公钥复制到从节点
ssh-copy-id -i ~/.ssh/id_rsa.pub root@slave1
可能需要输入从节点密码。
完成后确保从master免密码登录到slave1

对服务的配置就完成了,接下了配置hadoop。
hadoop
在master构建好hadoop,然后利用ssh分发到slave。所以下面配置在master进行
在home创建hadoop目录和配置文件路径
cd /home/
mkdir hadoop
cd hadoop
mkdir hadoop_data
cd hadoop_data
mkdir tmp
mkdir hdfs
cd hdfs
mkdir data
mkdir name
1、下载并解压:
可以使用wget下载或者上传都可以。
tar zxvf hadoop-2.7.3.tar.gz -C /home/hadoop/
2、 配置hadoop
hadoop配置文件路径 /home/hadoop/hadoop-2.7.3/etc/hadoop
hadoop-env.sh
修改JAVA_HOME。jdk路径
vi /home/hadoop/hadoop-2.7.3/etc/hadoop/hadoop-env.xml
export JAVA_HOME=/usr/local/jdk1.8.0_171
core-site.xml
vi /home/hadoop/hadoop-2.7.3/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/hadoop_data/tmp</value>
<description>Abasefor other temporary directories.</description>
</property>
</configuration>
hdfs-site.xml
vi /home/hadoop/hadoop-2.7.3/etc/hadoop/hdfs-site.xml
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
<description>备份namenode的http地址</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hjh/hadoop_data/hdfs/name</value>
<description>namenode的目录位置</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hjh/hadoop_data/hdfs/data</value>
<description>datanode's address</description>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>hdfs系统的副本数量</description>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
yarn-site.xml
vi /home/hadoop/hadoop-2.7.3/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
mapred-site.xml
vi /home/hadoop/hadoop-2.7.3/etc/hadoop/mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>指明mapreduce的调度框架为yarn</description>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
<description>指明mapreduce的作业历史地址</description>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
<description>指明mapreduce的作业历史web地址</description>
</property>
salve
vi /home/hadoop/hadoop-2.7.3/etc/hadoop/salve
master
slave1
该文件指定datanode从节点所在的服务器ip,这里只有两台服务器,所以将主节点master也加上去)
配置环境变量(方便后续操作)
vim /etc/profile
export HADOOP_HOME=/home/hadoop/hadoop-2.7.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin . source /etc/profile
最后copy这个hadoop给slave1
scp -r /home/hadoop/hadoop-2.7.3 root@slave1:/home/hadoop/
启动hadoop
以下在master进行
1、先格式化namenode
hadoop namenode -format
2、启动hadoop
./start-all.sh
执行:jps,查看相关进程
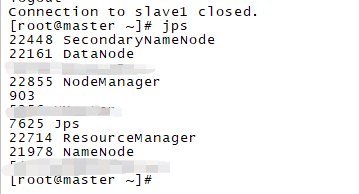
在slave1执行jps,
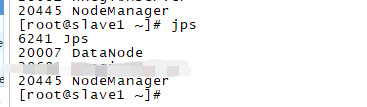
如果相关进程没有启动则去查看logs对应的模块的日志。准备埋坑。
在hdfs创建目录试试:
在master
hdfs dfs -ls /
hdfs是空的没有返回任何东西。
创建目录test
hdfs dfs -mkdir /test
hdfs dfs -ls /

在slave1中同样可以看到test

至此hadoop搭建完成。
hbase
在master构建,然后分发到slave
1、下载并解压:
可以使用wget下载或者上传都可以。
tar zxvf hbase-1.2.4.tar.gz -C /home/hadoop/
2、 配置hbase
hbase配置文件路径 /home/hadoop/hbase-1.2.4/conf
复制hadoop的hdfs-site.xml和core-site.xml到conf
cp -u /home/hadoop/hadoop-2.7.3/etc/hadoop/hdfs-site.xml /home/hadoop/hbase-1.2.4/conf
cp -u /home/hadoop/hadoop-2.7.3/etc/hadoop/core-site.xml /home/hadoop/hbase-1.2.4/conf
hbase-env.sh
vi /home/hadoop/hbase-1.2.4/conf/hbase-env.sh
由于使用jdk1.8 将如下注释

#配置jdk环境
export JAVA_HOME=/usr/local/jdk1.8.0_171
#配置zookeeper,true则说明使用hbase内置的zookeeper,false则说明使用单独的zookeeper集群
export HBASE_MANAGES_ZK=true
hbase-site.xml
vi /home/hadoop/hbase-1.2.4/conf/hbase-site.xml
<!--这是regionServer的共享目录,用来持久化hbase的,端口默认9000-->
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
</property>
<!--hbase的运行模式,false是单机模式,true是分布式模式;
若设置为false,hbase和zookeeper会运行在同一个JVM里面-->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!--hbase主节点的端口,默认60000-->
<property>
<name>hbase.master</name>
<value>master:60000</value>
</property>
<!--zookeeper集群的地址列表,用逗号分割,默认localhost,这里的机器太少所以只用了一个zookeeper。否则会出错-->
<property>
<name>hbase.zookeeper.quorum</name>
<value>master</value>
</property>
regionservers
vi /home/hadoop/hbase-1.2.4/conf/regionservers
master
slave1
最后分发个slave1
scp -r /home/hadoop/hbase-1.2.4 root@slave1:/home/hadoop/
在master 启动hbase
在hbase/bin 下启动hbase
./start-hbase.sh
master运行jps查看相关进程
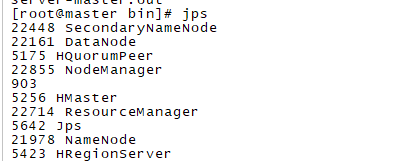
slave1
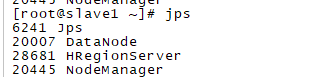
出错看logs查看那个模块出问题。
运行hbase shell
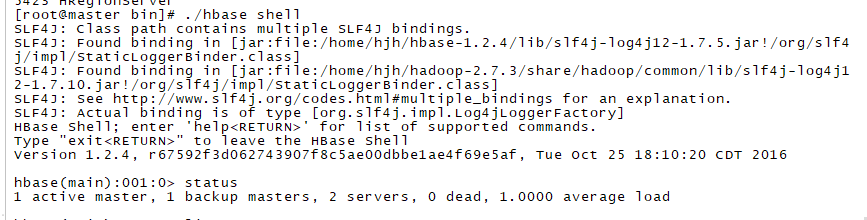
整个hadoop + hbase 就搭建好了
JAVA测试
/**
* @Description:
* @Author: HJH
* @Date: 2019-09-04 17:06
*/
public class HBaseConn {
private static final HBaseConn INSTANCE = new HBaseConn();
private static Configuration configuration;
private static Connection connection;
private HBaseConn() {
try {
if (configuration == null) {
configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum", "ip"); //master ip
System.setProperty("hadoop.home.dir", "E:\\hadoop-2.7.3");
configuration.set("hbase.zookeeper.property.clientPort","2181"); //端口号
}
} catch (Exception e) {
e.printStackTrace();
}
}
private Connection getConnection() {
if (connection == null || connection.isClosed()) {
try {
connection = ConnectionFactory.createConnection(configuration);
} catch (Exception e) {
e.printStackTrace();
}
}
return connection;
}
public static Connection getHBaseConn() {
return INSTANCE.getConnection();
}
public static Table getTable(String tableName) throws IOException {
return INSTANCE.getConnection().getTable(TableName.valueOf(tableName));
}
public static void closeConn() {
if (connection != null) {
try {
connection.close();
} catch (IOException ioe) {
ioe.printStackTrace();
}
}
}
}
public class HBaseUtil {
public static void main(String[] args) {
createTable("FileTable", new String[]{"fileInfo", "saveInfo"});
}
/**
* 创建TABLE
* @param tableName 表名
* @param cfs 列族
* @return 是否创建成功
*/
public static boolean createTable(String tableName, String[] cfs) {
try (HBaseAdmin admin = (HBaseAdmin) HBaseConn.getHBaseConn().getAdmin()) {
if (admin.tableExists(tableName)) {
return false;
}
HTableDescriptor tableDescriptor = new HTableDescriptor(TableName.valueOf(tableName));
Arrays.stream(cfs).forEach(cf -> {
HColumnDescriptor columnDescriptor = new HColumnDescriptor(cf);
columnDescriptor.setMaxVersions(1);
tableDescriptor.addFamily(columnDescriptor);
});
admin.createTable(tableDescriptor);
} catch (Exception e) {
e.printStackTrace();
}
return true;
}
创建成功

腾讯云+阿里云 搭建hadoop + hbase的更多相关文章
- 在腾讯云&阿里云上部署JavaWeb项目(Tomcat+MySQL)
之前做项目都是在本地跑,最近遇到需要在在云服务器(阿里云或者腾讯云都可以,差不多)上部署Java Web项目的问题,一路上遇到了好多坑,在成功部署上去之后写一下部署的步骤与过程,一是帮助自己总结记忆, ...
- Ant Design Upload 组件上传文件到云服务器 - 七牛云、腾讯云和阿里云的分别实现
在前端项目中经常遇到上传文件的需求,ant design 作为 react 的前端框架,提供的 upload 组件为上传文件提供了很大的方便,官方提供的各种形式的上传基本上可以覆盖大多数的场景,但是对 ...
- 腾讯云/阿里云/微软云安装ISO镜像系统方法
如今云服务的盛行,我们的开发和应用中场景应用也层出不穷,有时我们需要安装自由的镜像却越来越难,甚至有些云出于安全原因自己用户安装自由镜像,那么今天将带给大家安装自有镜像的方法. 前提条件:你的现有服务 ...
- 跨域请求配置 Amazon AWS S3 腾讯云 阿里云 COS OSS 文件桶解决方案以及推荐 Lebal:Research
跨域请求配置 跨域请求指的就是不同的域名和端口之间的访问.由于 ajax 的同源策略影响.跨域请求默认是不被允许的. 使用@font-face外挂字体时,可能遇到跨域请求CROS问题:F12控制台报错 ...
- CentOS7搭建 Hadoop + HBase + Zookeeper集群
摘要: 本文主要介绍搭建Hadoop.HBase.Zookeeper集群环境的搭建 一.基础环境准备 1.下载安装包(均使用当前最新的稳定版本,截止至2017年05月24日) 1)jdk-8u131 ...
- 腾讯云和阿里云部署web 项目tomcat 日志 中文变成问号
在部署项目到云上的时候,遇到了tomcat logs 日志中文变问号的问题,今天终于得到解决了 这是中文变成问号的的截图 打开到tomcat bin 目录的文件夹 找到catalina.sh 文件 ...
- 大数据平台搭建-hadoop/hbase集群的搭建
版本要求 java 版本:1.8.*(1.8.0_60) 下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downl ...
- 云-阿里云-OSS:对象存储 OSS
ylbtech-云-阿里云-OSS:对象存储 OSS 对象存储服务(Object Storage Service,OSS)是一种海量.安全.低成本.高可靠的云存储服务,适合存放任意类型的文件.容量和处 ...
- 【经验】基于阿里云 Ubuntu 的 LAMP 网站搭建及配置完全教程
本文同步发表在负雪明烛的博客:https://fuxuemingzhu.cn/2016/03/02/My-Aliyun-Server-Setting/ 起因 最近老师让我做一个众筹系统,可以在微信公众 ...
随机推荐
- ROS参数服务器(Parameter Server)
操作演示,对参数服务器的理解:点击打开链接 rosparam使得我们能够存储并操作ROS 参数服务器(Parameter Server)上的数据.参数服务器能够存储整型.浮点.布尔.字符串.字典和列表 ...
- 1823:【00NOIP提高组】方格取数
#include<bits/stdc++.h> using namespace std; ][]; ][][][]; inline int max(int x,int y) { retur ...
- LayUI使用弹窗重载父级数据表格的两种方法
参考LayUI官方文档,在子窗口中重载父级数据表格找到以下两种方法: 1.子窗口中重载:在子窗口中直接调用父级talbe的reload方法. $("body").on(" ...
- arcgis python 获得打印机
class ToolValidator: """Class for validating a tool's parameter values and controllin ...
- laravel中打印一个sql语句
查询构造器 打印sql是发现 toSql() 不可用 所以网上搜索下 //DB::connection()->enableQueryLog(); // 开启查询日志 $user=DB::tabl ...
- Hallelujah Leonard Cohen
Hallelujah 歌词 Leonard Cohen Now I've heard there was a secret chord 我听说有一个隐秘的弦音 That David ...
- ajax 提交 form表单 ,后台执行两次的问题
网上大多的答案是说同步不同步的问题,但是我把异步改成同步也不行.async: false, // 单击时表单检查 $('.btn-next a').click(function () { if ...
- java模拟post进行文件提交 采用httpClient方法
package com.jd.vd.manage.util.filemultipart; import java.io.BufferedReader;import java.io.File;impor ...
- Leetcode: Longest Palindromic Substring && Summary: Palindrome
Given a string s, find the longest palindromic substring in s. You may assume that the maximum lengt ...
- IfcAxis2Placement3D IFC构件的位置和方向
IfcAxis2Placement3D定义了三维空间中物体的位置和方向,由三部分组成: The attribute Axis defines the Z direction, RefDirection ...