centOS7搭建hadoop,zookeeper,hbase
1、配置ssh免密登录
(本人使用的是centOS7虚拟机)
(本人未在root用户下安装,建议使用root用户,不然很麻烦!!)
① 本机无密钥登录
1.进入~/.ssh目录(若无,则执行一次ssh localhost),
2.执行ssh-keygen -t rsa命令(回车即可),

我弄过了所以已经有啦!
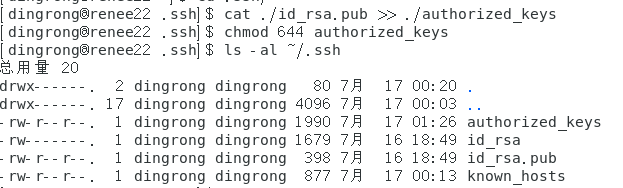
3.再执行cat ./id_rsa.pub >> ./authorized_keys命令,把id_rsa.pub追加到授权的key里面,
4.给authorized_keys授权chmod 644 authorized_keys, ls -al ~/.ssh命令看权限,
5.重启 sudo service sshd restart,

6.连接 ssh localhost(yes/no,手动输入yes)
7.退出 exit
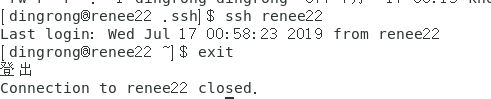
我这里主机名为renee22,用户名为dingrong
② 与其他机子的无密钥登录
1.其他机子一样执行①中1、2,
2.本机把authorized_keys分发到其他机子上(会提示输入密码,输入密码即可),scp ./authorized_keys username(用户名)@(ip地址/主机名):/root/.ssh (目录根据自己机子来)

我这里另一个机子的主机名为renee13,用户名为dingr
3.在其他机子上执行①中步骤4授权
4.尝试连接其他机子,ssh 用户名@ip地址/域名

③ 若有错误
1.进入/etc/ssh/sshd_config文件,

RSAAuthentication yes
PubkeyAuthentication yes
这两个注释去掉

2.authorized_keys文件权限问题,记得授权
3.本机能不能访问22端口,命令lsof -i:22

4.分发authorized_keys时,注意用户名和主机名要对应上,不然密码输入会错误。
④主机直接域名通信(需要通信的主机都要改)
ifconfig查看ip

在虚拟机的菜单-编辑->虚拟网络编辑器中能看到gateway

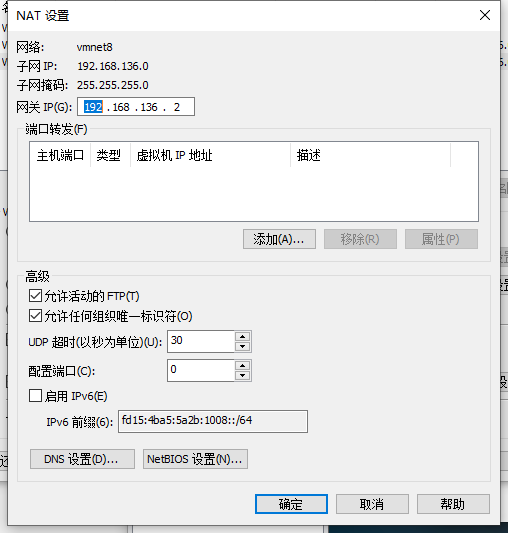
编辑配置文件,sudo vim /etc/sysconfig/network-scripts/ifcfg-ens33,将ip信息添加进去


我这里主机ip为192.168.136.133,另一个是192.168.136.130
ping一下,看看能不能通(如果不通,检查一下防火墙有没有关)

设置dns就可以域名通信了
进入到配置文件中sudo vim /etc/resolv.conf


修改hostname主机名
hostnamectl set-hostname 主机名 #修改三种主机名
hostnamectl –static set-hostname 主机名 #只会修改static主机名
修改配置文件,sudo vim /etc/hosts(每个主机都要改)

ping 主机名

2、安装jdk(两个机子都要装)
先删除centos7自带的openjdk
①rpm -qa | grep java
②rpm -e --nodeps Openjdk
(我装的是jdk1.8.0_221)
jdk下载地址
需要登录哦!!!
1.下载完成后解压到/usr/local/java目录下(没有java目录就创建)
tar -xzvf jdk-8u221-linux-x64.tar.gz
2.配置环境变量
sudo vim /etc/profile
JAVA_HOME=/usr/local/java/jdk1.8.0_221
JRE_HOME=$JAVA_HOME/jre
CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export JAVA_HOME JRE_HOME CLASS_PATH PATH
source /etc/profile(使文件生效)
3.验证
java -version
3、安装hadoop
1.同样解压,我设的目录是/usr/local/hadoop
2.配置环境变量
sudo vim /etc/profile
JAVA_HOME=/usr/local/java/jdk1.8.0_221
JRE_HOME=$JAVA_HOME/jre
CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.7
HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export JAVA_HOME JRE_HOME CLASS_PATH HADOOP_HOME HADOOP_COMMON_LIB_NATIVE_DIR PATH
source /etc/profile(使文件生效)
在上面jdk环境变量下添加就好。
3.修改hadoop的配置文件
进入到/usr/local/hadoop/hadoop-2.7.7/etc/hadoop/目录下,在hadoop-env.sh和yarn-env.sh两个文件中添加JAVA_HOME
cd /usr/local/hadoop/hadoop-2.7.7/etc/hadoop
sudo vim hadoop-env.sh
export JAVA_HOME=/usr/local/java/jdk1.8.0_221
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.7
export HDFS_NAMENODE_USER=dingrong
export HDFS_DATANODE_USER=dingrong
export HDFS_SECONDARYNAMENODE_USER=dingrong
export YARN_RESOURCEMANAGER_USER=dingrong
export YARN_NODEMANAGER_USER=dingrong
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib/native"(更改hadoop_opts)
source hadoop-env.sh(使文件生效)
sudo vim yarn-env.sh
# export JAVA_HOME=/home/y/libexec/jdk1.6.0/
export JAVA_HOME=/usr/local/java/jdk1.8.0_221
source yarn-env.sh
另外还有四个site.xml的文件需要配置
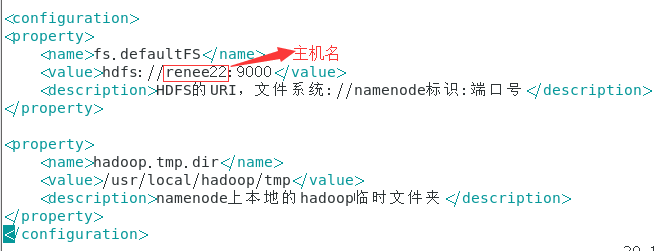
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://renee22:9000</value>
<description>HDFS的URI,文件系统://namenode标识:端口号</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
<description>namenode上本地的hadoop临时文件夹</description>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>副本个数,配置默认是3,应小于datanode机器数量</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/dfs/data</value>
</property>
</configuration>

yarn-site.xml
先执行 hadoop classpath命令,并复制返回的地址


mapred-site.xml

slaves文件中添加你的主机和节点
4.将hadoop分发到其他节点,用scp命令

5.格式化namenode
进入hadoop-2.7.7下的sbin目录下执行 命令
hdfs namenode -format

如果格式化错误为
ERROR namenode.NameNode: java.io.IOException: Cannot create directory /export/home/dfs/name/current
ERROR namenode.NameNode: java.io.IOException: Cannot remove current directory: /usr/local/hadoop/hdfsconf/name/current
执行命令
sudo chmod -R a+w /usr/local/hadoop

6.启动hadoop
执行这两个命令
./start-dfs.sh
./start-yarn.sh
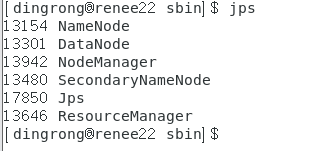
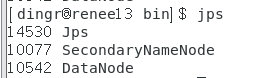
7.jps查看
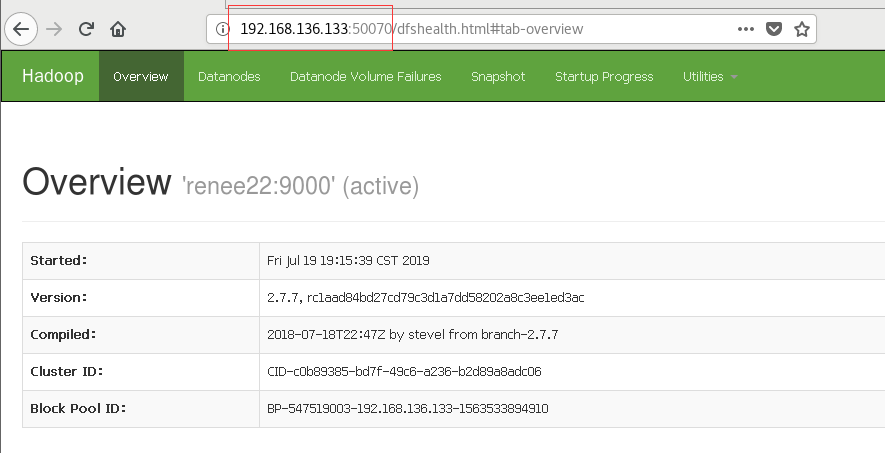
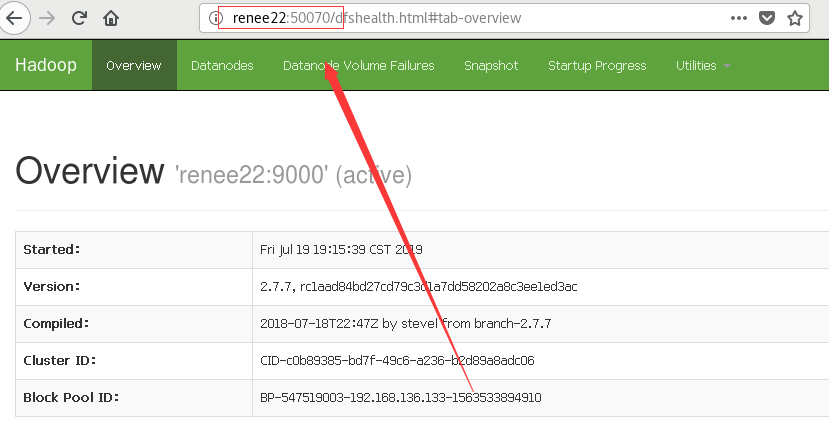
8.访问浏览器
http://192.168.136.133:50070或者http://renee22:50070( 这个在两个虚拟机也就是两个节点上都能访问!)
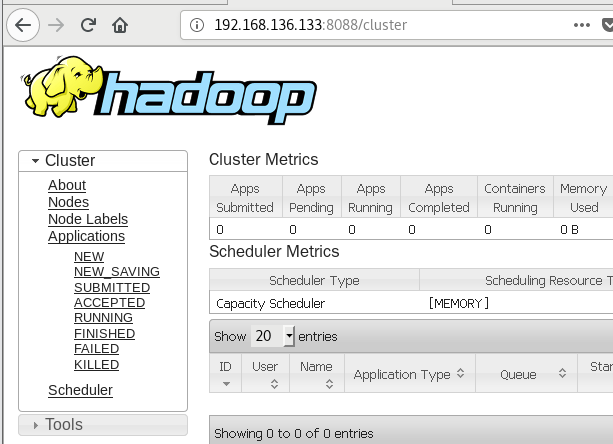
9.访问集群所有应用程序默认8088
4、安装zookeeper(主从节点都要)
1.同上步骤解压到/usr/local/zookeeper下
2.进入到目录conf下,执行cp zoo_sample.cfg zoo.cfg命令,复制 zoo_sample.cfg 到 zoo.cfg文件中

3.编辑zoo.cfg文件sudo vim zoo.cfg

4.进入到目录data下,创建myid文件并添加1(在dingrong@renee22中【换成自己的】),2(在dingr@renee13中)

5.编辑配置文件/etc/profile
ZOOKEEPER_HOME=/usr/local/zookeeper/zookeeper-3.4.14

6.进入到bin目录下,执行 ./zkServer.sh start,启动zk服务
【注】:要两台都启动,可查看zookeeper.out日志文件查看错误
查看zookeeper状态,一个是leader,一个是follewer


5、安装hbase
1.解压到/usr/local/hbase目录下
2.修改配置文件 ,到conf目录下
hbase-env.sh


hbase-site.xml
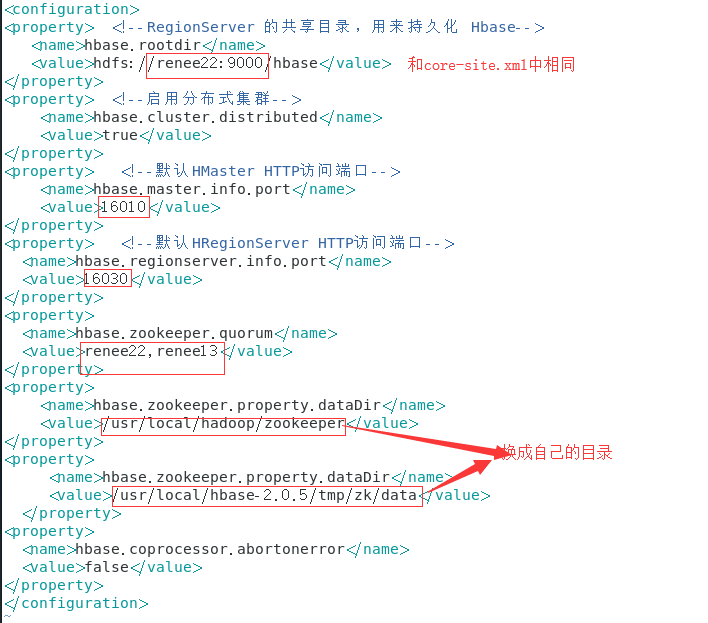
regionservers

/etc/profile
HBASE_HOME=/usr/local/hbase/hbase-2.0.5

(记得source生效)
3.scp拷到另一节点
dingrong@renee22执行
scp -r /usr/local/hbase dingr@renee13:/home/dingr
dingr@renee13执行
mv ~/hbase /usr/local/
【注】:root用户可直接拷贝至/usr/local/目录下,非root用户可先拷贝至home目录在移动
4.启动hbase
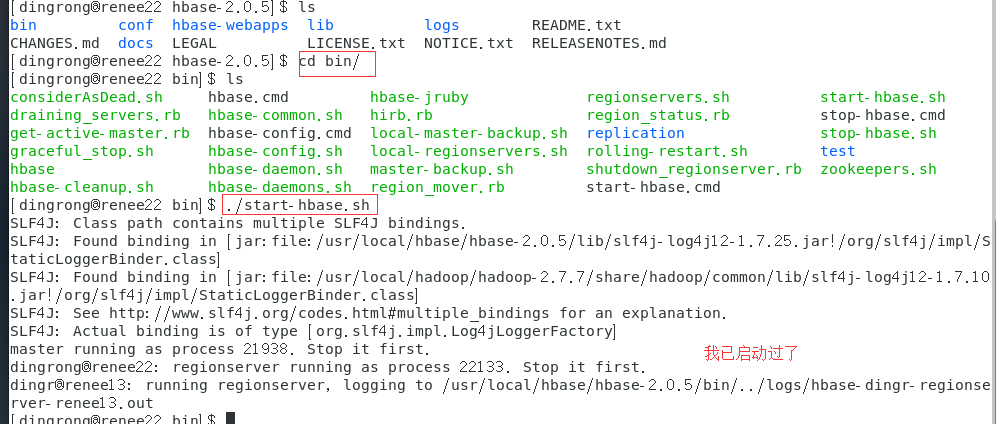
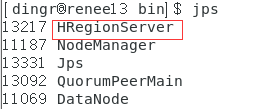
5.jps命令查看

6.浏览器查看

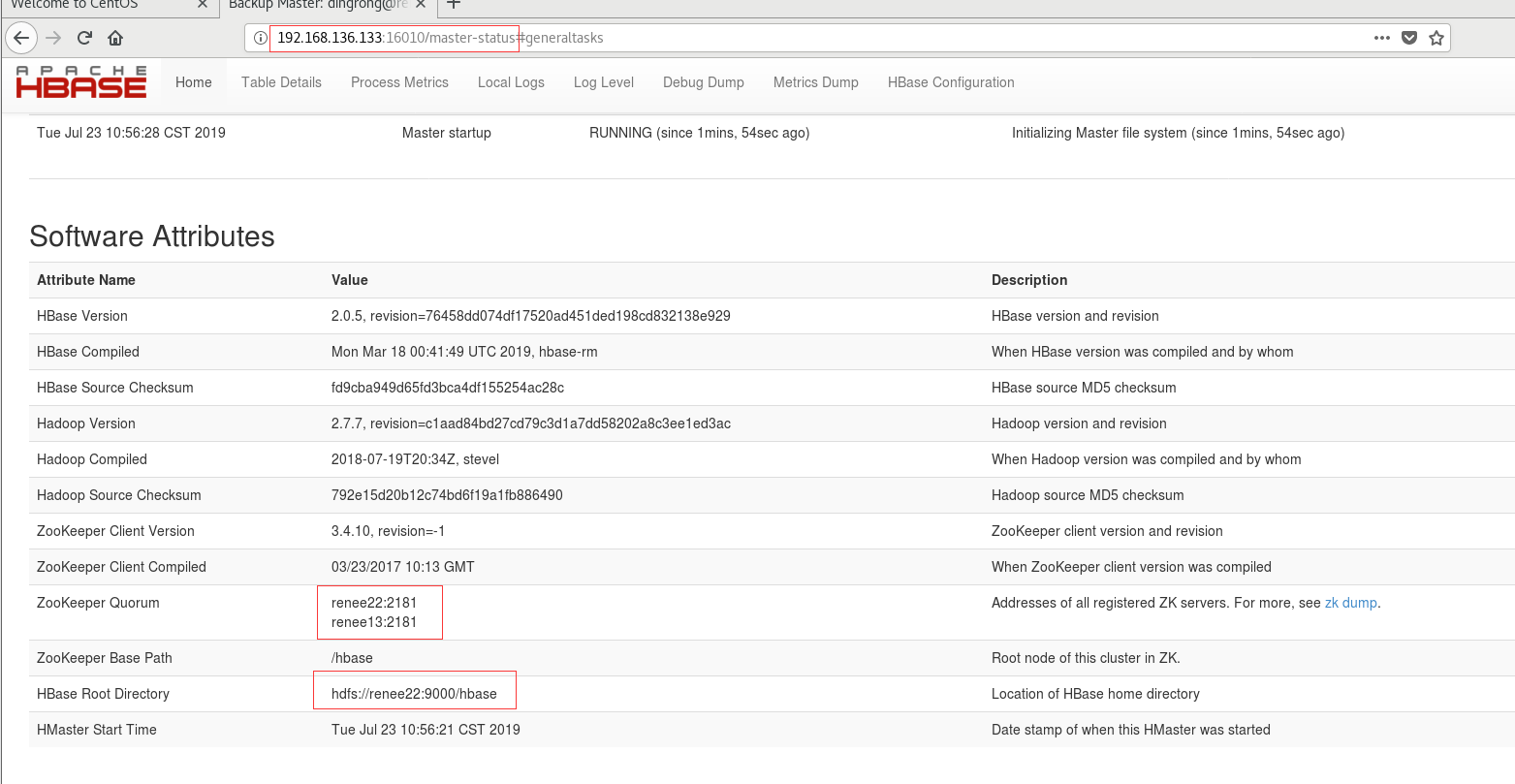

【注】:
查看时间命令 timedatectl
调整硬件时间和本地一致 timedatectl set-local-rtc 1
linux同步时间 ntpdate ntp.sjtu.edu.cn
这个从节点的webUI一直是这样,显示不出来,我也没解决掉,所以我换root用户重装了。
传送门:
root用户搭建完整hadoop,zookeeper和hbase
centOS7搭建hadoop,zookeeper,hbase的更多相关文章
- CentOS7.4伪分布式搭建 hadoop+zookeeper+hbase+opentsdb
前言 由于hadoop和hbase都得想zookeeper注册,所以启动顺序为 zookeeper——>hadoop——>hbase,关闭顺序反之 一.前期准备 1.配置ip 进入文件编辑 ...
- CentOS7搭建 Hadoop + HBase + Zookeeper集群
摘要: 本文主要介绍搭建Hadoop.HBase.Zookeeper集群环境的搭建 一.基础环境准备 1.下载安装包(均使用当前最新的稳定版本,截止至2017年05月24日) 1)jdk-8u131 ...
- Hadoop HA高可用集群搭建(Hadoop+Zookeeper+HBase)
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 一.服务器环境 主机名 IP 用户名 密码 安装目录 master188 192.168.29.188 hadoop hadoop /home/ha ...
- hadoop+zookeeper+hbase分布式安装
前期服务器配置 修改/etc/hosts文件,添加以下信息(如果正常IP) 119.23.163.113 master 120.79.116.198 slave1 120.79.116.23 slav ...
- Hadoop zookeeper hbase spark phoenix (HA)搭建过程
环境介绍: 系统:centos7 软件包: apache-phoenix-4.14.0-HBase-1.4-bin.tar.gz 下载链接:http://mirror.bit.edu.cn/apac ...
- 基本环境安装: Centos7+Java+Hadoop+Spark+HBase+ES+Azkaban
1. 安装VM14的方法在 人工智能标签中的<跨平台踩的大坑有提到> 2. CentOS分区设置: /boot:1024M,标准分区格式创建. swap:4096M,标准分区格式创建. ...
- docker应用-3(搭建hadoop以及hbase集群)
要用docker搭建集群,首先需要构造集群所需的docker镜像.构建镜像的一种方式是,利用一个已有的镜像比如简单的linux系统,运行一个容器,在容器中手动的安装集群所需要的软件并进行配置,然后co ...
- 快速搭建Hadoop及HBase分布式环境
本文旨在快速搭建一套Hadoop及HBase的分布式环境,自己测试玩玩的话ok,如果真的要搭一套集群建议还是参考下ambari吧,目前正在摸索该项目中.下面先来看看怎么快速搭建一套分布式环境. 准备 ...
- hadoop +zookeeper + hbase 单节点安装
项目描述: 今天花了680元买了阿里云的一台内存1G, 带宽1M 的云主机. 想以后方便测试用,而且想把自己的博客签到自己的主机上.所以自己就搭了一个测试的环境. 可以用来进行基本的hbase 入库, ...
- 初学Hadoop:利用VMWare+CentOS7搭建Hadoop集群
一.前言 开始学习数据处理相关的知识了,第一步是搭建一个Hadoop集群.搭建一个分布式集群需要多台电脑,在此我选择采用VMWare+CentOS7搭建一个三台虚拟机组成的Hadoop集群. 注:1 ...
随机推荐
- VBA精彩代码分享-1
今天下班前分享一下之前在网上搜到的两段好用的VBA代码,貌似都来自国外,觉得挺好,模仿不来. 第一段的功能是修改VBA控件中的文本框控件,使其右键可以选择粘贴.复制.剪切等: Option Expli ...
- TypeScript入门四:TypeScript的类(class)
TypeScript类的基本使用(修饰符) TypeScript类的抽象类(abstract) TypeScript类的高级技巧 一.TypeScript类的基本使用(修饰符) TypeScript的 ...
- css 之calc无效踩坑
踩坑: 1. height:calc(100vh-60); 无效 2.height:calc(100vh-60px); 无效 3.height:calc(100vh - 60px); 终于起效 总 ...
- TLV320AIC3268寄存器读写
该芯片支持I2C和SPI读写寄存器,本人用的是SPI1接口. 以下是对手册中SPI接口读写寄存器相关内容的翻译(英文版可以看手册的94页~) 在SPI控制模式下,TLV320AIC3268使用SCL_ ...
- CAFFE(0):Ubuntu 下安装anaconda2和anaconda3
这个步骤可以看做是安装caffe可以进行或者不必要的步骤,不过笔者建议安装anaconda2和anaconda3,里面会包含很多的模块,省去caffe学习过程中出现模块不存在的各种错误. 第一步.进入 ...
- 移动端meta常用的设置
1.qq强制横屏或者竖屏显示 : <meta name="x5-orientation" content="portrait ||andscape&quo ...
- dao层取值用List<map<String,Object>>接收有序map
发现一个好玩的Map, 当需要Map有序时用java.util.LinkedHashMap接收,是有序map resultType="java.util.LinkedHashMap" ...
- MyBatis-12-动态SQL
12.动态SQL 什么事动态SQL:动态SQL就是指根据不同的条件生成不同的SQL语句 利用动态SQL这一特性可以彻底摆脱这种痛苦 动态 SQL 元素和 JSTL 或基于类似 XML 的文本处理器相似 ...
- ak-1
最近研究ak,网上也有很多这方面的资料,就不重复叙述了,本次记录就是自己在做适应时的一些记录. 本次环境 中标麒麟 金蝶apusic 人大金仓 先说说东西从哪下载怎么来的 基本都是通过官网打电话申请 ...
- [SDOI2010]代码拍卖会——DP
原题戳这里 绝对是一道好题 需要注意到两个东西 1.符合条件的数可以拆成一堆\(11...11\)相加的形式,比如\(1145=1111+11+11+11+1\) 2.\(1,11,111,1111, ...