join on 和group
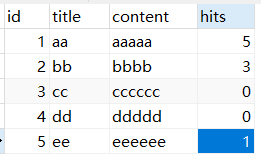
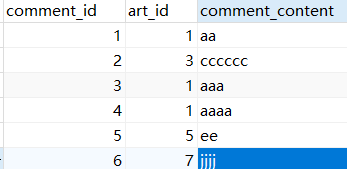
左边的表是article文章表,右边的是comment文章回复表。
今天mysql查询的时候,遇到了有趣的事,任务是查询数据库需要得到以下格式的文章标题列表,并按照回复数量排序,回复最高的排在最前面。
“文章id 文章标题 点击量 回复数量”,
没有回复的,默认回复数量为0. 最开始想到的答案是 select a.id,a.title,a.hits,count(c.comment_id) as total from article as a left join comment as c on a.id=c.art_id group by c.art_id order by total desc; 但是查询出来的结果却是明显不符合题意,少了一行数据;
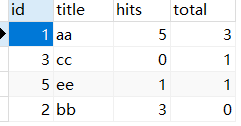
正确答案是 select a.id,a.title,a.hits,count(c.comment_id) as total from article as a left join comment as c on a.id=c.art_id group by a.id order by total desc;
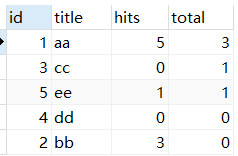
还有一种查询方法(但是结果有null,不符合题意):select a.id,a.title,c.num from article as a left join (select art_id, count(comment_id) as num from comment group by art_id) as c on a.id = c.art_id order by c.num desc;
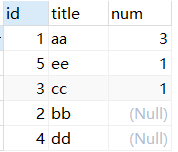
他们的区别是什么?为什么会是这种结果?简单分析一下:先看这条语句 select a.id,a.title,a.hits from article as a left join comment as c on a.id=c.art_id;
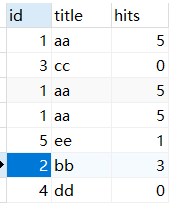
根据结果来看就会明白join on 查询,会把满足a.id=c.art_id的数据每一条都查询出来,不论结果是否会重复(只要在表里的数据满足条件)。在这条语句基础上加count看看会发生什么,select a.id,a.title,a.hits,count(c.comment_id) as total from article as a left join comment as c on a.id=c.art_id;

只显示一条数据了,因为没有任何的条件限制,所以count是在查询的所有结果中计算回复数量。到这里可以回头看第一次查询语句,他是按照c.art_id来分组,然后count在分组的基础上计算每个分组的回复数量,而文章ID为2和4的没有对应的分组,所以count把他们按照一个组来处理了,就得到了如图所示的结果。而正确答案是按照a.id来分组的,也就是文章ID为2和4的有各自的分组,就得到了正确的结果。而第三种会有值为null的情况为什么?因为他是嵌套查询,select art_id, count(comment_id) as num from comment group by art_id;这条子句查询的结果是

也就是说相当于join on是查询文章表和这张表,而不是查询文章表和文章回复表了,也就是这两张表的left join on 正常查询的出来的结果。
join on 和group的更多相关文章
- sql-多表查询JOIN与分组GROUP BY
一.内部连接:两个表的关系是平等的,可以从两个表中获取数据.用ON表示连接条件 SELECT A.a,B.b FROM At AS A INNER JOINT Bt AS B ON A.m=B.n ...
- MySQL select from join on where group by having order by limit 执行顺序
书写顺序:select [查询列表] from [表] [连接类型] join [表2] on [连接条件] where [筛选条件] group by [分组列表] having [分组后的筛选条件 ...
- Mysql查询语句,select,inner/left/right join on,group by.....[例题及答案]
创建如下表格,命名为stu_info, course_i, score_table. 题目: 有如图所示的三张表结构,学生信息表(stu_info),课程信息表(course_i),分数信息表(sco ...
- Hibernate 抓取策略fetch-1 (select join subselect)
原文 :http://4045060.blog.51cto.com/4035060/1088025 部分参考:http://www.cnblogs.com/rongxh7/archive/2010/0 ...
- How to join a Ubuntu to Windows Domain
My testing environment: Windows Server 2012 R2 Essentials: With AD and standalone DC in one single b ...
- MySQL的Join使用
在MySQL(以5.1为例)中,表连接的语法可以参见MySQL官方手册:MySQL官方手册-JOIN 在查询中,连接的语法类似 SELECT select_expr FROM table_refere ...
- MySQL自学笔记_联结(join)
1. 背景及原因 关系型数据库的一个基本原则是将不同细分数据放在单独的表中存储.这样做的好处是: 1).避免重复数据的出现 2).方便数据更新 3).避免创建重复数据时出错 例子: 有供应商信息和产 ...
- 【Hive】Hive笔记:Hive调优总结——数据倾斜,join表连接优化
数据倾斜即为数据在节点上分布不均,是常见的优化过程中常见的需要解决的问题.常见的Hive调优的方法:列剪裁.Map Join操作. Group By操作.合并小文件. 一.表现 1.任务进度长度为99 ...
- Mysql 单表查询-排序-分页-group by初识
Mysql 单表查询-排序-分页-group by初识 对于select 来说, 分组聚合(((group by; aggregation), 排序 (order by** ), 分页查询 (limi ...
随机推荐
- 初遇PHP(一)
因为想给自己弄一个微信公众号,顺便提升一下自己,所以有了以下内容,本次学习的最终目标是能用php制作套微信公众号,然后转成Java.为什么要这么麻烦呢,其一是买的资料书是php的,其二是顺水推舟刚好可 ...
- scoket模块 粘包问题 tcp协议特点 重启服务器会遇到地址被占用问题
scoket()模块函数用法 import socket socket.socket(socket_family,socket_type,protocal=0) 获取tcp/ip套接字 tcpsock ...
- Python学习8——魔法方法、特性和迭代器
Python中很多名称比较古怪,开头和结尾都是两个下划线.这样的拼写表示名称有特殊意义,因此绝不要在程序中创建这样的名称.这样的名称中大部分都是魔法(方法)的名称.如果你的对象实现了这些方法,他们将在 ...
- 安装jenkins时出现 No such plugin: cloudbees-folder的解决办法
今天安装了一下jenkins,在初始化安装插件时出现" No such plugin: cloudbees-folder"错误,根据网上的教程: 1.打开链接"http: ...
- 进阶Java编程(10)反射与简单Java类
1,传统属性自动赋值弊端 简单Java类主要由属性构成,并且提供有setter与getter类,同时简单Java类最大的特征就是通过对象保存相应的类属性的内容.但是如果使用传统的简单Java类开发,那 ...
- asp.net 9 ViewState
VIEWSTATE aspx: <%@ Page Language="C#" AutoEventWireup="true" CodeBehind=&quo ...
- 在Global.asax中 注册Application_Error事件 捕获全局异常
参考于:https://shiyousan.com/post/635813858052755170 在ASP.NET MVC中,通过应用程序生命周期中的Application_Error事件可以捕获到 ...
- 三、maven学习-高级
maven父子工程
- PHP扩展之 Imagick安装
最近的PHP项目中,需要用到切图和缩图的效果,在本地windows开发环境,安装过程遇到好多问题,在此与大家分享. php官网里,一大群老外也看不懂这玩意怎么装,主要原因在于,php版本庞杂,还有x8 ...
- js弹窗返回值详解(window.open方式)
今天在改公司一个老系统时,碰到了window.open()的这个语法.虽然这个方法有点老,不太用了.所以有点不清楚父级弹框如何获取子级页面返回的值.为了解决这个问题,上网搜了一下.原作者参考网址:ht ...