scikit-learn生成随机数据集
%matplotlib inline
from sklearn import datasets
import matplotlib.pyplot as plt
import numpy as np
scikit-learn生成随机数据集
scikit-learn 包含了一系列的用来创建指定规模和复杂度的人工数据的样本生成器。
聚类和分类的生成器
单标签
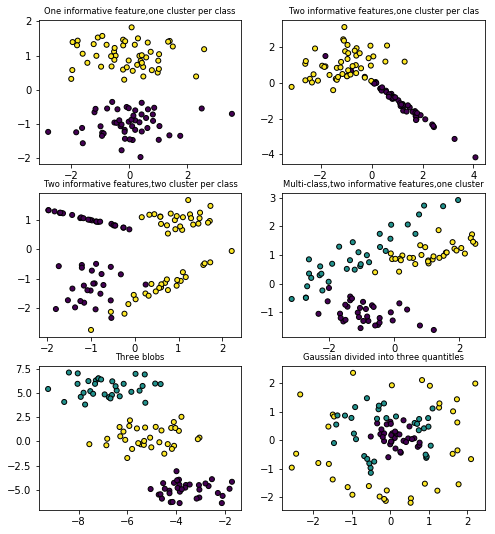
make_blobs和make_classification都可以创建多个类别的数据集。但make_blobs主要是用来创建聚类的数据集,对每个聚类的中心,标准差都有很好的控制。make_classification通过冗杂,无效的特征等方法引入噪声,主要来创建分类的数据集。make_gaussian_quantities把单个高斯簇划分为被同心超球面分割为两等份的类。make_hastie_10_2创建了一个10维2分类的问题。make_circles和make_moons创建对有些算法具有一定挑战性的二维二分类数据集。make_blobs 和 make_classification
plt.figure(figsize=(8,8))
plt.subplots_adjust(bottom=0.05,top=0.9)
plt.subplot(321)
plt.title('One informative feature,one cluster per class',fontsize='small')
x1,y1=datasets.make_classification(n_samples=100,n_features=2,n_redundant=0,n_informative=1,n_clusters_per_class=1)
plt.scatter(x1[:,0],x1[:,1],marker='o',c=y1,s=25,edgecolor='k')
plt.subplot(322)
plt.title('Two informative features,one cluster per clas',fontsize='small')
x1,y1=datasets.make_classification(n_samples=100,n_features=2,n_redundant=0,n_informative=2,n_clusters_per_class=1)
plt.scatter(x1[:,0],x1[:,1],marker='o',c=y1,s=25,edgecolor='k')
plt.subplot(323)
plt.title('Two informative features,two cluster per class',fontsize='small')
x1,y1=datasets.make_classification(n_samples=100,n_features=2,n_redundant=0,n_informative=2,n_clusters_per_class=2)
plt.scatter(x1[:,0],x1[:,1],marker='o',c=y1,s=25,edgecolor='k')
plt.subplot(324)
plt.title('Multi-class,two informative features,one cluster',fontsize='small')
x1,y1=datasets.make_classification(n_samples=100,n_features=2,n_redundant=0,n_informative=2,n_clusters_per_class=1,
n_classes=3)# multicass here,n_classes is 3
plt.scatter(x1[:,0],x1[:,1],marker='o',c=y1,s=25,edgecolor='k')
plt.subplot(325)
plt.title('Three blobs',fontsize='small')
x1,y1=datasets.make_blobs(n_samples=100,n_features=2,centers=3)
plt.scatter(x1[:,0],x1[:,1],marker='o',c=y1,s=25,edgecolor='k')
plt.subplot(326)
plt.title('Gaussian divided into three quantitles',fontsize='small')
x1,y1=datasets.make_gaussian_quantiles(n_samples=100,n_features=2,n_classes=3)
plt.scatter(x1[:,0],x1[:,1],marker='o',c=y1,s=25,edgecolor='k')
<matplotlib.collections.PathCollection at 0x1f824fa37b8>
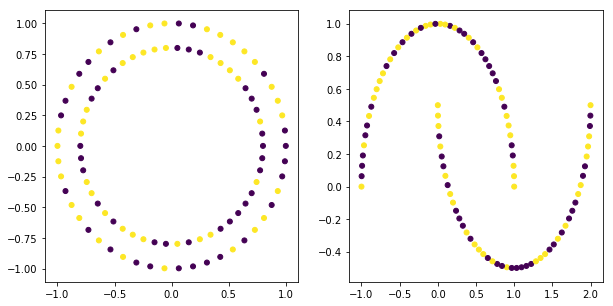
- make_circles 和 make_moons
plt.figure(figsize=(10,5))
plt.subplot(121)
x1,y1=datasets.make_circles(n_samples=100)
plt.scatter(x1[:,0],x1[:,1],c=y,s=25)
plt.subplot(122)
x1,y1=datasets.make_moons(n_samples=100)
plt.scatter(x1[:,0],x1[:,1],c=y,s=25)
<matplotlib.collections.PathCollection at 0x1f825549630>
多标签
多标签分类与多种类分类不一样,多标签分类中一个样本可以属于多个分类类别,而多种类分类中的一个样本智能属于一个分类类别。
sklearn中make_multilabel_classification用于生成多标签分类数据集。
被标记的点是按下面的规则绘制:比如属于第1类,不属于第2,3类,则标红颜色;全部属于3个类别,则标棕色等。
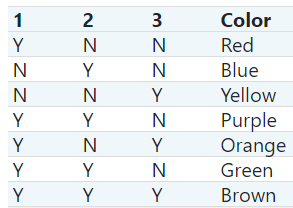
COLORS = np.array(['!',
'#FF3333', # red
'#0198E1', # blue
'#BF5FFF', # purple
'#FCD116', # yellow
'#FF7216', # orange
'#4DBD33', # green
'#87421F' # brown
])
COLORS.take(1)
'#FF3333'
x=np.arange(12).reshape((3,4))
x
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
RANDOM_STATE=np.random.randint(2**10)
x,y,p_c,pW_c=datasets.make_multilabel_classification(n_samples=150,n_features=2,
n_classes=3,n_labels=1,
length=50,allow_unlabeled=False,
return_distributions=True,
random_state=RANDOM_STATE)
x.shape
(150, 2)
y.shape
(150, 3)
y[0]
array([1, 0, 0])
y[100]
array([0, 0, 1])
x[0]
array([ 8., 35.])
x[1]
array([18., 41.])
y[0]
array([1, 0, 0])
y[1]
array([1, 0, 1])
y.shape
(150, 3)
(y*[1,2,4]).sum(axis=1)
array([1, 5, 1, 1, 1, 1, 1, 1, 1, 1, 4, 7, 3, 3, 1, 3, 7, 5, 1, 4, 3, 3,
5, 1, 1, 1, 3, 6, 3, 5, 1, 1, 1, 6, 2, 3, 1, 1, 1, 1, 7, 1, 3, 6,
1, 3, 1, 3, 1, 5, 1, 5, 2, 1, 5, 5, 2, 1, 3, 1, 4, 4, 1, 1, 5, 4,
1, 7, 4, 1, 2, 4, 2, 1, 4, 2, 1, 1, 1, 1, 5, 7, 3, 6, 5, 5, 1, 1,
1, 1, 3, 4, 3, 3, 2, 4, 3, 7, 5, 1, 4, 1, 7, 6, 3, 5, 2, 5, 1, 7,
1, 1, 4, 6, 1, 7, 2, 3, 1, 1, 5, 1, 7, 1, 2, 1, 2, 5, 1, 1, 4, 7,
3, 1, 1, 1, 5, 1, 5, 1, 3, 7, 1, 6, 5, 5, 4, 4, 7, 1])
plt.scatter(x[:,0],x[:,1],color=COLORS.take((y*[1,2,4]).sum(axis=1)),marker='.')
<matplotlib.collections.PathCollection at 0x1f825628e80>
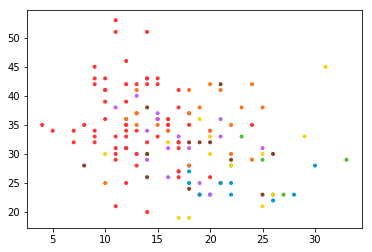
独热编码与映射阵,[1,2,4,8,16...]的乘积,能清楚的将标记规则与独热编码对应起来,比如产生的结果是3,则一定是[1,1,0],产生的结果是4,一定是[0,0,1],产生的结果是6,一定是[0,1,1]。其证明也非常简单,假设有N类,则标签的个数是2N-1,映射阵是[1,2,4,8,16,...2N],现在考虑最后一个标签,即符合所有类,即映射阵的和,即等比数列,显然与标签的个数相一致。
返回的p_c是每个类被绘制的概率
p_c
array([0.60031363, 0.19681806, 0.20286832])
p_w_c:是对于每个类下的每个特征的概率
pW_c
array([[0.26471562, 0.46622308, 0.43420831],
[0.73528438, 0.53377692, 0.56579169]])
plt.scatter(x[:,0],x[:,1],color=COLORS.take((y*[1,2,4]).sum(axis=1)),marker='.')
plt.scatter(pW_c[0]*50,pW_c[1]*50,marker='*',linewidth=.5,edgecolor='black',color=COLORS.take([1,2,4]),
s=20+1500*p_c**2)
<matplotlib.collections.PathCollection at 0x1f8257627b8>
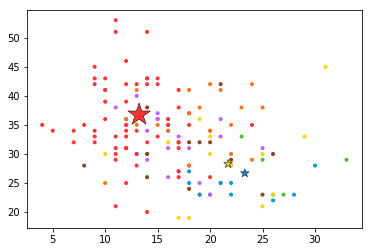
pW_c[0]是第一个特征对于3个类别的概率,pW_c[1]是第二个特征对于3个类别的概率,所以颜色对于三个类别分别取[1,2,4],大小与每个类别的概率相关
回归的生成器
- make_regression
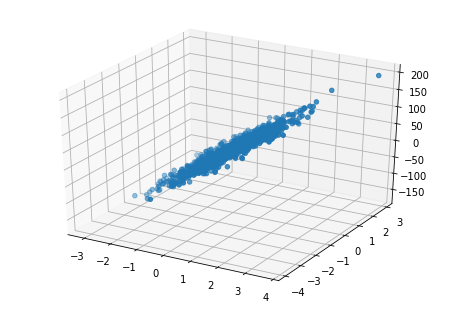
x,y,coe=datasets.make_regression(n_samples=1000,n_features=2,n_informative=2,noise=10,coef=True)
x.shape
(1000, 2)
y.shape
(1000,)
from mpl_toolkits.mplot3d import Axes3D
fig=plt.figure()
ax=Axes3D(fig)
ax.scatter(x[:,0],x[:,1],y)
<mpl_toolkits.mplot3d.art3d.Path3DCollection at 0x1f8256c3dd8>
scikit-learn生成随机数据集的更多相关文章
- Scikit Learn: 在python中机器学习
转自:http://my.oschina.net/u/175377/blog/84420#OSC_h2_23 Scikit Learn: 在python中机器学习 Warning 警告:有些没能理解的 ...
- scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类 (python代码)
scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类数据集 fetch_20newsgroups #-*- coding: UTF-8 -*- import ...
- (原创)(三)机器学习笔记之Scikit Learn的线性回归模型初探
一.Scikit Learn中使用estimator三部曲 1. 构造estimator 2. 训练模型:fit 3. 利用模型进行预测:predict 二.模型评价 模型训练好后,度量模型拟合效果的 ...
- 生成随机id对比
生成随机id 最近公司的项目游戏生成的随机不重复id,重复概率有点大, 代码如下: private static int id = 0; public static int serverID = 0; ...
- Java生成随机验证码
package com.tg.snail.core.util; import java.awt.Color; import java.awt.Font; import java.awt.Graphic ...
- C# 写的一个生成随机汉语名字的小程序
最近因为要做数据库相关的测试,频繁使用到测试数据,手动添加太过于麻烦,而且复用性太差,因此干脆花了点时间写了一个生成随机姓名和相关数据的类,贴在这里,有需用的同志们可以参考一下.代码本身质量不好,也不 ...
- [源码]RandomId 生成随机字符串
/* * 名称:RandomId * 功能:生成随机ID * 作者:冰麟轻武 * 日期:2012年1月31日 03:36:28 * 版本:1.0 * 最后更新:2012年1月31日 03:36:28 ...
- .net生成随机字符串
生成随机字符串的工具类: /// <summary> /// 随机字符串工具类 /// </summary> public class RandomTools { /// &l ...
- C#生成随机验证码
使用YZMHelper帮助类即可 using System; using System.Web; using System.Drawing; using System.Security.Cryptog ...
- loadrunner生成随机身份证和银行卡号
生成银行卡号码: Action() { char card[19] = {'6','2','2','7','0','0','0','0','0','0','0','0','0','0','0','0' ...
随机推荐
- C语言线程池的常见实现方式详解
在 C 语言中,线程池通常通过 pthread 库来实现.以下是一个详细的说明,介绍了 C 语言线程池的常见实现方式,包括核心概念.实现步骤和具体的代码示例. 点击查看代码 1. 线程池的基本结构 线 ...
- python 代码编写问题
1.解决控制台不输出问题 2.写代码写一些伪代码,即实现过程.步骤 3.再填充代码到伪代码 4.规则 正常变量 不太推荐使用下划线
- 稳定且高性价比的大模型存储:携程 10PB 级 JuiceFS 工程实践
在过去两年多的时间里,随着 AI 大模型的快速发展,JuiceFS 在携程内部得到了越来越多 AI 用户的关注.目前,携程通过 JuiceFS 管理着 10PB 数据规模,为 AI 训练等多个场景提供 ...
- laradock 更改 mysql 版本
# 修改 .env 文件 MYSQL_VERSION=5.7 # 默认为 latest #停止mysql容器 docker-compose stop mysql # 删除旧数据库数据 rm -rf ~ ...
- HTML5 给网站添加图标
1.首先将图标上传到对应的目录下 2.在网页的index.html,添加已下代码到<head>标签里 <link rel="icon" href="i_ ...
- [每日算法 - 华为机试] leetcode680. 验证回文串 II
入口 力扣https://leetcode.cn/problems/valid-palindrome-ii/submissions/ 题目描述 给你一个字符串 s,最多 可以从中删除一个字符. 请你判 ...
- 【JDBC第7章】DAO及相关实现类
第7章:DAO及相关实现类 DAO:Data Access Object访问数据信息的类和接口,包括了对数据的CRUD(Create.Retrival.Update.Delete),而不包含任何业务相 ...
- 【Linux】5.9 Shell函数
Shell 函数 1. 自定义函数 linux shell 可以用户定义函数,然后在shell脚本中可以随便调用. shell中函数的定义格式如下: [ function ] funname [()] ...
- 【虚拟机】Windows(x86)上部署ARM虚拟机(Ubuntu)
[虚拟机]Windows(x86)上部署ARM虚拟机(Ubuntu) 零.起因 最近在学嵌入式,这就不得不涉及ARM指令集,但是电脑是x86指令集的,用手机不太方便,买开发板又要等几天--,总之就是要 ...
- 再说PG的连接
前面说过连接PG的方法,但是遇到问题又不通了. 按照前面的做法还是不行,正是鼻子气歪了. 到pg老家下载PGODBC,安装了,还是不行. 其实仅仅copy一个libpg.dll是不够的.因为libpg ...