(数据科学学习手札12)K-means聚类实战(基于R)
上一篇我们详细介绍了普通的K-means聚类法在Python和R中各自的实现方法,本篇便以实际工作中遇到的数据集为例进行实战说明。
数据说明:
本次实战样本数据集来自浪潮集团提供的美团的商家信息,因涉及知识产权问题恕难以提供数据地址;
我选择的三个维度的数值型数据分别为“商家评分”,“商家评论数”,“本月销售额”,因为数值极差较大,故对原数据先进行去缺省值-标准化处理,再转为矩阵形式输入K-means算法之中,经Rtsne对原数据进行降维后具体代码和可视化聚类效果如下:
rm(list=ls())
library(readxl)
library(Rtsne)
setwd('C:\\Users\\windows\\Desktop')
data <- read_xlsx('重庆美团商家信息.xlsx')
token <- data[1,1]
data <- subset(data,数据所属期 == token,select=c('商家评分','商家评论数','本月销售额'))
input <- as.matrix(na.omit(data))
#数据标准化
input <- scale(as.matrix(input))
#数据降维
tsne <- Rtsne(input,check_duplicates = FALSE) #自定义代价函数计算函数
Mycost <- function(data,centers_){
l <- length(data[,1])
d <- matrix(0,nrow=l,ncol=length(centers_[,1]))
for(i in 1:l){
for(j in 1:length(centers_[,1])){
dd <- 0
for(k in 1:length(data[1,])){
dd <- dd + (data[i,k]-centers_[j,k])^2
}
d[i,j] <- sqrt(dd)
}
}
mindist <- apply(d,1,min)
return(sum(mindist))
}
colors = c('red','green','yellow','black','blue','grey')
#对k的值进行试探
cost <- c()
par(mfrow=c(2,3))
for(k in 2:7){
cl <- kmeans(input,centers=k)
plot(tsne$Y,col=colors[cl$cluster],iter.max=50)
title(paste(paste('K-means Cluster of ',as.character(k),'Clusters')))
cost[k-1] <- Mycost(input,cl$centers)
}
#绘制代价函数变化情况
par(mfrow=c(1,1))
plot(2:7,cost,type='o',xlab='K',ylab='Cost')
title('Cost Change')

代价函数变化情况如下:

根据上述代价函数变化情况,依据肘部法则,选取k=3,下面得到k取定3时具体的聚类结果:
cl <- kmeans(input,centers=3,iter.max=50)
plot(tsne$Y,col=colors[cl$cluster])
title(paste(paste('K-means Cluster of ',as.character(3),'Clusters')))
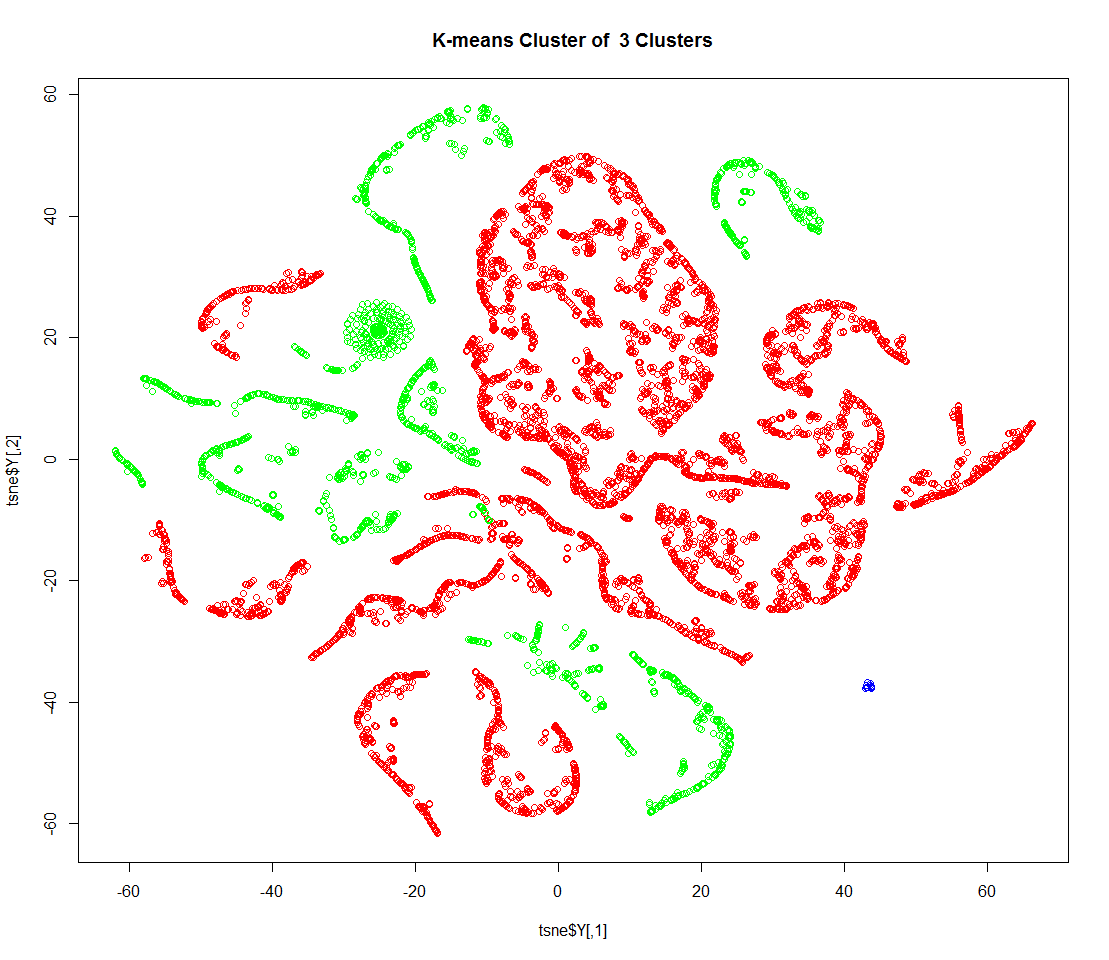
再根据聚类的标号结果,进行下面一系列具体的分析:
先来看这三类的平均销售额:
anl <- na.omit(data)
anl$类别 <- cl$cluster
str(anl) type1 <- subset(anl,类别==1) type2 <- subset(anl,类别==2) type3 <- subset(anl,类别==3) goaldata <- matrix(0,nrow=3,ncol=3)
goaldata[1,] = apply(type1[,1:3],2,mean)
goaldata[2,] = apply(type2[,1:3],2,mean)
goaldata[3,] = apply(type3[,1:3],2,mean) barplot(log(t(goaldata[3,])),names.arg = c('Type1','Type2','Type3'),xlab='Type',ylab='对数化数值')
title('销售额')

店铺平均评分:

店铺平均评论数:

下面再绘制出这三种type的各指标密度分布:
par(mfrow=c(1,3))
plot(density(type1$商家评分))
plot(density(type1$商家评论数))
plot(density(type1$本月销售额)) par(mfrow=c(1,3))
plot(density(type2$商家评分))
plot(density(type2$商家评论数))
plot(density(type2$本月销售额)) par(mfrow=c(1,3))
plot(density(type3$商家评分))
plot(density(type3$商家评论数))
plot(density(type3$本月销售额))


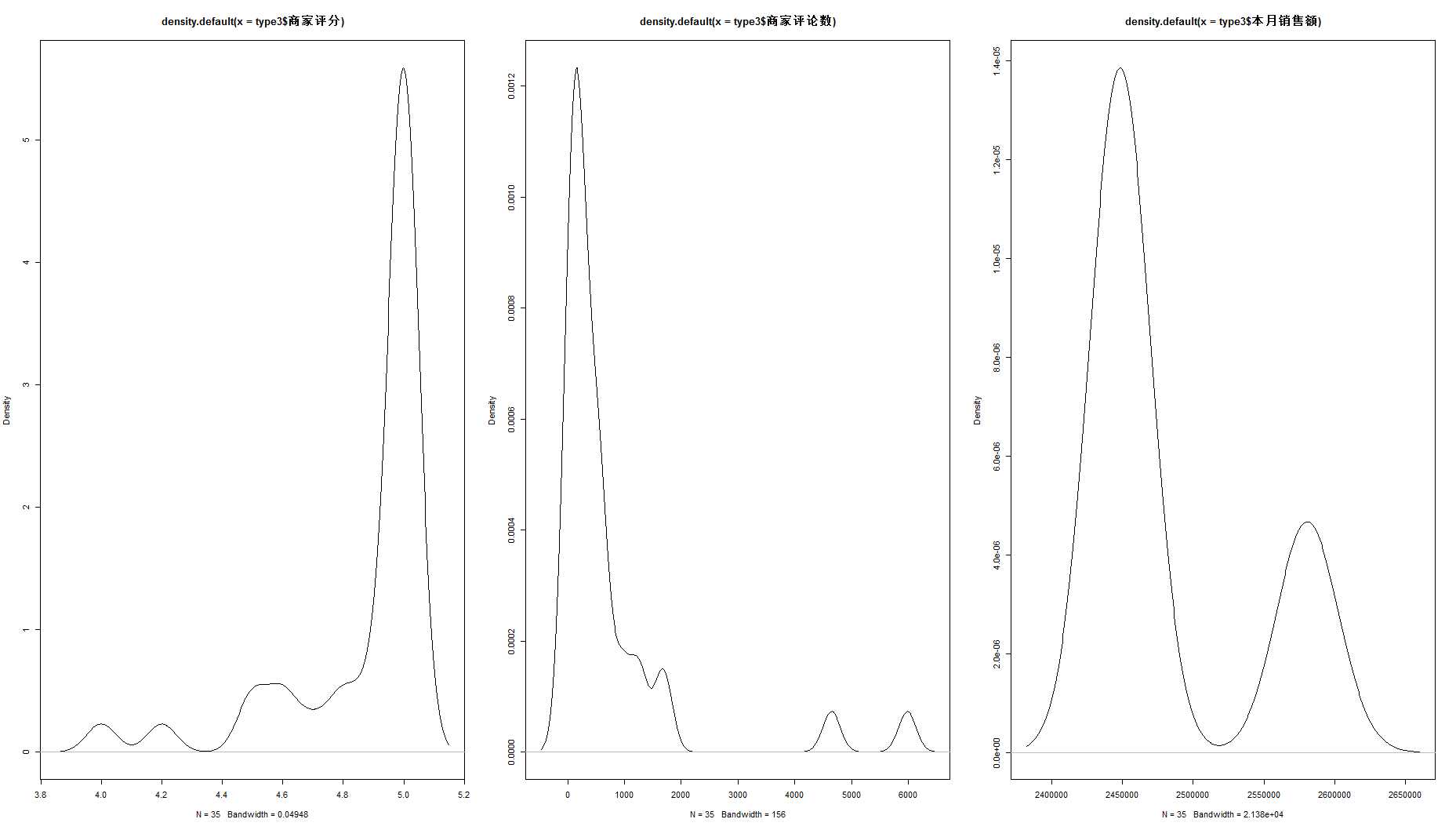
结合上述可视化结果,我们可以推断:type1代表评分较高但热度和知名度都较低的小店,这类店铺是我们推广宣传业务的最有潜力的客户群;type2代表评分较低且热度和知名度都较低的店,这类店在产品和宣传上都比较差劲,是比较劣质的客户群;type3代表着口碑和热度都较高的顶级店铺,这类店铺多为正新鸡排、一只酸奶牛这样的顶级连锁店铺,在宣传和产品上都很优秀,对我们推广宣传业务来说价值不大,因为已经有很成熟的广告体系。
以上便是此次简单的K-means聚类实战,如有不足望提出。
(数据科学学习手札12)K-means聚类实战(基于R)的更多相关文章
- (数据科学学习手札10)系统聚类实战(基于R)
上一篇我们较为系统地介绍了Python与R在系统聚类上的方法和不同,明白人都能看出来用R进行系统聚类比Python要方便不少,但是光介绍方法是没用的,要经过实战来强化学习的过程,本文就基于R对2016 ...
- (数据科学学习手札13)K-medoids聚类算法原理简介&Python与R的实现
前几篇我们较为详细地介绍了K-means聚类法的实现方法和具体实战,这种方法虽然快速高效,是大规模数据聚类分析中首选的方法,但是它也有一些短板,比如在数据集中有脏数据时,由于其对每一个类的准则函数为平 ...
- (数据科学学习手札11)K-means聚类法的原理简介&Python与R实现
kmeans法(K均值法)是麦奎因提出的,这种算法的基本思想是将每一个样本分配给最靠近中心(均值)的类中,具体的算法至少包括以下三个步骤: 1.将所有的样品分成k个初始类: 2.通过欧氏距离将某个样品 ...
- (数据科学学习手札08)系统聚类法的Python源码实现(与Python,R自带方法进行比较)
聚类分析是数据挖掘方法中应用非常广泛的一项,而聚类分析根据其大体方法的不同又分为系统聚类和快速聚类,其中系统聚类的优点是可以很直观的得到聚类数不同时具体类中包括了哪些样本,而Python和R中都有直接 ...
- (数据科学学习手札16)K-modes聚类法的简介&Python与R的实现
我们之前经常提起的K-means算法虽然比较经典,但其有不少的局限,为了改变K-means对异常值的敏感情况,我们介绍了K-medoids算法,而为了解决K-means只能处理数值型数据的情况,本篇便 ...
- (数据科学学习手札14)Mean-Shift聚类法简单介绍及Python实现
不管之前介绍的K-means还是K-medoids聚类,都得事先确定聚类簇的个数,而且肘部法则也并不是万能的,总会遇到难以抉择的情况,而本篇将要介绍的Mean-Shift聚类法就可以自动确定k的个数, ...
- (数据科学学习手札09)系统聚类算法Python与R的比较
上一篇笔者以自己编写代码的方式实现了重心法下的系统聚类(又称层次聚类)算法,通过与Scipy和R中各自自带的系统聚类方法进行比较,显然这些权威的快捷方法更为高效,那么本篇就系统地介绍一下Python与 ...
- (数据科学学习手札75)基于geopandas的空间数据分析——坐标参考系篇
本文对应代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 在上一篇文章中我们对geopandas中的数据结 ...
- (数据科学学习手札55)利用ggthemr来美化ggplot2图像
一.简介 R中的ggplot2是一个非常强大灵活的数据可视化包,熟悉其绘图规则后便可以自由地生成各种可视化图像,但其默认的色彩和样式在很多时候难免有些过于朴素,本文将要介绍的ggthemr包专门针对原 ...
随机推荐
- ASP.NET中引用dll“找不到指定模块"的完美解决办法 z
DllImport是System.Runtime.InteropServices命名空间下的一个属性类,其功能是提供从非托管DLL导出的函数的必要调用信息.DllImport属性应用于方法,要求最少要 ...
- ORACLE_PROCEDURE_DROPTABLE
WEBSITE:https://stackoverflow.com/questions/14564641/drop-a-table-in-a-procedure Qusetion:Hou to use ...
- March 16 2017 Week 11 Thursday
Adventure may hurt you, but monotony will kill you. 也许冒险会让你受伤,但一成不变会让你灭亡. The very theme of the univ ...
- ZT 困难是什么?困
困难是什么?困难就是摆在我们面前的山峰,需要我们去翻越;困难就是摆阻碍我们前行的巨浪,需要我们扬帆劈刀斩浪航行:困难就是我们眼前所下的暴风雨,要坚信暴风雨过后会有阳光和彩虹. 其实困难并不可怕,怕的就 ...
- Python3基本数据类型(一、数字类型)
第一次写博客,感觉心情比较紧张,有一种要上台演讲的紧张感(虽然可能大概也许不会有人看).在此立个flag,以后每个学习阶段都要写一篇博客,来记录自己学习成长的这段日子.Fighting! 废话不多说, ...
- HXXXES 高可用双机RMAN异地备份 Notes
一.总览 大致上的逻辑如上图,简化细节来归纳,便是 用一个bat脚本来驱动整个备份过程. 二.一些准备工作 1.为备份所需的脚本,以及最终备份生成的文件创建目录 开始=>运行=> ...
- python 用cookie模拟登陆网站
import re import requests def get_info(url): headers = { "Cookie" :"***************** ...
- swift语言的特点(相对于oc)
1.泛型.泛型约束与扩展: 2.函数式编程: 3.值类型.引用类型: 4.枚举.关联值.元组等其他 上述为swift最大的特点 Another safety feature is that by de ...
- ACM-ICPC(10 / 10)——(完美世界2017秋招真题)
今天学了莫比乌斯反演,竟然破天荒的自己推出来了一个题目!有关莫比乌斯反演的题解,和上次的01分数规划的题解明天再写吧~~~ 学长们都在刷面试题,我也去试了试,120分钟,写出6题要有一点熟练度才行.先 ...
- jsp的4个作用域区别( pageScope、requestScope、sessionScope、applicationScope)
简单描述 page里的变量没法从index.jsp传递到test.jsp.只要页面跳转了,它们就不见了. request里的变量可以跨越forward前后的两页.但是只要刷新页面,它们就重新计算了. ...