day4学python 字符编码转换+元组概念
字符编码转换+元组概念
字符编码转换
#coding:gbk //此处必声明 文件编码(看右下角编码格式) #用来得到python默认编码
import sys
print(sys.getdefaultencoding()) #python本身所有数据类型默认Unicode (与文件编码无关)
s="你好" #encode得到的其他编码是byte类型 decode得到的Unicode是str类型
print(s.encode("utf-8").decode("utf-8").encode("gb2312").decode("gb2312"))
@@@@@@@@@@@@@@@@@@@@@@@@
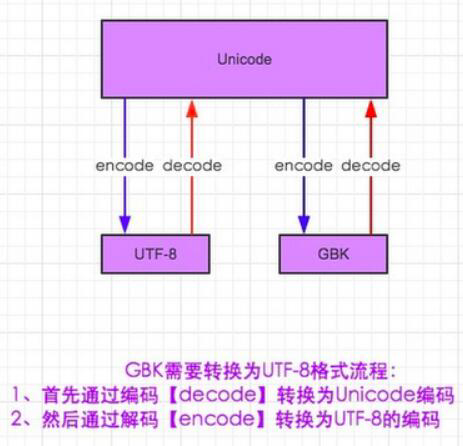
总结:一切编码都可解码为最大的Unicode 反之Unicode可转换为其他编码形式 ASCII==>GB2312 ==>GB18030==>GBK(常用中文编码) 中文编码演变
ASCII 英语占1个字节 8位 没有中文
万国码Unicode 所有字符都占2个字节 16位
=>>>>
升级成 可变长的编码UTF-8 所有英文字符 按照ASCII码占一个字节 中文字符占3个字节 python 3.0默认Unicode格式
========================================================================================
#函数作用
#1.代码重用
#2.保持一致性
#3.可扩展性
#返回数=0个 返回none
def fun1():
print(1) #返回数=1个 返回这个数
def fun2():
print(2)
return 0 #返回数>1个 返回元组组合
def fun3():
print(3)
return 1,[0,1,3,6],{"sa":"bi"} def num(x,y=2):
print(x,y)
num(1,2) #与形参列表一一对应
num(y=1,x=2) #位置参数都标出 与顺序无关
num(2,y=3) #关键参数只能放于位置参数后
num(2) #默认参数非必传 但也可给 并覆盖 def test(x,*args): #参数组 形参以*开头 只能接受位置参数 不能接受关键参数
print(x) #取出首位 接受多个参数其他位变为元组
print(args)
test("",23,1,4353,["",234],{"s":2})
test(*[1,32,43,2]) #**kwargs
def test2(**kwargs): #接受关键字参数变为字典形式
print(kwargs)
test2(name='cf',age=20,sex="man")
test2(**{'name':'al','age':'','sex':'f'})
总结:
def test3(name,age=18,*args,**kwargs): #按形参顺序 *args(反元组)位于一般形参后 **kwargs位于最后
print(name)
print(age)
print(args)
print(kwargs)
test3('cf',12,"s",sex="nan")
输出:
cf
12
('s',) #位置参数变为元组
{'sex': 'nan'} #关键字参数变为字典
day4学python 字符编码转换+元组概念的更多相关文章
- Python—字符编码转换、函数基本操作
字符编码转换 函数 #声明文件编码,格式如下: #-*- coding:utf-8 -*- 注意此处只是声明了文件编码格式,python的默认编码还是unicode 字符编码转换: import sy ...
- Python字符编码转换
编码回顾 在备编码相关的课件时,在知乎上看到一段关于Python编码的回答这哥们的这段话说的太对了,搞Python不把编码彻底搞明白,总有一天它会猝不及防坑你一把.不过感觉这哥们的答案并没把编码问题写 ...
- python 字符编码 转换
#!/bin/env python#-*- encoding=utf8 -*-# 文件头指定utf8编码还是乱码时,使用下面方式指定# fix encoding problem import sys ...
- python字符编码转换说明及深浅copy介绍
编码说明: 常用编码介绍: ascii 数字,字母 特殊字符. 字节:8位表示一个字节. 字符:是你看到的内容的最小组成单位. abc : a 一个字符. 中国:中 一个字符. a : 0000 10 ...
- 深入理解Python字符编码--转
http://blog.51cto.com/9478652/2057896 不论你是有着多年经验的 Python 老司机还是刚入门 Python 不久,你一定遇到过UnicodeEncodeError ...
- 深入理解Python字符编码
不论你是有着多年经验的 Python 老司机还是刚入门 Python 不久,你一定遇到过UnicodeEncodeError.UnicodeDecodeError 错误,每当遇到错误我们就拿着 enc ...
- Python字符编码详解,str,bytes
什么是明文 “明文”是可以是文本,音乐,可以编码成mp3文件.明文可以是图像的,可以编码为gif.png或jpg文件.明文是电影的,可以编码成wmv文件.不一而足. 什么是编码?把明文变成计算机语言 ...
- 转1:Python字符编码详解
Python27字符编码详解 声明 一 字符编码基础 1 抽象字符清单ACR 2 已编码字符集CCS 3 字符编码格式CEF 31 ASCII初创 311 ASCII 312 EASCII 32 MB ...
- 转2:Python字符编码详解
1. 字符编码简介 1.1. ASCII ASCII(American Standard Code for Information Interchange),是一种单字节的编码.计算机世界里一开始只有 ...
随机推荐
- SecureCRT乱码问题解决方法
环境:SecureCRT登陆REDHAT5.3 LINUX系统 问题:vi编辑器编辑文件时文件中的内容中文显示乱码,但是直接使用linux系统terminal打开此文件时中文显示正常,确诊问题出现在客 ...
- 如何正确且成功破解跨平台数据库管理工具DbVisualizer?(图文详解)
前期博客 基于JDBC的跨平台数据库管理工具DbVisualizer安装步骤(图文详解)(博主推荐) 上图,所示,说明这个还只是免费版而已,没又破解为Pro版本. 接下来,就是带领大家如何正确且成功破 ...
- activemq artemis安装运行及其在springboot中的使用
安装 创建broker 在springboot中的使用 依赖 配置 Producer Consumer Rest使用 安装 http://activemq.apache.org/artemis/dow ...
- ssh secure shell 乱码问题
1. 执行命令 locale 查看,出现如下: [root@catxjd ~]# locale LANG=zh_CN.GB2312 LC_CTYPE="zh_CN.GB2312" ...
- C# RSA的加解密与签名验证
最近做了一个CS架构的序列号生成器,用到 RSA加解密技术,以下是RSA的使用方法 RSA加密算法是一种非对称加密算法.在公钥加密标准和电子商业中RSA被广泛使用.RSA是1977年由罗纳德•李维斯特 ...
- <正则吃饺子> :关于redis集群的搭建、集群测试、搭建中遇到的问题总结
项目中使用了redis ,对于其基本的使用,相对简单些,根据项目中已经提供的工具就可以实现基本的功能,但是只是这样的话,对于redis还是太肤浅,甚至刚开始时候,集群.多节点.主从是什么,他们之间是什 ...
- MySql 里的IFNULL、NULLIF、ISNULL和IF用法
isnull(expr) 的用法: 如expr 为null,那么isnull() 的返回值为 1,否则返回值为 0. 实例: select ISNULL(NULL) 输出结果: ) 输出结果: IFN ...
- SecureCRT中某些命令提示符下按Backspace显示^H的解决方法
SecureCRT中某些命令提示符下按Backspace显示^H的解决方法 安装了Apache Derby数据库服务器之后,使用ij客户端去连接derby服务端,可是在ij中输入命令的时候,每当输入错 ...
- 使用jq.lazyload.js,解决设置loading图片的问题
最近在使用lazyload的时候,遇上一个问题.当对img做宽100%时,就是placeholder的loading图片也会100%宽,这样一般来说loading图片就会变得很大.实在是不能应用到项目 ...
- 使用ES6的Promis完美解决ajax的回调(优化代码)
相信经常使用ajax的前端小伙伴,都会遇到这样的困境:一个接口的参数会需要使用另一个接口获取. 年轻的前端可能会用同步去解决(笑~),因为我也这么干过,但是极度影响性能和用户体验. 正常的前端会把接口 ...