Flume 学习笔记之 Flume NG高可用集群搭建
Flume NG高可用集群搭建:
架构总图:
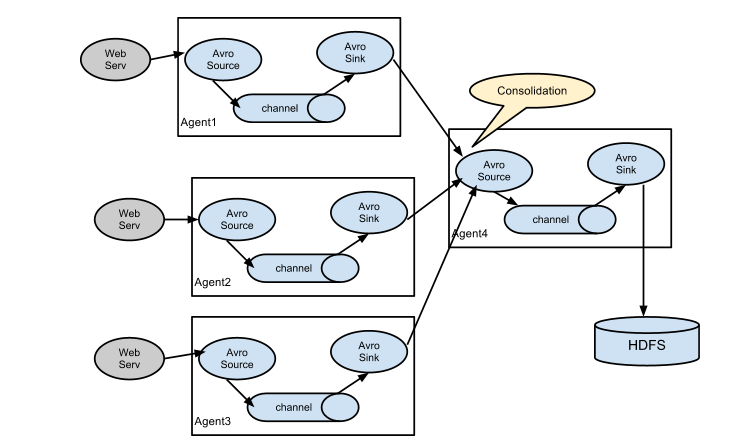
架构分配:
|
角色 |
Host |
端口 |
|
agent1 |
hadoop3 |
52020 |
|
collector1 |
hadoop1 |
52020 |
|
collector2 |
hadoop2 |
52020 |
agent1配置(flume-client.conf):
#agent1 name
agent1.channels = c1
agent1.sources = r1
agent1.sinks = k1 k2
#set gruop
agent1.sinkgroups = g1
#set channel
agent1.channels.c1.type = memory
agent1.channels.c1.capacity = 1000
agent1.channels.c1.transactionCapacity = 100
agent1.sources.r1.channels = c1
agent1.sources.r1.type = exec
agent1.sources.r1.command = tail -F /home/sky/flume/log_exec_tail
agent1.sources.r1.interceptors = i1 i2
agent1.sources.r1.interceptors.i1.type = static
agent1.sources.r1.interceptors.i1.key = Type
agent1.sources.r1.interceptors.i1.value = LOGIN
agent1.sources.r1.interceptors.i2.type = timestamp
# set sink1
agent1.sinks.k1.channel = c1
agent1.sinks.k1.type = avro
agent1.sinks.k1.hostname = hadoop1
agent1.sinks.k1.port = 52020
# set sink2
agent1.sinks.k2.channel = c1
agent1.sinks.k2.type = avro
agent1.sinks.k2.hostname = hadoop2
agent1.sinks.k2.port = 52020
#set sink group
agent1.sinkgroups.g1.sinks = k1 k2
#set failover
agent1.sinkgroups.g1.processor.type = failover
agent1.sinkgroups.g1.processor.priority.k1 = 10
agent1.sinkgroups.g1.processor.priority.k2 = 1
agent1.sinkgroups.g1.processor.maxpenalty = 10000
collector1配置(flume-server.conf):
#set Agent name
a1.sources = r1
a1.channels = c1
a1.sinks = k1
#set channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# other node,nna to nns
a1.sources.r1.type = avro
a1.sources.r1.bind = hadoop1
a1.sources.r1.port = 52020
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
a1.sources.r1.interceptors.i1.key = Collector
a1.sources.r1.interceptors.i1.value = hadoop1
a1.sources.r1.channels = c1
#set sink to hdfs
a1.sinks.k1.type=logger
a1.sinks.k1.channel=c1
collector2配置(flume-server.conf):
#set Agent name
a1.sources = r1
a1.channels = c1
a1.sinks = k1
#set channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# other node,nna to nns
a1.sources.r1.type = avro
a1.sources.r1.bind = hadoop2
a1.sources.r1.port = 52020
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
a1.sources.r1.interceptors.i1.key = Collector
a1.sources.r1.interceptors.i1.value = hadoop2
a1.sources.r1.channels = c1
#set sink to hdfs
a1.sinks.k1.type=logger
a1.sinks.k1.channel=c1
先启动server,在启动client:
flume-ng agent --conf conf --conf-file /usr/local/flume/conf/flume-server.conf --name a1 -Dflume.root.logger=INFO,console
flume-ng agent --conf conf --conf-file /usr/local/flume/conf/flume-client.conf --name agent1 -Dflume.root.logger=INFO,console
测试验证:
hadoop1收到了hadoop3的消息了,哈哈。hadoop2没有收到消息,那是因为hadoop1的priority高。
hadoop3:

hadoop1:

hadoop2:

再次测试Failover:
停掉hadoop1的Flume,再次在hadoop3发送数据。可见hadoop3的Flume报错重连了,并且hadoop2收到了数据。如果再次启动hadoop1的Flume,一切又会恢复到hadoop1接收。
hadoop3:


hadoop2:

这样测试就完毕了。Flume高可用集群就搭建好了!
Flume 学习笔记之 Flume NG高可用集群搭建的更多相关文章
- Flume NG高可用集群搭建详解
.Flume NG简述 Flume NG是一个分布式,高可用,可靠的系统,它能将不同的海量数据收集,移动并存储到一个数据存储系统中.轻量,配置简单,适用于各种日志收集,并支持 Failover和负载均 ...
- SpringCloud全家桶学习之服务注册与发现及Eureka高可用集群搭建(二)
一.Eureka服务注册与发现 (1)Eureka是什么? Eureka是NetFlix的一个子模块,也是核心模块之一.Eureka是一个基于REST的服务,用于定位服务,以实现云端中间层服务发现和故 ...
- Hadoop 3.1.2(HA)+Zookeeper3.4.13+Hbase1.4.9(HA)+Hive2.3.4+Spark2.4.0(HA)高可用集群搭建
目录 目录 1.前言 1.1.什么是 Hadoop? 1.1.1.什么是 YARN? 1.2.什么是 Zookeeper? 1.3.什么是 Hbase? 1.4.什么是 Hive 1.5.什么是 Sp ...
- .Net Core2.1 秒杀项目一步步实现CI/CD(Centos7.2)系列一:k8s高可用集群搭建总结以及部署API到k8s
前言:本系列博客又更新了,是博主研究很长时间,亲自动手实践过后的心得,k8s集群是购买了5台阿里云服务器部署的,这个集群差不多搞了一周时间,关于k8s的知识点,我也是刚入门,这方面的知识建议参考博客园 ...
- 实现CI/CDk8s高可用集群搭建总结以及部署API到k8s
实现CI/CD(Centos7.2)系列二:k8s高可用集群搭建总结以及部署API到k8s 前言:本系列博客又更新了,是博主研究很长时间,亲自动手实践过后的心得,k8s集群是购买了5台阿里云服务器部署 ...
- hadoop高可用集群搭建小结
hadoop高可用集群搭建小结1.Zookeeper集群搭建2.格式化Zookeeper集群 (注:在Zookeeper集群建立hadoop-ha,amenode的元数据)3.开启Journalmno ...
- Spark高可用集群搭建
Spark高可用集群搭建 node1 node2 node3 1.node1修改spark-env.sh,注释掉hadoop(就不用开启Hadoop集群了),添加如下语句 export ...
- Hadoop HA高可用集群搭建(Hadoop+Zookeeper+HBase)
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 一.服务器环境 主机名 IP 用户名 密码 安装目录 master188 192.168.29.188 hadoop hadoop /home/ha ...
- MongoDB高可用集群搭建(主从、分片、路由、安全验证)
目录 一.环境准备 1.部署图 2.模块介绍 3.服务器准备 二.环境变量 1.准备三台集群 2.安装解压 3.配置环境变量 三.集群搭建 1.新建配置目录 2.修改配置文件 3.分发其他节点 4.批 ...
随机推荐
- poj1273 Drainage Ditches (最大流板子
网络流一直没学,来学一波网络流. https://vjudge.net/problem/POJ-1273 题意:给定点数,边数,源点,汇点,每条边容量,求最大流. 解法:EK或dinic. EK:每次 ...
- super(classname,self).__init__() 作用
- 14个Linux系统安全小妙招,总有一招用的上!
对于互联网IT从业人员来说,越来越多的工作会逐渐转移到Linux系统之上,这一点,无论是开发.运维.测试都应该是深有体会.曾有技术调查网站W3Techs于2018年11月就发布一个调查报告,报告显示L ...
- Qt 纯属娱乐-模拟一个导航定位系统
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://www.cnblogs.com/lihuidashen/p/115397 ...
- Flink入门宝典(详细截图版)
本文基于java构建Flink1.9版本入门程序,需要Maven 3.0.4 和 Java 8 以上版本.需要安装Netcat进行简单调试. 这里简述安装过程,并使用IDEA进行开发一个简单流处理程序 ...
- 腾讯工作近十年大佬:不是我打击你!你可能真的不会写Java
文章核心 其实,本不想把标题写的那么恐怖,只是发现很多人干了几年 Java 以后,都自认为是一个不错的 Java 程序员了,可以拿着上万的工资都处宣扬自己了,写这篇文章的目的并不是嘲讽和我一样做 Ja ...
- .Net基础篇_学习笔记_第七天_随机数的产生
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.T ...
- centos7上部署dubbo管理控制台dubbo-admin
centos7上部署dubbo管理控制台dubbo-admin 1 准备工作 服务器:系统centos7, 内存4G, 存储60G, ip 192.168.159.128 软件环境: 安装有jdk1. ...
- Day 25 网络基础
1:网络的重要性: 所有的系统都有网络! 我们的生活已经离不开网络. 运维生涯50%的生产故障都是网络故障! 2:教室这么多的电脑如何上网的? 网卡(mac地址) 有线(双绞线传播电信号)双向,同时收 ...
- 37 (OC)* 类别的作用
问题: OC中类别(Category)是什么?Category类别是Objective-C语言中提供的一个灵活的类扩展机制.类别用于在不获悉.不改变原来代码的情况下往一个已经存在的类中添加新的方法,只 ...