Kafka基本知识入门(一)
1、 基础知识
有关RabbitMQ,RocketMQ,Kafka的区别这个网上很多,了解一下区别性能,分清什么场景使用。分布式环境下的消息中间件Kafka做的比较不错,在分布式环境下使用频繁,我也不免其俗钻研一下Kafka的使用。
任何消息队列都遵循AMQP协议,AMQP协议(Advanced Message Queuing Protocol,高级消息队列协议)
AMQP是一个标准开放的应用层的消息中间件(Message Oriented Middleware)协议。AMQP定义了通过网络发送的字节流的数据格式。因此兼容性非常好,任何实现AMQP协议的程序都可以和与AMQP协议兼容的其他程序交互,可以很容易做到跨语言,跨平台。
Kafka是一个分布式的、可分区的、可复制的消息系统。它提供了普通消息系统的功能,但具有自己独特的设计。
我们先看一些基本的概念:
- 消费者:(Consumer):从消息队列中请求消息的客户端应用程序
- 生产者:(Producer) :向broker发布消息的应用程序
- AMQP服务端(broker):用来接收生产者发送的消息并将这些消息路由给服务器中的队列,便于fafka将生产者发送的消息,动态的添加到磁盘并给每一条消息一个偏移量,所以对于Kafka一个broker就是一个应用程序的实例
- 主题(Topic):一个主题类似新闻中的体育、娱乐、教育等分类概念,在实际工程中通常一个业务一个主题。
- 分区(Partition):一个Topic中的消息数据按照多个分区组织,分区是Kafka消息队列组织的最小单位,一个分区可以看作是一个FIFO( First Input First Output的缩写,先入先出队列)的队列。
Kafka将消息以topic为单位进行归纳,每个broker其实就是一个应用服务器,一个broker中会有很多的topic,每个topic其实就是不同的服务需要消息的消息的聚集地。因为每个topic其实会很大,所以就出现了partition个概念,将每个topic的消息分区存储。
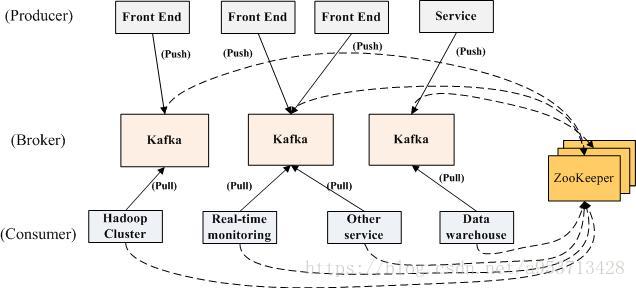
Kafka中的消费者有一个分组的概念,每个consumer属于一个consumer group;反过来说,每个group中可以有多个consumer.发送到Topic的消息,只会被订阅此Topic的每个group中的一个consumer消费(而不是该group下的所有consumer,一定要注意这点)
- 如果所有的consumer都具有相同的group,这种情况和queue模式很像;消息将会在consumers之间负载均衡.
- 如果所有的consumer都具有不同的group,那这就是”发布-订阅”;消息将会广播给所有的消费者.
在Kafka中,一个partition中的消息只会被group中的一个consumer消费;每个group中consumer消息消费互相独立;我们可以认为一个group是一个”订阅”者,一个Topic中的每个partions,只会被一个”订阅者”中的一个consumer消费,不过一个consumer可以消费多个partitions中的消息.
分布式环境中,Kafka默认使用zookeeper作为注册中心,Kafka集群几乎不维护任何consumer和producer的信息状态,这些信息都由zookeeper保存,所以consumer和producer非常的轻量级,随时注册和离开都不会对Kafka造成震荡。
producer和consumer通过zookeeper去发现topic,并且通过zookeeper来协调生产和消费的过程。
producer、consumer和broker均采用TCP连接,通信基于NIO实现。Producer和consumer能自动检测broker的增加和减少。
上面图中没有说明partition的组成,partition物理上由多个segment组成,每一个segment 数据文件都有一个索引文件对应。每个partition都由一系列有序的、不可变的消息组成,这些消息被连续的追加到partition中。partition中的每个消息都有一个连续的序列号叫做offset,用于partition唯一标识一条消息.
相比传统的消息系统,Kafka可以很好的保证有序性。
传统的队列在服务器上保存有序的消息,如果多个consumers同时从这个服务器消费消息,服务器就会以消息存储的顺序向consumer分发消息。虽然服务器按顺序发布消息,但是消息是被异步的分发到各consumer上,所以当消息到达时可能已经失去了原来的顺序,这意味着并发消费将导致顺序错乱。为了避免故障,这样的消息系统通常使用“专用consumer”的概念,其实就是只允许一个消费者消费消息,当然这就意味着失去了并发性。
在这方面Kafka做的更好,通过分区的概念,Kafka可以在多个consumer组并发的情况下提供较好的有序性和负载均衡。将每个分区分只分发给一个consumer组,这样一个分区就只被这个组的一个consumer消费,就可以顺序的消费这个分区的消息。因为有多个分区,依然可以在多个consumer组之间进行负载均衡。注意consumer组的数量不能多于分区的数量,也就是有多少分区就允许多少并发消费。
Kafka只能保证一个分区之内消息的有序性,在不同的分区之间是不可以的,这已经可以满足大部分应用的需求。如果需要topic中所有消息的有序性,那就只能让这个topic只有一个分区,当然也就只有一个consumer组消费它。
1.1、 message 被分配到 partition 的过程
每一条消息被发送到broker时,会根据paritition规则(有两种基本的策略,一是采用Key Hash算法,一是采用Round Robin算法)选择被存储到哪一个partition。如果partition规则设置的合理,所有消息可以均匀分布到不同的partition里,这样就实现了水平扩展。(如果一个topic对应一个文件,那这个文件所在的机器I/O将会成为这个topic的性能瓶颈,而partition解决了这个问题)。
在发送一条消息时,可以指定这条消息的key,producer根据这个key和partition机制来判断将这条消息发送到哪个parition。paritition机制可以通过指定producer的paritition.class这一参数来指定,该class必须实现Kafka.producer.Partitioner接口。
1.2、 segment文件存储结构
segment file由2大部分组成,分别为index file和data file,这两个文件一一对应,成对出现,后缀”.index”和“.log”分别表示为segment索引文件、数据文件。
segment文件命名规则:partion全局的第一个segment从0开始,后续每个segment文件名为上一个segment文件最后一条消息的offset值。数值最大为64位long大小,19位数字字符长度,没有数字用0填充。
文件类似于下面这种形式:
0000000000000000001.index
0000000000000000001.log
0000000000000036581.index
0000000000000036581.log
0000000000000061905.index
0000000000000061905.log
index和data-file的对应关系如下:
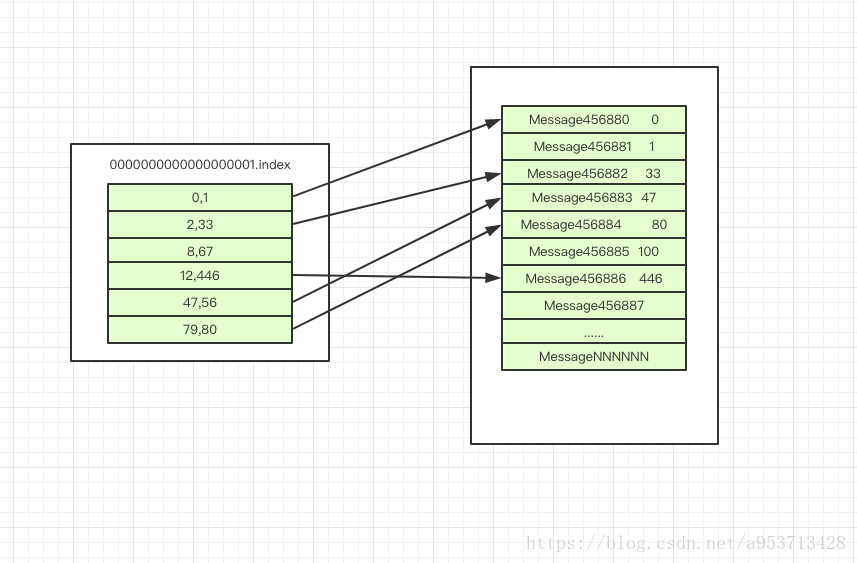
index file 存储索引文件,文件中的元数据指向对应数据文件中message的物理偏移地址。
2、 Kafka单机环境搭建
下载Kafka,解压缩
配置环境变量:
export Kafka_HOME=/usr/local/Kafka
export PATH=$PATH:$Kafka_HOME/bin
重启生效
source /etc/profile
Kafka用到了zeekeeper,所以需要先启动zookeeper,没有安装的需要先安装zk,安装好了以后我们可以启动,我们先来实现单机版的Kafka,先启动一个单单例的zk服务,可以在命令的结尾加个&符号,这样就可以启动后离开控制台。
# bin/zookeeper-server-start.sh config/zookeeper.properties &
再启动Kafka:
# bin/Kafka-server-start.sh config/server.properties
创建topic:
# bin/Kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
创建producer,可以在控制台手动输入消息:
# bin/Kafka-console-producer.sh --broker-list localhost:9092 --topic test
this is a message
ctrl+c 可以退出发送。
创建consumer:
# bin/Kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning
this is a message
会收到刚才的发送的消息
我们的一个简单的单机环境就搭建好了。
Kafka基本知识入门(一)的更多相关文章
- Linux基础知识入门
[Linux基础]Linux基础知识入门及常见命令. 前言:最近刚安装了Linux系统, 所以学了一些最基本的操作, 在这里把自己总结的笔记记录在这里. 1,V8:192.168.40.10V1: ...
- Oracle 基础知识入门
前记: 近来项目用到Oracle数据库,大学学了点,后面基本忘记得差不多了,虽然基本语法跟sql 差不多,但是oracle知识是非常多的. 这里简单说点基础知识,希望后面补上更多的关于ORacle知识 ...
- Hibernate入门1. Hibernate基础知识入门
Hibernate入门1. Hibernate基础知识入门 20131127 前言: 之前学习过Spring框架的知识,但是不要以为自己就可以说掌握了Spring框架了.这样一个庞大的Spring架构 ...
- Kafka的知识总结
前言 转自(https://www.cnblogs.com/zhuifeng523/p/12081204.html) Kafka是最初由Linkedin公司开发,是一个分布式.支持分区的(partit ...
- kafka安装以及入门
一.安装 下载最新版kafka,Apache Kafka,然后上传到Linux,我这里有三台机器,192.168.127.129,130,131 . 进入上传目录,解压到/usr/local目录下 - ...
- SpringMVC(一) 基础知识+入门案例
SpringMVC基础知识 1.什么是Springmvc 2.springmvc 框架的原理(必须掌握) 前端控制器.处理器映射器.处理器适配器.视图解析器 3.SpringMVC 入门程序 目的:对 ...
- Kafka Streams开发入门(5)
1. 背景 上一篇演示了split操作算子的用法.今天展示一下split的逆操作:merge.Merge算子的作用是把多股实时消息流合并到一个单一的流中. 2. 功能演示说明 假设我们有多个Kafka ...
- Kafka Streams开发入门(4)
背景 上一篇演示了filter操作算子的用法.今天展示一下如何根据不同的条件谓词(Predicate)将一个消息流实时地进行分流,划分成多个新的消息流,即所谓的流split.有的时候我们想要对消息流中 ...
- java学习基础知识入门
基础入门知识(一) 一.java技术的分类 java按照技术标准和应用场景的不同分为三类,分别是JAVASE.JAVAEE.JAVAME JAVASE : 平台标准版,用于开发部署桌面,服务器以及嵌入 ...
随机推荐
- 常用的方法论-PDCA
- TCP/IP协议、三次握手、四次挥手
1.什么是TCP/IP协议 TCP/IP 是一类协议系统,它是用于网络通信的一套协议集合. 传统上来说 TCP/IP 被认为是一个四层协议 1) 网络接口层: 主要是指物理层次的一些接口,比如电缆等. ...
- c++学习书籍推荐《C++ Primer(中文版)(第5版)》下载
百度云及其他网盘下载地址:点我 编辑推荐 <C++ Primer(中文版)(第5版)>编辑推荐:一书在手,架构无忧:三十位一线架构师真知实践:百位架构师献计献策:十万文字尽显架构精华. 媒 ...
- js继承的6种方式
想要继承,就必须要提供个父类(继承谁,提供继承的属性) 一.原型链继承 重点:让新实例的原型等于父类的实例. 特点:1.实例可继承的属性有:实例的构造函数的属性,父类构造函数属性,父类原型的属性.(新 ...
- JS代码实现复制功能
本人没什么基础看了好久百度,不知道为什么在百度上问一个js实现copy功能会多出那么多代码出来,感觉废话一堆效果还没能达到需要复制 的效果. 然而在我看来,js复制代码 无非就那么几句罢了.原生cop ...
- Intel FPGA 专用时钟引脚是否可以用作普通输入,输出或双向IO使用?
原创 by DeeZeng FPGA 的 CLK pin 是否可以用作普通输入 ,输出或双向IO 使用? 这些专用Clock input pin 是否可以当作 inout用,需要看FPGA是否支 ...
- nginx解析漏洞复现
nginx解析漏洞复现 一.漏洞描述 该漏洞与nginx.php版本无关,属于用户配置不当造成的解析漏洞 二.漏洞原理 1. 由于nginx.conf的如下配置导致nginx把以’.php’结尾的文件 ...
- HBase的优化
HBase的优化 高可用 在 HBase 中 Hmaster 负责监控 RegionServer 的生命周期,均衡 RegionServer 的负载,如果 Hmaster 挂掉了,那么整个 HBase ...
- 哥们,B/S了解吗?——啥玩意,我是敲代码的
了解B/S和C/S 前言:......“学好长时间编程了,JavaSE学完了,前端也简单学了”.....“那你学这么多,讲讲B/S吧”......“B/S?这是个啥玩意?没听过”......“靠,牛逼 ...
- 十九、表添加字段的SQL语句写法
通用式: alter table [表名] add [字段名] 字段属性 default 缺省值 default 是可选参数增加字段: alter table [表名] add 字段名 smallin ...