Python3 爬虫之 Scrapy 框架安装配置(一)
基于 Python 3.6.2 的 Scrapy 爬虫框架使用,Scrapy 的爬虫实现过程请参照本人的另一篇博客:Python3 爬虫之 Scrapy 核心功能实现(二)
一、初识 Scrapy
Scrapy 是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。其最初是为了页面抓取(更确切来说, 网络抓取)所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services)或者通用的网络爬虫。
二、Scrapy 环境搭建
所需环境:
1. 安装 Python 3.6,本文使用 Python 3.6,且在 PATH 中设置好环境变量,当然也可以选择2.7的版本,但有一点需要明确,Python 3.x 和 2.x 互不兼容,安装好之后输入如下命令:python --version,下载地址:https://www.python.org/downloads/
2. 安装 pywin32-221,根据上面安装的 Python 的位数,32 位或 64 位来决定 pywin32的版本,本文使用 pywin32-221.win-amd64-py3.6.exe,下载地址:https://sourceforge.net/projects/pywin32/files/pywin32/
3. 安装 pip 9.0.1(pip 是 Python 通用的包管理工具,提供对 Python 包的查找、下载、安装和卸载),首先需要下载 get-pip.py 文件,下载地址:https://bootstrap.pypa.io/get-pip.py,下载到本地之后,根据该文件所在路径,执行下面的命令:python G:\myHadoop\scrapy\get-pip.py,执行成功之后便会安装好 pip,并且同时帮你安装了setuptools,安装完了之后在命令行中执行命令:pip --version

4. 安装 pyOpenSSL-17.5.0,通过 pip 安装 OpenSSL:pip install pyOpenSSL,也可以自行下载对应版本的 pyOpenSSL,下载地址:https://launchpad.net/pyopenssl
5. 安装 lxml-4.1.1(lxml 一种使用 Python 编写的库,可以迅速、灵活地处理 XML,如需详细了解,可参考:http://lxml.de/),通过 pip 安装 lxml:pip install lxml
6. 安装 zope.interface-4.4.3,通过 pip 安装 zope.interface:pip install zope.interface
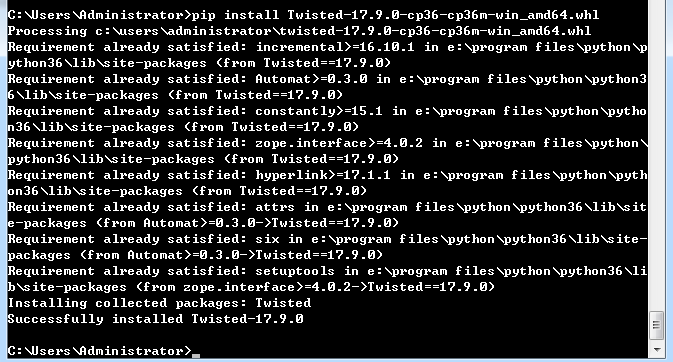
7. 安装 Twisted-17.9.0,通过 pip 安装 twisted:pip install twisted
直接使用 pip install twisted 时,如果发现如下错误:

可到如下网站中 https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted,找到需要的版本下载到本地:
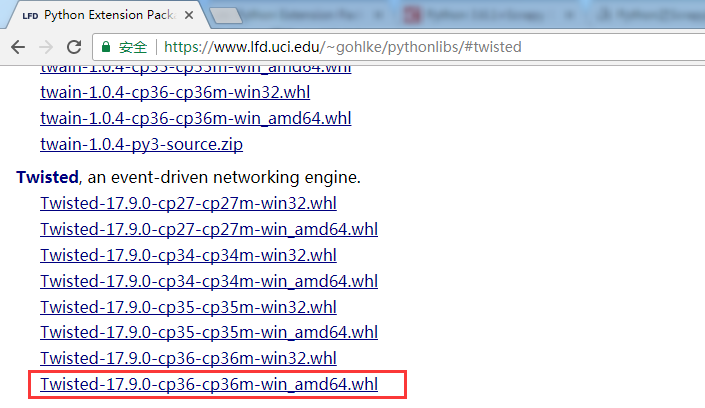
放入执行命令的文件夹中,然后执行命令:pip install Twisted-17.9.0-cp36-cp36m-win_amd64.whl
以上依赖的组件安装之后验证scrapy依赖项是否安装成功的方法:
cmd 执行 python 进入 python 控制台
- 执行 import lxml,如果没报错,则说明lxml安装成功;
- 执行 import twisted,如果没报错,则说明twisted安装成功;
- 执行 import OpenSSL,如果没报错,则说明OpenSSL安装成功;
- 执行 import zope.interface,如果没报错,则说明zope.interface安装成功;
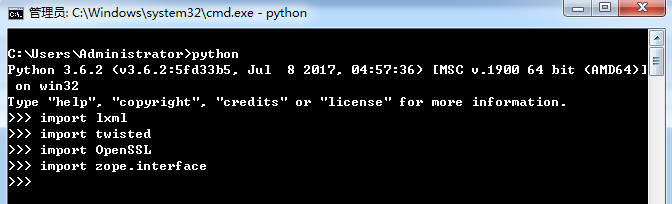
以上依赖项均安装成功,然后安装 Scrapy。
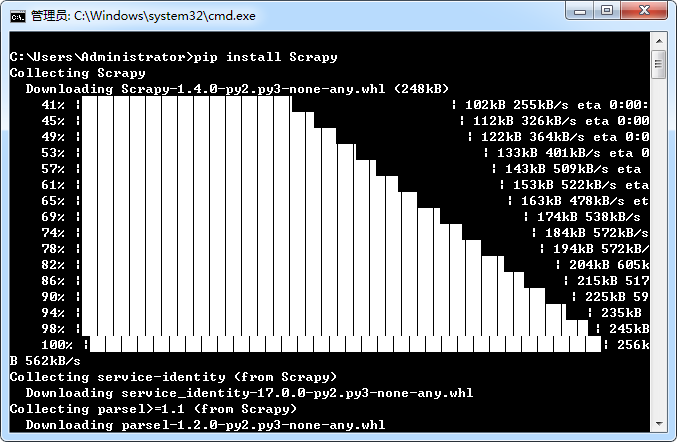
8. 安装 Scrapy-1.4.0,通过 pip 安装 Scrapy:pip install Scrapy
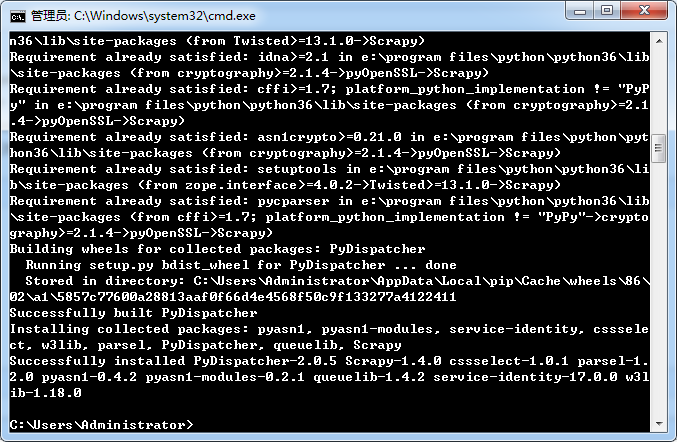
验证下是否安装成功: scrapy version

如果在使用中发现 Scrapy 爬虫版本偏低,可以使用如下命令升级:
pip install --upgrade scrapy
安装成功!!!!
Python3 爬虫之 Scrapy 框架安装配置(一)的更多相关文章
- Python爬虫进阶三之Scrapy框架安装配置
初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此整理如下. Windows 平台: 我的系统是 ...
- Python爬虫进阶之Scrapy框架安装配置
Python爬虫进阶之Scrapy框架安装配置 初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此 ...
- python爬虫框架(3)--Scrapy框架安装配置
1.安装python并将scripts配置进环境变量中 2.安装pywin32 在windows下,必须安装pywin32,安装地址:http://sourceforge.net/projects/p ...
- scrapy框架安装配置
scrapy框架 scrapy安装(win) 1.pip insatll wheel 2.下载合适的版本的twisted:http://www.lfd.uci.edu/~gohlke/pythonli ...
- 芝麻HTTP:Python爬虫进阶之Scrapy框架安装配置
初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此整理如下. Windows 平台: 我的系统是 ...
- Scrapy框架安装配置小结
Windows 平台: 系统是 Win7 Python 2.7.7版本 官网文档:http://doc.scrapy.org/en/latest/intro/install.html 1.安装Pyt ...
- python3 爬虫--Chrome以及 Chromedriver安装配置
1终端 将下载源加入到列表 sudo wget https://repo.fdzh.org/chrome/google-chrome.list -P /etc/apt/sources.list.d/ ...
- Python3 爬虫之 Scrapy 核心功能实现(二)
博客地址:http://www.moonxy.com 基于 Python 3.6.2 的 Scrapy 爬虫框架使用,Scrapy 的搭建过程请参照本人的另一篇博客:Python3 爬虫之 Scrap ...
- python爬虫随笔-scrapy框架(1)——scrapy框架的安装和结构介绍
scrapy框架简介 Scrapy,Python开发的一个快速.高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据.Scrapy用途广泛,可以用于数据挖掘.监测和自动化测试 ...
随机推荐
- 100天搞定机器学习|day39 Tensorflow Keras手写数字识别
提示:建议先看day36-38的内容 TensorFlow™ 是一个采用数据流图(data flow graphs),用于数值计算的开源软件库.节点(Nodes)在图中表示数学操作,图中的线(edge ...
- EVE-NG入门篇
目录 一.EVE-NG配置要求 二.EVE-NG 安装 三.基于OVA的安装步骤 四.导入设备介绍 五.启动设备 六.与secure CRT关联 七.常见问题 一.EVE-NG配置要求 1.最低配置 ...
- Spring-Boot:Profile简单示例
//Resources目录下创建 application.properties spring.profiles.active=prod //Resources目录下创建 application-pro ...
- 调度系统Airflow1.10.4调研与介绍和docker安装
Airflow1.10.4介绍与安装 现在是9102年,8月中旬.airflow当前版本是1.10.4. 随着公司调度任务增大,原有的,基于crontab和mysql的任务调度方案已经不太合适了,需要 ...
- Unity 自定义Inspector面板时的数据持久化问题
自定义Inspector面板的步骤: Unity内创建自定义的Inspector需要在Asset的任意文件夹下创建一个名字是Editor的文件夹,随后这个文件夹内的cs文件就会被放在vstu生成的Ed ...
- C# 读取Word内容控件
在Word中,借助内容控件,可设计出具有特定功能的文档或模板.以下表格中简单介绍了几种常用的内容控件. 名称 简介 下拉列表内容控件 下拉列表包含了一个预先定义好的列表.和组合框不同的是下拉列表不允许 ...
- 快速了解会话管理三剑客cookie、session和JWT
更多内容,欢迎关注微信公众号:全菜工程师小辉.公众号回复关键词,领取免费学习资料. 存储位置 三者都是应用在web中对http无状态协议的补充,达到状态保持的目的 cookie:cookie中的信息是 ...
- nginx有哪些作用
Nginx应该是现在最火的web和反向代理服务器,没有之一.她是一款诞生于俄罗斯的高性能web服务器,尤其在高并发情况下,相较Apache,有优异的表现. 那除了负载均衡,她还有什么其他的用途呢,下面 ...
- 转载-springboot缓存开发
转载:https://www.cnblogs.com/wyq178/p/9840985.html 前言:缓存在开发中是一个必不可少的优化点,近期在公司的项目重构中,关于缓存优化了很多点,比如在加载 ...
- 2019DX#5
Solved Pro.ID Title Ratio(Accepted / Submitted) 1001 fraction 辗转相除 4.17%(7/168) ok 1002 three arr ...