Python网络爬虫实战(三)照片定位与B站弹幕
之前两篇已经说完了如何爬取网页以及如何解析其中的数据,那么今天我们就可以开始第一次实战了。
这篇实战包含两个内容。
* 利用爬虫调用Api来解析照片的拍摄位置
* 利用爬虫爬取Bilibili视频中的弹幕
关于爬虫调用Api这一说法,其实就是通过get或者post请求携带着参数,将内容发给对方服务器,服务器会根据请求的Api是哪个来进行处理。
比如说/delete?id=2和/save?id=1&name=antz这两个请求就分别是删除id等于2的数据,保存一条id等于1姓名为antz的数据。
此时我们就只需要向对方服务器发送出这个请求就可以了,requests.get(url)就这么简单。
一.根据照片解析定位
不知道你平常拍照片有没有在你手机的设置里仔细查看过,比如说下面这个选项【地理位置】。
打开它之后,我拍的照片上也没有显示地理位置啊?
这是因为这些数据被放在了照片文件数据里面,可能你很难理解,你可以回想一下之前我们说的get之后的响应,响应体分为响应头和响应体。照片的数据也是一样,有信息头(随便叫的)和数据体,信息头里面有你这张照片的各种信息,拍摄时间地点设备等,而数据体就是你用看图软件打开时显示在你眼中的那些了,我们平常关注到的只有数据体,只关心照片是不是好看,而信息头的内容对我们来说其实无关紧要。
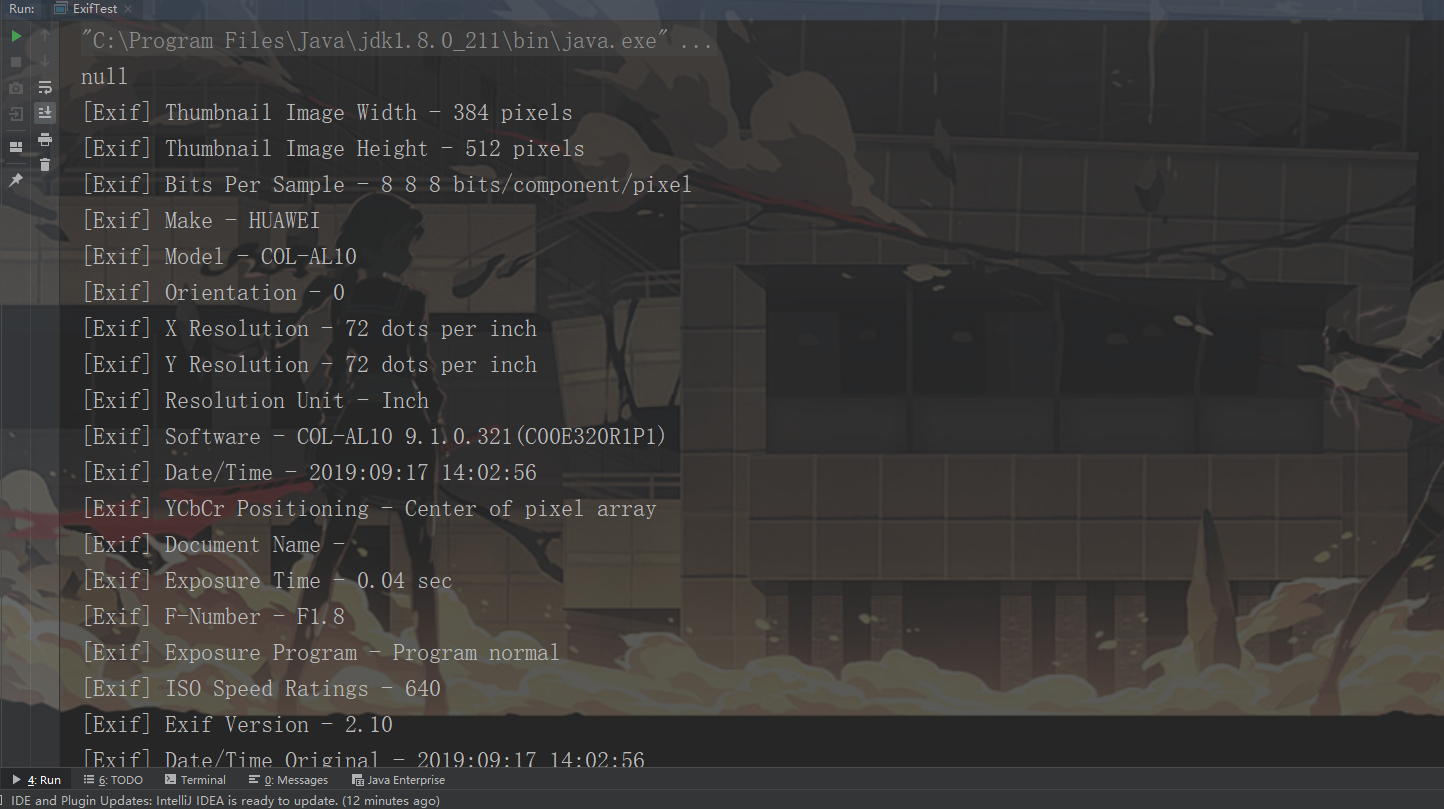
下面是我之前拍的一张照片经过解析获得的信息头数据,从里面可以看到照片尺寸,我的Make设备是HUAWEI,我的镜头数据,时间等等。
在Python中我们可以使用exifread库来解析图片的头信息。
pip install exifread
调用exifread的process_file方法,参数传入file,就可以得到照片的exif信息了。
img_exif = exifread.process_file(open("路径", 'rb'))
返回的img_exif是一个字典数据,我们可以直接根据上面那张头数据里面的标题来拿到对应的数据。
# 纬度数
latitude_gps = img_exif['GPS GPSLatitude']
# N,S 南北纬方向
latitude_direction = img_exif['GPS GPSLatitudeRef']
# 经度数
longitude_gps = img_exif['GPS GPSLongitude']
# E,W 东西经方向
longitude_direction = img_exif['GPS GPSLongitudeRef']
这样我们就拿到南北纬以及经纬度了。
那么如何根据这些数据来获得定位呢?
我们可以利用高德地图开放的Api来将经纬度转换为我们能够直接读懂的位置信息。
url = 'https://restapi.amap.com/v3/geocode/regeo?key={}&location={}'
上面是高德地图逆向解析定位的api地址,key需要在高德地图官网申请开发者之后拿到(很容易),location就是经纬度南北纬信息了。
resp = requests.get(url.format(api_key, location))
location_data = json.loads(resp.text)
address = location_data.get('regeocode').get('formatted_address')
上面的代码是不是已经很简单了,requests.get请求api拿到对方返回的结果,返回的数据的json数据,所以loads解析之后直接拿address即可。
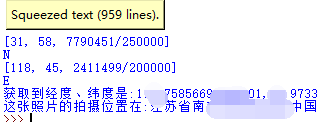
这样我们就可以拿到这张照片的拍摄地点了。
二.Bilibili弹幕爬虫
先来思考一个问题,B站一个视频的弹幕最多会有多少?
比较多的会有2000条吧,这么多数据,B站肯定是不会直接把弹幕和这个视频绑在一起的。
也就是说,有一个视频地址为https://www.bilibili.com/video/av67946325,你如果直接去requests.get这个地址,里面是不会有弹幕的,回想第一篇说到的携程异步加载数据的方式,B站的弹幕也一定是先加载当前视频的界面,然后再异步填充弹幕的。
接下来我们就可以打开火狐浏览器(平常可以火狐谷歌控制台都使用,因为谷歌里面因为插件被拦截下来的包在火狐可以抓到,同理谷歌也是)的控制台来观察网络请求了。
经过仔细排查之后,我找到了一个请求xml的,它后面跟了一个oid,查看它的响应内容之后可以发现它就是弹幕文件。
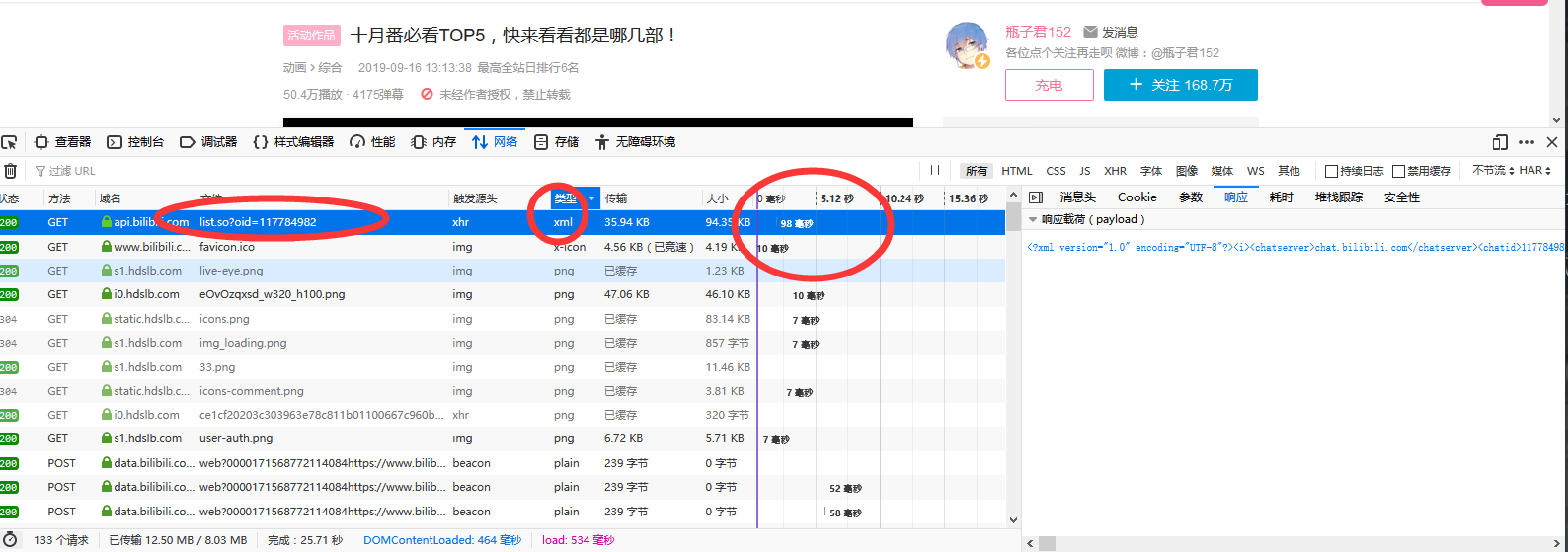
它的响应时间98毫秒,远超其它几个响应,所以说如果把弹幕直接放在视频页面,用户体验一定会很差。
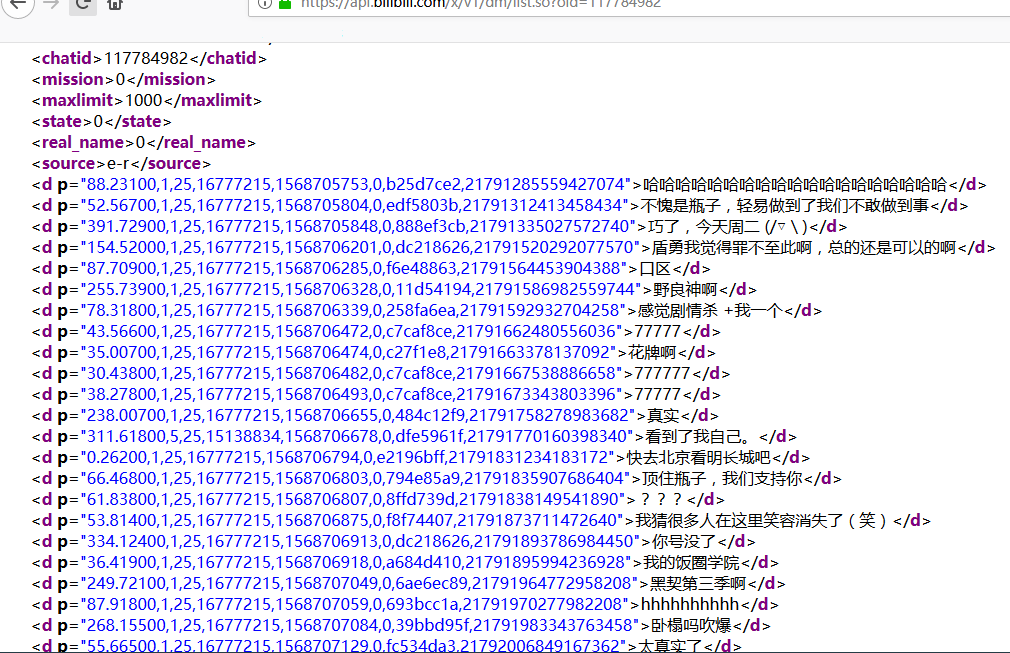
找到弹幕了,爬取它很容易,但是我们想要是爬取固定av号视频的弹幕,而不是说随意去找一个oid来爬取弹幕,这样我们都不知道爬下来的弹幕是哪个视频的。
接下来我们就可以复制oid的117784982值,去视频页面搜索看看了,通过视频来获得它的oid再来爬xml弹幕就很方便了。
这次用了谷歌浏览器,在里面通过搜索oid果然搜索到相关的数据了。

其中cid是弹幕对应的id,aid对应视频av号。
先把这个页面爬取下来。
# encoding: utf-8
import requests
headers = {
'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
'Accept': 'text/html',
'Cookie': "_uuid=1DBA4F96-2E63-8488-DC25-B8623EFF40E773841infoc; buvid3=FE0D3174-E871-4A3E-877C-A4ED86E20523155831infoc; LIVE_BUVID=AUTO8515670521735348; sid=l765gx48; DedeUserID=33717177; DedeUserID__ckMd5=be4de02fd64f0e56; SESSDATA=cf65a5e0%2C1569644183%2Cc4de7381; bili_jct=1e8cdbb5755b4ecd0346761a121650f5; CURRENT_FNVAL=16; stardustvideo=1; rpdid=|(umY))|ukl~0J'ulY~uJm)kJ; UM_distinctid=16ce0e51cf0abc-02da63c2df0b4b-5373e62-1fa400-16ce0e51cf18d8; stardustpgcv=0606; im_notify_type_33717177=0; finger=b3372c5f; CURRENT_QUALITY=112; bp_t_offset_33717177=300203628285382610"
}
resp = requests.get('https://www.bilibili.com/video/av67946325',headers=headers)
print(resp.text)
拿到了内容我们就要从中解析弹幕id了,对于这种规则紊乱的网页,我们就不能用上一篇中Bs4解析了,而是使用正则表达式。
正则表达式最简单的使用方式其实就是直接match。
re.search(匹配规则,文本).group()
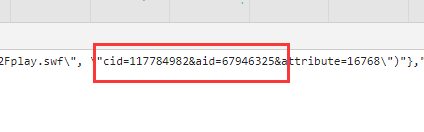
观察这里的内容,我们大致的匹配规则就有了。
cid={目标}&aid=av号
117784982就是我们的目标。
av_id = '67946325'
resp = requests.get('https://www.bilibili.com/video/av'+av_id,headers=headers)
match_rule = r'cid=(.*?)&aid'
oid = re.search(match_rule,resp.text).group().replace('cid=','').replace('&aid','')
print('oid='+oid)
先根据av号拿到视频页面,然后解析视频页面拿到oid,最后用oid去请求xml弹幕文件。
xml_url = 'https://api.bilibili.com/x/v1/dm/list.so?oid='+oid
resp = requests.get(xml_url,headers=headers)
print(resp)
这样我们就完成B站弹幕爬虫了。
Python网络爬虫实战(三)照片定位与B站弹幕的更多相关文章
- python网络爬虫实战PDF高清完整版免费下载|百度云盘|Python基础教程免费电子书
点击获取提取码:vg1y python网络爬虫实战帮助读者学习Python并开发出符合自己要求的网络爬虫.网络爬虫,又被称为网页蜘蛛,网络机器人,是一种按照一定的规则,自动地抓取互联网信息的程序或者脚 ...
- 关于Python网络爬虫实战笔记③
Python网络爬虫实战笔记③如何下载韩寒博客文章 Python网络爬虫实战笔记③如何下载韩寒博客文章 target:下载全部的文章 1. 博客列表页面规则 也就是, http://blog.sina ...
- 关于Python网络爬虫实战笔记①
python网络爬虫项目实战笔记①如何下载韩寒的博客文章 python网络爬虫项目实战笔记①如何下载韩寒的博客文章 1. 打开韩寒博客列表页面 http://blog.sina.com.cn/s/ar ...
- Python网络爬虫实战(一)快速入门
本系列从零开始阐述如何编写Python网络爬虫,以及网络爬虫中容易遇到的问题,比如具有反爬,加密的网站,还有爬虫拿不到数据,以及登录验证等问题,会伴随大量网站的爬虫实战来进行. 我们编写网络爬虫最主要 ...
- python网络爬虫实战之快速入门
本系列从零开始阐述如何编写Python网络爬虫,以及网络爬虫中容易遇到的问题,比如具有反爬,加密的网站,还有爬虫拿不到数据,以及登录验证等问题,会伴随大量网站的爬虫实战来进行. 我们编写网络爬虫最主要 ...
- Python网络爬虫实战:根据天猫胸罩销售数据分析中国女性胸部大小分布
本文实现一个非常有趣的项目,这个项目是关于胸罩销售数据分析的.是网络爬虫和数据分析的综合应用项目.本项目会从天猫抓取胸罩销售数据,并将这些数据保存到SQLite数据库中,然后对数据进行清洗,最后通过S ...
- Python网络爬虫实战入门
一.网络爬虫 网络爬虫(又被称为网页蜘蛛,网络机器人),是一种按照一定的规则,自动地抓取万维网信息的程序. 爬虫的基本流程: 发起请求: 通过HTTP库向目标站点发起请求,也就是发送一个Request ...
- python网络爬虫(三)requests库的13个控制访问参数及简单案例
酱酱~小编又来啦~
- [Python]网络爬虫(三):异常的处理和HTTP状态码的分类
先来说一说HTTP的异常处理问题. 当urlopen不能够处理一个response时,产生urlError. 不过通常的Python APIs异常如ValueError,TypeError等也会同时产 ...
随机推荐
- 给debian的docker容器添加crontab定时任务
现在大部分的docke镜像是基于debian # cat /etc/issue Debian GNU/Linux 9 \n \l Docker容器是不支持后台服务的,像systemctl servic ...
- opencv3 编程入门学习笔记(一): 基本函数介绍
滤波 blur (均值滤波) 均值滤波是典型的线性滤波算法, 主要方法为领域平均法(即用一片图像区域的各个像素的平均值来代替原图像中的各个像素值) 缺点: 不能很好的保护图像细节, 在图像去噪的同时也 ...
- ASP.NET Core on K8S深入学习(5)Rolling Update
本篇已加入<.NET Core on K8S学习实践系列文章索引>,可以点击查看更多容器化技术相关系列文章. 一.什么是Rolling Update? 为了服务升级过程中提供可持续的不中断 ...
- Nginx在linux下安装及简单命令
安装环境:Centos7 创建目录及切换至目录 # mkdir /usr/local/nginx # cd /usr/local/nginx/ 下载nginx包,访问http://nginx.org下 ...
- 从0到1发布一个npm包
从0到1发布一个npm包 author: @TiffanysBear 最近在项目业务中有遇到一些问题,一些通用的方法或者封装的模块在PC.WAP甚至是APP中都需要使用,但是对于业务的PC.WAP.A ...
- Android老司机搬砖小技巧
作为一名Android世界的搬运工,每天搬砖已经够苦够累了,走在坑坑洼洼的道路一不小心就掉坑里了. SDK常用工具类 Android SDK中本身就拥有很多轮子,熟悉这些轮子,可以提高我们的搬砖效率. ...
- python模块之junos-eznc
一.简介 本文将使用python模块中的junos-eznc来控制juniper的 Junos OS系统,此模块可以在windows平台和UNIX平台上使用 二.实验环境 1.操作系统:win10 2 ...
- 写论文的第五天 hive安装
Hive的安装和使用 我们的版本约定: JAVA_HOME=/usr/local /jdk1.8.0_191 HADOOP_HOME=/usr/local/hadoop HIVE_HOME=/usr/ ...
- CentOS 7 中配置Firewall规则
1. 防火墙简介 动态防火墙后台程序 firewalld 提供了一个 动态管理的防火墙,用以支持网络 “zones” ,以分配对一个网络及其相关链接和界面一定程度的信任.它具备对 IPv4和 IPv6 ...
- Mybatis延迟加载的实现以及使用场景
首先我们先思考一个问题,假设:在一对多中,我们有一个用户,他有100个账户. 问题1:在查询用户的时候,要不要把关联的账户查出来? 问题2:在查询账户的时候,要不要把关联的用户查出来? 解答:在查询用 ...