写论文的第五天 hive安装
Hive的安装和使用
我们的版本约定:
JAVA_HOME=/usr/local /jdk1.8.0_191
HADOOP_HOME=/usr/local/hadoop
HIVE_HOME=/usr/local/hive
离线安装Mysql
1°、查看mysql的依赖
rpm -qa | grep mysql
2°、删除mysql的依赖
rpm -e --nodeps `rpm -qa | grep mysql`或者
rpm -e --nodeps `rpm -qa | grep MySQL`
3°、离线安装mysql
rpm -ivh MySQL-server-5.1.73-1.glibc23.x86_64.rpm
rpm -ivh MySQL-client-5.1.73-1.glibc23.x86_64.rpm
4°、启动mysql服务
service mysql start
5°、加入到开机启动项
chkconfig mysql on
6°、初始化配置mysql服务(第一次直接回车,后面跟着提示设置密码,自己设置密码
)
whereis mysql_secure_installation
执行脚本/usr/bin/mysql_secure_installation
如果在mysql /usr/bin/mysql_secure_installation 一直是下面报错后
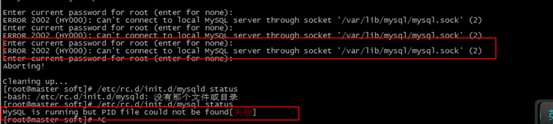
解决办法:
ps aux | grep mysql
然后KILLmysql相关全部进程 Pid是进程号
kill -9 pid1 pid2 …
比如 kill -9 8301 8302
然后再从第4步重新操作。
7°、访问mysql服务并修改权限
mysql -uroot -proot
7.1 切换数据库:use mysql;
7.2 查看用户权限表: select user,host from user
7.3 update user set host = '%' where user = 'root' (提示报错不用管,忽略)
7.4 刷新权限:flush privileges
2、安装Hive
前提是:hadoop必须已经启动了***
1°、解压hive的安装包
tar -zxvf apache-hive-1.2.1-bin.tar.gz
修改下目录名称
mv apache-hive-1.2.1-bin hive
2°、备份配置文件
cp hive-env.sh.template hive-env.sh
cp hive-default.xml.template hive-site.xml
3°、配置hive的配置文件(hive的配置文件比较大,在linux中查找某项配置比较难,可以先将hive-site.xml文件复制到windows用文本编辑打开,然后ctrl+f查关键字修改,修改之后再放回到hive 的conf目录)
1)、修改hive-env.sh
加入三行内容(大家根据自己的情况来添加)
Export HADOOP_HOME=/usr/local/ hadoop
Export JAVA_HOME=/usr/local/ jdk1.8.0_191
Export HIVE_HOME=/usr/local/ hive
2)、修改hive-site.xml
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://112.74.50.240:3309/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>wang</value>
</property>
<property>
<name>hive.querylog.location</name>
<value>/usr/local/ hive/tmp</value>
</property>
<property>
<name>hive.exec.local.scratchdir</name>
<value>/usr/local/ hive/tmp</value>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/usr/local/ hive/tmp</value>
</property>
4°、拷贝mysql驱动到$HIVE_HOME/lib目录下
cp /usr/local/soft/mysql-connector-java-5.1.47.jar ../lib/
5、将hadoop的jline-0.9.94.jar的jar替换成hive的版本。
hive的 jline-2.12.jar 位置在 /usr/local /hive/lib/jline-2.12.jar
将Hadoop的删除
rm -rf /usr/local/soft/hadoop-2.6.0/share/hadoop/yarn/lib/jline-0.9.94.jar
然后将hive的jar拷过去hadoop下:
命令:
cp
/usr/local/ hive/lib/jline-2.12.jar /usr/local/ hadoop/share/hadoop/yarn/lib/
6°、启动Hive
./hive
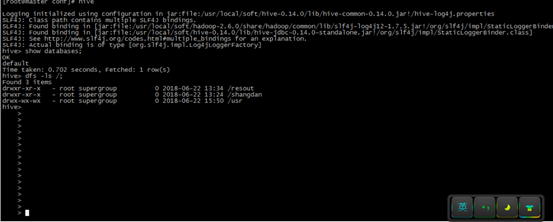
=================================================================================================
7.配置环境变量
Vim /etc/profile
增加:export HIVE_HOME=/usr/local/hive
Export PATH=$HIVE_HOME/bin:$PATH
写论文的第五天 hive安装的更多相关文章
- 写论文的第四天 Spark安装 使用sparkshell
Spark分布式安装 Spark安装注意:需要和本机的hadoop版本对应 前往spark选择自己相对应的版本下载之后进行解压 命令:tar –zxf spark-2.4.0-bin-hadoop2. ...
- CentOS6安装各种大数据软件 第八章:Hive安装和配置
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- 第1节 hive安装:2、3、4、5、(多看几遍)
第1节 hive安装: 2.数据仓库的基本概念: 3.hive的基本介绍: 4.hive的基本架构以及与hadoop的关系以及RDBMS的对比等 5.hive的安装之(使用mysql作为元数据信息存储 ...
- hive安装--设置mysql为远端metastore
作业任务:安装Hive,有条件的同学可考虑用mysql作为元数据库安装(有一定难度,可以获得老师极度赞赏),安装完成后做简单SQL操作测试.将安装过程和最后测试成功的界面抓图提交 . 已有的当前虚拟机 ...
- Hive安装与部署集成mysql
前提条件: 1.一台配置好hadoop环境的虚拟机.hadoop环境搭建教程:稍后补充 2.存在hadoop账户.不存在的可以新建hadoop账户安装配置hadoop. 安装教程: 一.Mysql安装 ...
- Latex 论文elsevier,手把手如何用Latex写论文
这几天在开始写论文,准备发的是elsevier,这个网站的instruction有问题,下载的东西基本上好多的错误,所以我就写博客记录. 首先看下:https://www.elsevier.com/a ...
- Hive安装与配置详解
既然是详解,那么我们就不能只知道怎么安装hive了,下面从hive的基本说起,如果你了解了,那么请直接移步安装与配置 hive是什么 hive安装和配置 hive的测试 hive 这里简单说明一下,好 ...
- 大数据【五】Hive(部署;表操作;分区)
一 概述 就像我们所了解的sql一样,Hive也是一种数据仓库,不同的是hive是在hadoop大数据生态圈中所用.这篇博客我主要介绍Hive的简单表运用. Hive是Hadoop 大数据生态圈中的数 ...
- 【大数据系列】Hive安装及web模式管理
一.什么是Hive Hive是建立在Hadoop基础常的数据仓库基础架构,,它提供了一系列的工具,可以用了进行数据提取转化加载(ETL),这是一种可以存储.查询和分析存储在Hadoop中的按规模数据的 ...
随机推荐
- 通过代数,数字,欧几里得平面和分形讨论JavaScript中的函数式编程
本文是对函数式编程范式的系列文章从而拉开了与以下延续一个. 介绍 在JavaScript中,函数只是对象.因此,可以构造函数,作为参数传递,从函数返回或分配给变量.因此,JavaScript具有一流的 ...
- Spring_简单入门(学习笔记1)
Spring是一个分层的JavaSE/EE full-stack(一站式) 轻量级开源框架. 具体介绍参考 一:IoC(Inversion of Control)控制反转,将创建对象实例反转给spri ...
- 创建PaletteSet的一个问题
下面是一个常规创建PaletteSet面板的代码: public static PaletteSet m_ps = null; [CommandMethod("MyPalette" ...
- C#4.0新增功能04 嵌入的互操作类型
连载目录 [已更新最新开发文章,点击查看详细] 从 .NET Framework 4 开始,公共语言运行时支持将 COM 类型的类型信息直接嵌入到托管程序集中,而不要求托管程序集从互操作程序集中 ...
- oracle分隔字符串列转行
1. DEMO: SELECT REGEXP_SUBSTR('1,2', '[^,]+', 1, LEVEL) FROM DUAL CONNECT BY REGEXP_ ...
- Java EE.JSP.指令
JSP的指令是从JSP向Web容器发送消息,它用来设置页面的全局属性,如输出内容类型等. JSP的指令的格式为:<%@ 指令名 属性="属性值"%> 1.page指令 ...
- MyBatis在Spring环境下的事务管理
MyBatis的设计思想很简单,可以看做是对JDBC的一次封装,并提供强大的动态SQL映射功能.但是由于它本身也有一些缓存.事务管理等功能,所以实际使用中还是会碰到一些问题--另外,最近接触了JFin ...
- 统计学习方法6—logistic回归和最大熵模型
目录 logistic回归和最大熵模型 1. logistic回归模型 1.1 logistic分布 1.2 二项logistic回归模型 1.3 模型参数估计 2. 最大熵模型 2.1 最大熵原理 ...
- CodeForces 372 A. Counting Kangaroos is Fun
题意,有n只袋鼠,没每只袋鼠有个袋子,大小为si,一个袋鼠可以进入另外一个袋鼠的袋子里面,当且仅当另一个袋鼠的袋子是他的二倍或二倍一上,然后中国袋鼠就是不可见的,不能出现多个袋鼠嵌套的情况.让你求最少 ...
- win10应用商店卸载后重装教程
方法一 先进这个链接 http://go.microsoft.com/fwlink/?LinkId=619547 下载一个记事本文件,并且把它保存到你的“下载” 里面. 管理员身份打开Power ...