【大数据】分布式并行计算MapReduce
作业来源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3319
1. 用自己的话阐明Hadoop平台上HDFS和MapReduce的功能、工作原理和工作过程。
(1)HDFS的功能:元数据、检查点、DataNode功能
HDFS的工作原理:
数据存取 - HDFS架构:
Master / Slave(主从结构) - 节点可以理解为物理机器
- 主节点,只有一个: Namenode
- 从节点,有很多个: Datanodes
1) 分布式文件系统,它所管理的文件是被切块存储在若干台datanode服务器上.;
2) hdfs提供了一个统一的目录树来定位hdfs中的文件,客户端访问文件时只要指定目录树的路径即可,不用关心文件的具体物理位置;
3) 每一个文件的每一个切块,在hdfs集群中都可以保存多个备份(默认3份),在hdfs-site.xml中,dfs.replication的value的数量就是备份的数量;
4) hdfs中有一个关键进程服务进程:namenode,它维护了一个hdfs的目录树及hdfs目录结构与文件真实存储位置的映射关系(元数据).而datanode服务进程专门负责接收和管理"文件块";
HDFS的工作过程:客户端要向HDFS写数据,首先要跟namenode通信以确认可以写文件并获得接收文件block的datanode,然后,客户端按顺序将文件逐个block传递给相应datanode,并由接收到block的datanode负责向其他datanode复制block的副本。
(2)MapReduce的功能:Hbase和Hdfs之间数据相互转换;排序;Top N;从hbase中读取数据统计并在hdfs中降序输出Top 3;去重(Distinct)、计数(Count)、最大值(Max)、求和(Sum)、平均值(Avg);(多个job串行处理计算平均值;分区(Partition);Pv、Uv;倒排索引(Inverted Index);join;
MapReduce的工作原理:
数据运算 - MapReduce架构:
主从结构
- 主节点,只有一个: JobTracker
- 从节点,有很多个: TaskTrackers
MR编程模型原理:利用一个输入的key-value对集合来产生一个输出的key-value对集合。
MapReduce的工作过程:MR框架是由一个单独运行在主节点上的JobTracker和运行在每个集群从节点上的TaskTracker共同组成。主节点负责调度构成一个作业的所有任务,这些任务分布在不同的不同的从节点上。主节点监视它们的执行情况,并重新执行之前失败的任务。从节点仅负责由主节点指派的任务。当一个Job被提交时,JobTracker接受到提交作业和配置信息之后,就会将配置信息等分发给从节点,同时调度任务并监控TaskTracker的执行。JobTracker可以运行于集群中的任意一台计算机上。TaskTracker负责执行任务,它必须运行在DataNode上,DataNode既是数据存储节点,也是计算节点。JobTracker将map任务和reduce任务分发给空闲的TaskTracker,这些任务并行运行,并监控任务运行的情况。如果JobTracker出了故障,JobTracker会把任务转交给另一个空闲的TaskTracker重新运行。
2.HDFS上运行MapReduce
1)准备文本文件,放在本地/home/hadoop/wc

2)编写map函数和reduce函数,在本地运行测试通过
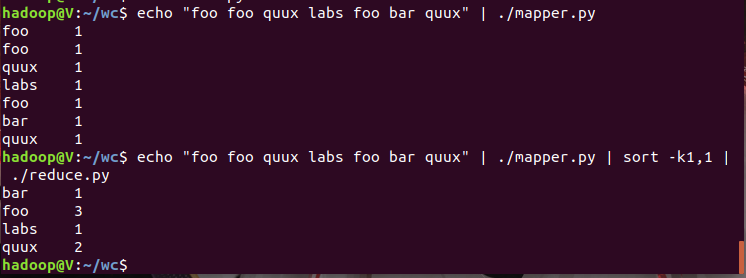
3)启动Hadoop:HDFS, JobTracker, TaskTracker
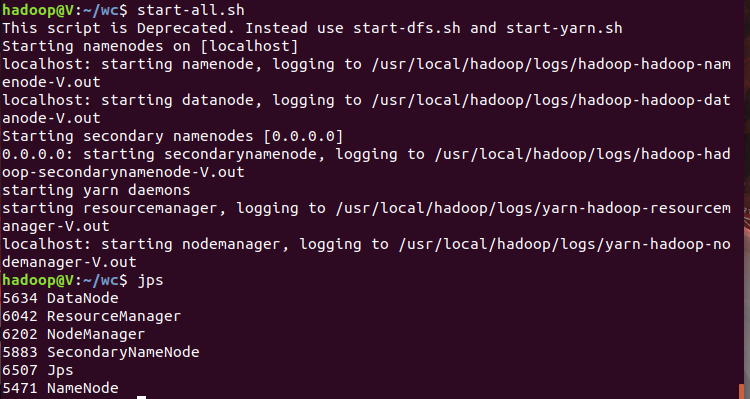
4)把文本文件上传到hdfs文件系统上 user/hadoop/input

5)streaming的jar文件的路径写入环境变量,让环境变量生效
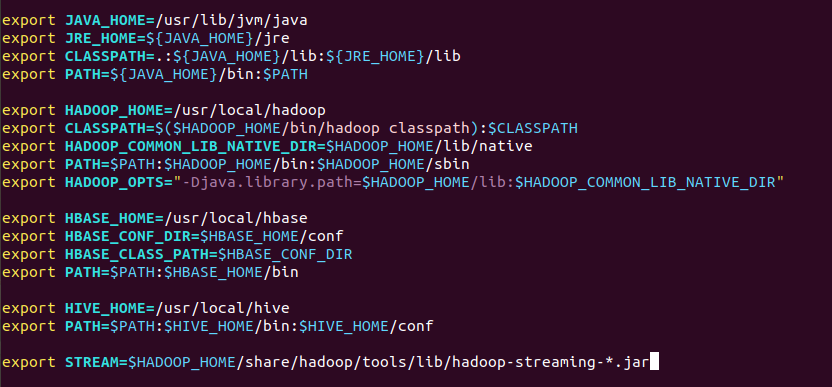
6)建立一个shell脚本文件:streaming接口运行的脚本,名称为run.sh
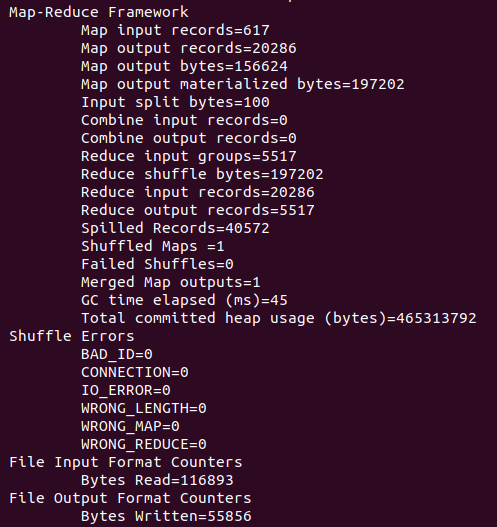
7)source run.sh来执行mapreduce

8)查看运行结果

【大数据】分布式并行计算MapReduce的更多相关文章
- 大数据篇:MapReduce
MapReduce MapReduce是什么? MapReduce源自于Google发表于2004年12月的MapReduce论文,是面向大数据并行处理的计算模型.框架和平台,而Hadoop MapR ...
- 大数据运算模型 MapReduce 原理
大数据运算模型 MapReduce 原理 2016-01-24 杜亦舒 MapReduce 是一个大数据集合的并行运算模型,由google提出,现在流行的hadoop中也使用了MapReduce作为计 ...
- 【大数据系列】MapReduce详解
MapReduce是hadoop中的一个计算框架,用来处理大数据.所谓大数据处理,即以价值为导向,对大数据加工,挖掘和优化等各种处理. MapReduce擅长处理大数据,这是由MapReduce的设计 ...
- ElasticSearch大数据分布式弹性搜索引擎使用
阅读目录: 背景 安装 查找.下载rpm包 .执行rpm包安装 配置elasticsearch专属账户和组 设置elasticsearch文件所有者 切换到elasticsearch专属账户测试能否成 ...
- 《OD大数据实战》MapReduce实战
一.github使用手册 1. 我也用github(2)——关联本地工程到github 2. Git错误non-fast-forward后的冲突解决 3. Git中从远程的分支获取最新的版本到本地 4 ...
- ElasticSearch大数据分布式弹性搜索引擎使用—从0到1
阅读目录: 背景 安装 查找.下载rpm包 .执行rpm包安装 配置elasticsearch专属账户和组 设置elasticsearch文件所有者 切换到elasticsearch专属账户测试能否成 ...
- 大数据 --> 分布式文件系统HDFS的工作原理
分布式文件系统HDFS的工作原理 Hadoop分布式文件系统(HDFS)是一种被设计成适合运行在通用硬件上的分布式文件系统.HDFS是一个高度容错性的系统,适合部署在廉价的机器上.它能提供高吞吐量的数 ...
- 深入浅出聊Taier—大数据分布式可视化DAG任务调度系统
导读: 上周,袋鼠云数栈全新技术开源规划--DTMO(DTstack Meetup Online)的第一场直播圆满完成.袋鼠云数栈大数据开发专家.Taier项目主导人偷天为大家带来了<Taier ...
- 大数据小白系列 —— MapReduce流程的深入说明
上一期我们介绍了MR的基本流程与概念,本期稍微深入了解一下这个流程,尤其是比较重要但相对较少被提及的Shuffling过程. Mapping 上期我们说过,每一个mapper进程接收并处理一块数据,这 ...
- 【大数据作业十一】分布式并行计算MapReduce
作业要求:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3319 1.用自己的话阐明Hadoop平台上HDFS和MapReduce的功 ...
随机推荐
- CSS3 小黄人案例
使用 CSS3 和 HTML5 制作一个小黄人. 结构代码: <div class="wrap"> <!-- 头发 --> <div class=&q ...
- python文字转语音
使用百度接口 接口地址 https://ai.baidu.com/docs#/TTS-Online-Python-SDK/top 安装接口 pip install baidu-aip from aip ...
- 【故障解决】OGG-00446 错误解决
[故障解决]OGG-00446 Could not find archived log for sequence 一.1 BLOG文档结构图 一.2 前言部分 一.2.1 导读和 ...
- php的多功能文件操作类
本类为文件操作类,实现了文件的建立,写入,删除,修改,复制,移动,创建目录,删除目录,列出目录里的文件等功能,路径后面别忘了加"/" 创建指定路径下的指定文件 * @param s ...
- Vi 和 Vim 编辑器详细使用方法
学习linux的一项必会技能,熟练使用vi/vim编辑器那便最重要的了.不过一堆操作看的也是太头疼了,以下整理了些常用到的命令. 工作模式 vi编辑界面有三种不同的工作模式,分别为命令模式.输入模式. ...
- mongodb 常见问题处理方法收集
问题1:非正常关闭服务或关机后 mongod服务无法正常启动 在使用中发现mongodb 的服务可能因为非正常关闭而启动不了,这时我们通过 删除data目录下的 *.lock文件,再运行下/mongo ...
- [Reproduced] How to Improve Code Quality?
How to Improve Code Quality? Ref: https://www.perforce.com/blog/sca/what-code-quality-and-how-improv ...
- appium+python自动化64-使用Uiautomator2执行driver.keyevent()方法报错解决
前言 未加'automationName': 'Uiautomator2'参数使用Uiautomator可以正常使用driver.keyevent()方法,使用Uiautomator2时driver. ...
- 常用conda命令【转载】
转载地址:https://haoyu.love/blog900.html 一直在用 Conda,很多东西记不住,每次都要查 Doc.那好,就写在这里做个备忘好了. 在 bash 里面自动加载 cond ...
- 《基于C/S和B/S混合结构的中职学校教务管理系统设计与实现》论文笔记(十六)
标题:基于C/S和B/S混合结构的中职学校教务管理系统设计与实现 一.基本信息 时间:2008 来源:中 国 海 洋 大 学 关键词:: 教务管理信息系统;C/S和B/S混合结构;UML;USE CA ...