基于C+OpenCV4.0的LineSegmentDetector算法实现
简单记录LSD算法的实现过程,当做备忘录用,如有问题欢迎指出和讨论
LSD的基本实现流程是计算出图像的梯度和场方向,然后对梯度进行排序,然后从大到小进行区域增长,之后对增长得到的区域求最小外接矩形,如果矩形不满足要求,则修改参数重新生长或者修改矩形的大小和位置,若仍旧不满足,则放弃该区域
笔者从数据结构层面优化了原算法的时间复杂度和空间复杂度
高斯降采样:
分x方向和y方向进行采样,方法相同,计算高斯核的公式为正态分布(即高斯分布)公式,因原公式对中心店偏移了0.5并向下取整,所以观察结果可发现,在0.3的采样比例下(其他参数需要重新计算或者用通用公式),高斯核的重心偏差为0,-1/3,1/3,因此只需计算一次高斯核,减少计算量,此高斯核对两个方向是通用的
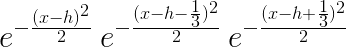
采样的时候每隔10/3(+0.5后取整)个像素一次采样,然后用(此地图的高斯核为1x17)高斯核对这个像素及其左右8个像素进行卷积然后得到该点的新数值
梯度与Level-Line场方向:
求梯度的公式一般使用这三个公式
笔者使用的是LSD的公式
将1x2窗口变成了2x2窗口
人为设定角度阈值(degreeThreshold),记为degThre,一般设为22.5°,用弧度制表示,angleThreshold(简记为angThre)是对应的角度制,通过下面公式计算出梯度阈值(gradientThreshold),记为gradThre
如果该点梯度小于阈值,则加入usedMap,这步主要将边角和某些凹凸区域给去掉了,然后用gx和gy计算出每点的梯度方向,即level-line场方向,每个点的值记为degree(简记为deg)
区域生长RegionGrower:
对所有剩下的像素进行快排(原论文使用的是分成了1024级梯度然后进行伪排序),然后从梯度最大的像素开始增长,增长的方式是在usedMap为空的像素中增长,方法是比较当前像素与周围8个像素的deg差,如果小于阈值degThre则加入区域Region,然后将最后比较并加入的像素作为下次比较的基准像素(动画中为浅蓝色),通过动画和代码可知,新增长点有滞后性,所以在区域两个端点切换的时候,基准像素在端点的另一侧,所以能够保证两端的角度差较小,若最后生长得到的直线弧度较大,后面有算法进行修正,如果得到的区域所含像素过少,则舍去该区域
最小外接矩形RectangleConvert:
遍历所有像素,找到四个方向上最边界上的像素,然后得到他们的外接矩形,返回值为矩阵两个短边的中点坐标(x1,y1)和(x2,y2),短边边长width(简记为wid),重心坐标(centerX,centerY)(简记为(cenX,cenY)),主方向角弧度degree(简记为deg),角弧度余弦值degreeX和角弧度正弦值degreeY(简记为dx和dy),像素点和角弧度相符的概率probability(简记为p),像素点场方向与主方向角弧度之差的阈值prec
其中p是直接使用的阈值占180°的比例,即1/8,prec直接使用的22.5°对应的弧度制阈值
精炼Rifiner:
这步主要是解决前面所说的弧度过大问题,因为可能在增长的时候一侧增长完,则基准像素一直在一端,则无法控制弧度,最终导致弧度过大,使用下式计算出密度density(简记为den),若大于阈值则进行精炼
首先计算出新的degThre
然后利用新得到的degThre重新进行区域生长和建立最小外接矩形,若得到的区域仍未满足密度阈值,则减小区域半径(往往都要减小半径)
减小半径的算法是找出矩形四个顶点中离生长点最远的距离作为半径,每次以一定的比例减小半径,然后对半径内的像素点再次生成最小外接矩形并计算密度,直到密度小于密度阈值
改善矩形RectangleImprover:
先利用rec结构体里的数据求出矩形四个顶点,然后根据之间的大小关系调整顺序,使得四个顶点的顺序和四个边的斜率顺序如下图
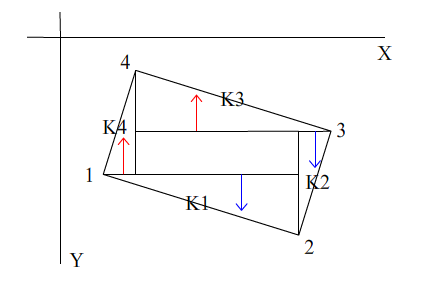
然后设定1到3的横坐标为yLow和yHigh的横坐标,分辨率为长度1的像素,分为两段结合K3K4计算出yLow的纵坐标(向下取整,图中为向上取整),即K3K4所在边的纵坐标,下边同理计算出K1K2所在边的纵坐标(向上取整,图中为向下取整),记为yHigh,然后yLow与yHigh所包围的所有像素为矩形的全部像素,数量记为allPixelNumber(简记为allPixNum),其中计算每个像素的场方向与矩阵主方向角度差,若小于阈值degThre则判定为alignedPixelNumber(简记为aliPixNum),意为方向相同的向量
首先需要计算虚警数Number of False Alarms(简记为NFA),如何推出此公式可以阅读文末的链接
第一项为当前大小(m*n)图像中直线(矩形框)的数量,在m*n的图像中直线的起点和终点分别有m*n种选择,所以一共有(m*n)*(m*n)种起点和终点搭配,线段的宽度为[0,m*n ^0.5],因此在m*n大小的图像中有(m*n)^2.5 种不同直线,两边同时求对数可得,yLim和xLim是图像的长宽
二项式的计算为,其中组合数C(n,k)使用广义阶乘转化为伽马函数
带入B(n,k,p)然后求首项,并对两侧求对数可得二项分布值,伽马函数使用了Windschitl方法和Lanczos方法进行近似计算,此处不详细说明
若首项很小,则忽略尾项,直接将B带入原式可得NFA,反之,则继续计算尾项,其中利用前后项的关系可以简化计算
可推出B(n,k,p)后项与前项的比值为
即对前面求出的首项乘以上式然后累加可得二项式,然后将B带入原式可得NFA
论文中给出的建议值是虚警数小于1,此处取负对数,则大于0,然后开始改善精度,分为四步,分别是减小角度容忍度(p),仅减少宽度(wid),减小宽度(wid)同时改变重心位置(x1 y1 x2 y2),然后再次减小角度容忍度(p)
减小角度容忍度(p):每次减小一半为p的一半,然后根据新的阈值计算NFA,若比原NFA大则保存新的矩阵和p
仅减小宽度(wid):根据前面算出的p减小矩阵宽度,步进为0.5,若新NFA大则保存新的矩阵和wid
减小宽度(wid)同时改变重心位置(x1 y1 x2 y2):保持两个长边中一个边不动,缩进另一个边,同时减小宽度,若新NFA大则保存新的矩阵和wid
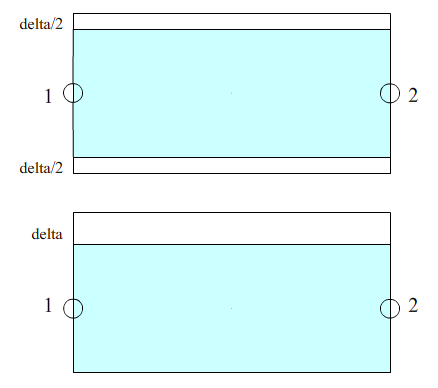
如图所示意,1和2表示rec结构里面的x1 y1和x2 y2,如果计算得到的NFA值已经大于0,则直接返回,若最后返回NFA值小于0,则判定为虚警(False Alarm),原矩阵所含有的像素被标记后释放,可重新用于生长,但是不能成为生长起始点
循环以上算法直到所有种子像素都完成生长则可得到所有生长区域
笔者的代码托管于Github,同时录制了算法的动画
https://github.com/Pyrokine/LineSegmentDetector17
https://www.bilibili.com/video/av43174965/
感谢以下Geeks和论文
基于LSD的直线提取算法
https://blog.csdn.net/tianwaifeimao/article/details/17678669 LSD: a Line Segment Detector
http://www.ipol.im/pub/art/2012/gjmr-lsd/ 线特征---LSD算法(二)
https://www.cnblogs.com/Jessica-jie/p/7512152.html
基于C+OpenCV4.0的LineSegmentDetector算法实现的更多相关文章
- 在VS2017(VC15)上配置opencv4.0.1环境
在VS2017(VC15)上配置opencv4.0.1环境 转 https://blog.csdn.net/GoldenBullet/article/details/86016921 作为萌新最初 ...
- <<一种基于δ函数的图象边缘检测算法>>一文算法的实现。
原始论文下载: 一种基于δ函数的图象边缘检测算法. 这篇论文读起来感觉不像现在的很多论文,废话一大堆,而是直入主题,反倒使人觉得文章的前后跳跃有点大,不过算法的原理已经讲的清晰了. 一.原理 ...
- SVD++:推荐系统的基于矩阵分解的协同过滤算法的提高
1.背景知识 在讲SVD++之前,我还是想先回到基于物品相似的协同过滤算法.这个算法基本思想是找出一个用户有过正反馈的物品的相似的物品来给其作为推荐.其公式为:
- 基于视觉的Web页面分页算法VIPS的实现源代码下载
基于视觉的Web页面分页算法VIPS的实现源代码下载 - tingya的专栏 - 博客频道 - CSDN.NET 基于视觉的Web页面分页算法VIPS的实现源代码下载 分类: 技术杂烩 2006-04 ...
- 基于物品的协同过滤推荐算法——读“Item-Based Collaborative Filtering Recommendation Algorithms” .
ligh@local-host$ ssh-copy-id -i ~/.ssh/id_rsa.pub root@192.168.0.3 基于物品的协同过滤推荐算法--读"Item-Based ...
- 基于FP-Tree的关联规则FP-Growth推荐算法Java实现
基于FP-Tree的关联规则FP-Growth推荐算法Java实现 package edu.test.ch8; import java.util.ArrayList; import java.util ...
- 基于Hadoop2.2.0版本号分布式云盘的设计与实现
基于Hadoop2.2.0版本号分布式云盘的设计与实现 一.前言 在学习了hadoop2.2一个月以来,我重点是在学习hadoop2.2的HDFS.即是hadoop的分布式系统,看了非常久的源代码看的 ...
- 决策树之ID3、C4.5、C5.0等五大算法
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- C5.0决策树之ID3.C4.5.C5.0算法 ...
- 车牌定位与畸变校正(python3.7,opencv4.0)
一.前言及思路简析 目前车牌识别系统在各小区门口随处可见,识别效果貌似都还可以.查阅资料后,发现整个过程又可以细化为车牌定位.畸变校正.车牌分割和内容识别四部分.本篇随笔主要介绍车牌定位及畸变校正两部 ...
随机推荐
- Nginx静态服务配置---详解root和alias指令
Nginx静态服务配置---详解root和alias指令 静态文件 Nginx以其高性能著称,常用与做前端反向代理服务器.同时nginx也是一个高性能的静态文件服务器.通常都会把应用的静态文件使用ng ...
- Python之路【第十八篇】:前端HTML
一.前端概述 import socket def main(): sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) sock.bind( ...
- 介绍一款好用的命令行工具Cmder
一.Cmder的介绍: 在大多数情况下,我们都想复制命令行窗口中的命令行,但是cmd复制粘贴大家都懂得:有没有更好的工具替代呢? 答案是肯定的,今天我将为大家介绍一款工具--Cmder. Cmder可 ...
- sublime_python编译_输出台中文为乱码
Evernote Export sublime_python编译_输出台中文为乱码 创建时间: 2019-10-17 星期四 10:52 作者: 苏苏 标签: sublime, 乱码 问题 ...
- 《JAVA高并发编程详解》-volatile和synchronized
- Golang/Go goroutine调度器原理/实现【原】
Go语言在2016年再次拿下TIBOE年度编程语言称号,这充分证明了Go语言这几年在全世界范围内的受欢迎程度.如果要对世界范围内的gopher发起一次“你究竟喜欢Go的哪一点”的调查,我相信很多Gop ...
- 利用nfs-client-provisioner动态提供Kubernetes后端存储卷
原文:https://www.kubernetes.org.cn/3894.html 利用NFS client provisioner动态提供Kubernetes后端存储卷 本文翻译自nfs-clie ...
- python二维数组切片
python中list切片的使用非常简洁.但是list不支持二维数组.仔细研究了一下发现,因为list不是像nampy数组那么规范.list非常灵活.所以没办法进行切片操作. 后来想了两个办法来解决: ...
- 微服务架构ServiceMesh
公司用的架构,在此找了资料作为记录复看所用: 什么是Service Mesh? Service Mesh的概念最早是由Buoyant公司的CEO William Morgan在一篇文章里提出,他给出的 ...
- JavaWeb 之 JSTL 标签
JSTL 标签库 一.概述 1.概念 JSTL : JavaServer Pages Tag Library JSP标准标签库. 是由 Apache 组织提供的开源的免费的 jsp 标签. 2.作用 ...