【知识点】同样是消息队列,Kafka凭什么速度那么快?
同样是消息队列,Kafka凭什么速度那么快?
作者 | MrZhangxd
Kafka的消息是保存或缓存在磁盘上的,一般认为在磁盘上读写数据是会降低性能的,因为寻址会比较消耗时间,但是实际上,Kafka的特性之一就是高吞吐率。
即使是普通的服务器,Kafka也可以轻松支持每秒百万级的写入请求,超过了大部分的消息中间件,这种特性也使得Kafka在日志处理等海量数据场景广泛应用。
针对Kafka的基准测试可以参考,Apache Kafka基准测试:每秒写入2百万(在三台廉价机器上)
下面从数据写入和读取两方面分析,为什么Kafka速度这么快。
一、写入数据
Kafka会把收到的消息都写入到硬盘中,它绝对不会丢失数据。为了优化写入速度Kafka采用了两个技术, 顺序写入和MMFile 。
1、顺序写入
磁盘读写的快慢取决于你怎么使用它,也就是顺序读写或者随机读写。在顺序读写的情况下,磁盘的顺序读写速度和内存持平。
因为硬盘是机械结构,每次读写都会寻址->写入,其中寻址是一个“机械动作”,它是最耗时的。所以硬盘最讨厌随机I/O,最喜欢顺序I/O。为了提高读写硬盘的速度,Kafka就是使用顺序I/O。
而且Linux对于磁盘的读写优化也比较多,包括read-ahead和write-behind,磁盘缓存等。如果在内存做这些操作的时候,一个是JAVA对象的内存开销很大,另一个是随着堆内存数据的增多,JAVA的GC时间会变得很长,使用磁盘操作有以下几个好处:
- 磁盘顺序读写速度超过内存随机读写
- JVM的GC效率低,内存占用大。使用磁盘可以避免这一问题
- 系统冷启动后,磁盘缓存依然可用
下图就展示了Kafka是如何写入数据的, 每一个Partition其实都是一个文件 ,收到消息后Kafka会把数据插入到文件末尾(每一列最后一个框部分):
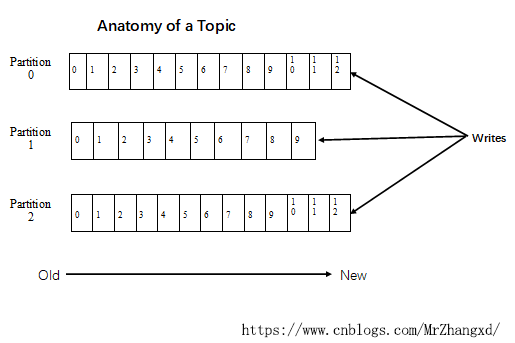
这种方法有一个缺陷——没有办法删除数据 ,所以Kafka是不会删除数据的,它会把所有的数据都保留下来,每个消费者(Consumer)对每个Topic都有一个offset用来表示读取到了第几条数据。

两个消费者:
- Consumer1有两个offset分别对应Partition0、Partition1(假设每一个Topic一个Partition);
- Consumer2有一个offset对应Partition2。
这个offset是由客户端SDK负责保存的,Kafka的Broker完全无视这个东西的存在;一般情况下SDK会把它保存到Zookeeper里面,所以需要给Consumer提供zookeeper的地址。
如果不删除硬盘肯定会被撑满,所以Kakfa提供了两种策略来删除数据:
- 一是基于时间;
- 二是基于partition文件大小。
具体配置可以参看它的配置文档。
2、Memory Mapped Files
即便是顺序写入硬盘,硬盘的访问速度还是不可能追上内存。所以Kafka的数据并不是实时的写入硬盘 ,它充分利用了现代操作系统分页存储来利用内存提高I/O效率。
Memory Mapped Files(后面简称mmap)也被翻译成 内存映射文件 ,在64位操作系统中一般可以表示20G的数据文件,它的工作原理是直接利用操作系统的Page来实现文件到物理内存的直接映射。
完成映射之后你对物理内存的操作会被同步到硬盘上(操作系统在适当的时候)。
通过mmap,进程像读写硬盘一样读写内存(当然是虚拟机内存),也不必关心内存的大小有虚拟内存为我们兜底。
使用这种方式可以获取很大的I/O提升,省去了用户空间到内核空间复制的开销(调用文件的read会把数据先放到内核空间的内存中,然后再复制到用户空间的内存中。)
但也有一个很明显的缺陷——不可靠,写到mmap中的数据并没有被真正的写到硬盘,操作系统会在程序主动调用flush的时候才把数据真正的写到硬盘。
Kafka提供了一个参数——producer.type来控制是不是主动flush,如果Kafka写入到mmap之后就立即flush然后再返回Producer叫 同步 (sync);写入mmap之后立即返回Producer不调用flush叫异步 (async)。
二、读取数据
Kafka在读取磁盘时做了哪些优化?
1、基于sendfile实现Zero Copy
传统模式下,当需要对一个文件进行传输的时候,其具体流程细节如下:
- 调用read函数,文件数据被copy到内核缓冲区
- read函数返回,文件数据从内核缓冲区copy到用户缓冲区
- write函数调用,将文件数据从用户缓冲区copy到内核与socket相关的缓冲区。
- 数据从socket缓冲区copy到相关协议引擎。
以上细节是传统read/write方式进行网络文件传输的方式,我们可以看到,在这个过程当中,文件数据实际上是经过了四次copy操作:
硬盘—>内核buf—>用户buf—>socket相关缓冲区—>协议引擎
而sendfile系统调用则提供了一种减少以上多次copy,提升文件传输性能的方法。
在内核版本2.1中,引入了sendfile系统调用,以简化网络上和两个本地文件之间的数据传输。sendfile的引入不仅减少了数据复制,还减少了上下文切换。
sendfile(socket, file, len);
运行流程如下:
- sendfile系统调用,文件数据被copy至内核缓冲区
- 再从内核缓冲区copy至内核中socket相关的缓冲区
- 最后再socket相关的缓冲区copy到协议引擎
相较传统read/write方式,2.1版本内核引进的sendfile已经减少了内核缓冲区到user缓冲区,再由user缓冲区到socket相关缓冲区的文件copy,而在内核版本2.4之后,文件描述符结果被改变,sendfile实现了更简单的方式,再次减少了一次copy操作。
在Apache、Nginx、lighttpd等web服务器当中,都有一项sendfile相关的配置,使用sendfile可以大幅提升文件传输性能。
Kafka把所有的消息都存放在一个一个的文件中,当消费者需要数据的时候Kafka直接把文件发送给消费者,配合mmap作为文件读写方式,直接把它传给sendfile。
2、批量压缩
在很多情况下,系统的瓶颈不是CPU或磁盘,而是网络IO,对于需要在广域网上的数据中心之间发送消息的数据流水线尤其如此。进行数据压缩会消耗少量的CPU资源,不过对于kafka而言,网络IO更应该需要考虑。
- 如果每个消息都压缩,但是压缩率相对很低,所以Kafka使用了批量压缩,即将多个消息一起压缩而不是单个消息压缩
- Kafka允许使用递归的消息集合,批量的消息可以通过压缩的形式传输并且在日志中也可以保持压缩格式,直到被消费者解压缩
- Kafka支持多种压缩协议,包括Gzip和Snappy压缩协议
三、总结
Kafka速度的秘诀在于,它把所有的消息都变成一个批量的文件,并且进行合理的批量压缩,减少网络IO损耗,通过mmap提高I/O速度,写入数据的时候由于单个Partion是末尾添加所以速度最优;读取数据的时候配合sendfile直接暴力输出。
【知识点】同样是消息队列,Kafka凭什么速度那么快?的更多相关文章
- 分布式消息队列 Kafka
分布式消息队列 Kafka 2016-02-25 杜亦舒 Kafka是一个高吞吐量的.分布式的消息系统,由Linkedin开发,开发语言为scala具有高吞吐.可扩展.分布式等特点 适用场景 活动数据 ...
- 消息队列kafka
消息队列kafka 为什么用消息队列 举例 比如在一个企业里,技术老大接到boss的任务,技术老大把这个任务拆分成多个小任务,完成所有的小任务就算搞定整个任务了. 那么在执行这些小任务的时候,可能 ...
- 消息队列 Kafka 的基本知识及 .NET Core 客户端
前言 最新项目中要用到消息队列来做消息的传输,之所以选着 Kafka 是因为要配合其他 java 项目中,所以就对 Kafka 了解了一下,也算是做个笔记吧. 本篇不谈论 Kafka 和其他的一些消息 ...
- 消息队列-Kafka学习
Kafka是一个分布式的消息队列,学习见Apache Kafka文档,中文翻译见Kafka分享,一个简单的入门例子见kafka代码入门实例.本文只针对自己感兴趣的点记录下. 1.架构 Producer ...
- 消息队列Kafka学习记录
Kafka其实只是众多消息队列中的一种,对于Kafka的具体释义我这里就不多说了,详见:http://baike.baidu.com/link?url=HWFYszYuMdP_lueFH5bmYnlm ...
- 分布式消息队列kafka
下载地址:http://kafka.apache.org/downloads.html 先启动zookeeper服务器 bin/zookeeper-server-start.sh config/zoo ...
- 基于Docker搭建分布式消息队列Kafka
本文基于Docker搭建一套单节点的Kafka消息队列,Kafka依赖Zookeeper为其管理集群信息,虽然本例不涉及集群,但是该有的组件都还是会有,典型的kafka分布式架构如下图所示.本例搭建的 ...
- (转)消息队列 Kafka 的基本知识及 .NET Core 客户端
原文地址:https://www.cnblogs.com/savorboard/p/dotnetcore-kafka.html 前言 最新项目中要用到消息队列来做消息的传输,之所以选着 Kafka 是 ...
- Kafka 消息队列系列之分布式消息队列Kafka
介绍 ApacheKafka®是一个分布式流媒体平台.这到底是什么意思呢?我们认为流媒体平台具有三个关键功能:它可以让你发布和订阅记录流.在这方面,它类似于消息队列或企业消息传递系统.它允许您以容 ...
随机推荐
- JS基础_强制类型转换-Number
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- kubernetes第二章--集群搭建
- 阿里云OSS上传文件本地调试跨域问题解决
问题描述: 最近后台说为了提高上传效率,要前端直接上传文件到阿里云,而不经过后台.因为在阿里云服务器设置的允许源(region)为某个固定的域名下的源(例如*.cheche.com),直接在本地访问会 ...
- 3.建造模式(Builder)
注:图片来源于 https://www.cnblogs.com/-saligia-/p/10216752.html 建造模式UML图解析: 代码: Director.h // // Created b ...
- 208道Java常见的面试题
一.Java 基础 1.JDK 和 JRE 有什么区别? JRE=JVM+各种基础类库+java类库(String\System) JDK>JRE>JVM JRE:是java运行时环境 ...
- jenkins rpm卸载
rpm卸载 1.rpm -e jenkins rpm -ql jenkins 检查是否卸载成功 2.彻底删除残留文件:find / -iname jenkins | xargs -n 1000 rm ...
- js对属性的操作
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...
- windows server自动化发布——技术积累与整理
文章:应用在Windows系统中的自动化部署实践 博主大概讲解了一遍如何摸索实现自动化部署.不过内容不详细,很多具体细节需要自己摸索. 标题:windows server 部署服务(WDS) 地址:h ...
- Andrew Ng机器学习 四:Neural Networks Learning
背景:跟上一讲一样,识别手写数字,给一组数据集ex4data1.mat,,每个样例都为灰度化为20*20像素,也就是每个样例的维度为400,加载这组数据后,我们会有5000*400的矩阵X(5000个 ...
- openGL起飞篇
我的技术路线:glfw+glad(有了glfw,什么glew,freeglut都不要了) GLFW:直接下载,然后新建vs项目,在<VC++>的<包含目录>添加include路 ...