[原创]python+beautifulsoup爬取整个网站的仓库列表与仓库详情
from bs4 import BeautifulSoup
import requests
import os def getdepotdetailcontent(title,url):#爬取每个仓库列表的详情
r=requests.get("https://www.50yc.com"+url).content
soup = BeautifulSoup(r,"html.parser")
result = soup.find(name='div',attrs={"class":"sm-content"})#返回元素集
content = result.find_all("li")#返回元素集
with open(os.getcwd()+"\\depot\\"+title+"\\depotdetail.txt","w") as f :
for i in content:
b = i.find("span").text
br = i.find("div").text
f .write(b.replace(" ","").replace("\n","")+br.replace(" ","")+"\n"+"****************************"+"\n")
f.close() def getdepot(page):#爬取仓库列表信息
depotlisthtml = requests.get("https://www.50yc.com/xan"+page).content
content = BeautifulSoup(depotlisthtml,"html.parser")
tags = content.find_all(name="div",attrs={"class":"bg-hover"})
for i in tags:
y = i.find_all(name="img")#返回tag标签
for m in y:
if m["src"].startswith("http"):
imgurl = m["src"]
print(imgurl)
title = i.strong.text
depotdetailurl = i.a['href']
# print(depotdetailurl)
os.mkdir(os.getcwd()+'\\depot\\'+title+'\\')
with open(os.getcwd()+'\\depot\\'+title+'\\'+"depot.jpg","wb") as d :
d.write(requests.get(imgurl).content)
with open(os.getcwd()+'\\depot\\'+title+'\\'+"depot.txt","w") as m:
m.write(i.text.replace(" ",""))
m.close()
getdepotdetailcontent(title,depotdetailurl) for i in range(1,26):#爬取每页的仓库列表与仓库详情
getdepot("/page"+str(i))
print("/page"+str(i))
爬取内容为:
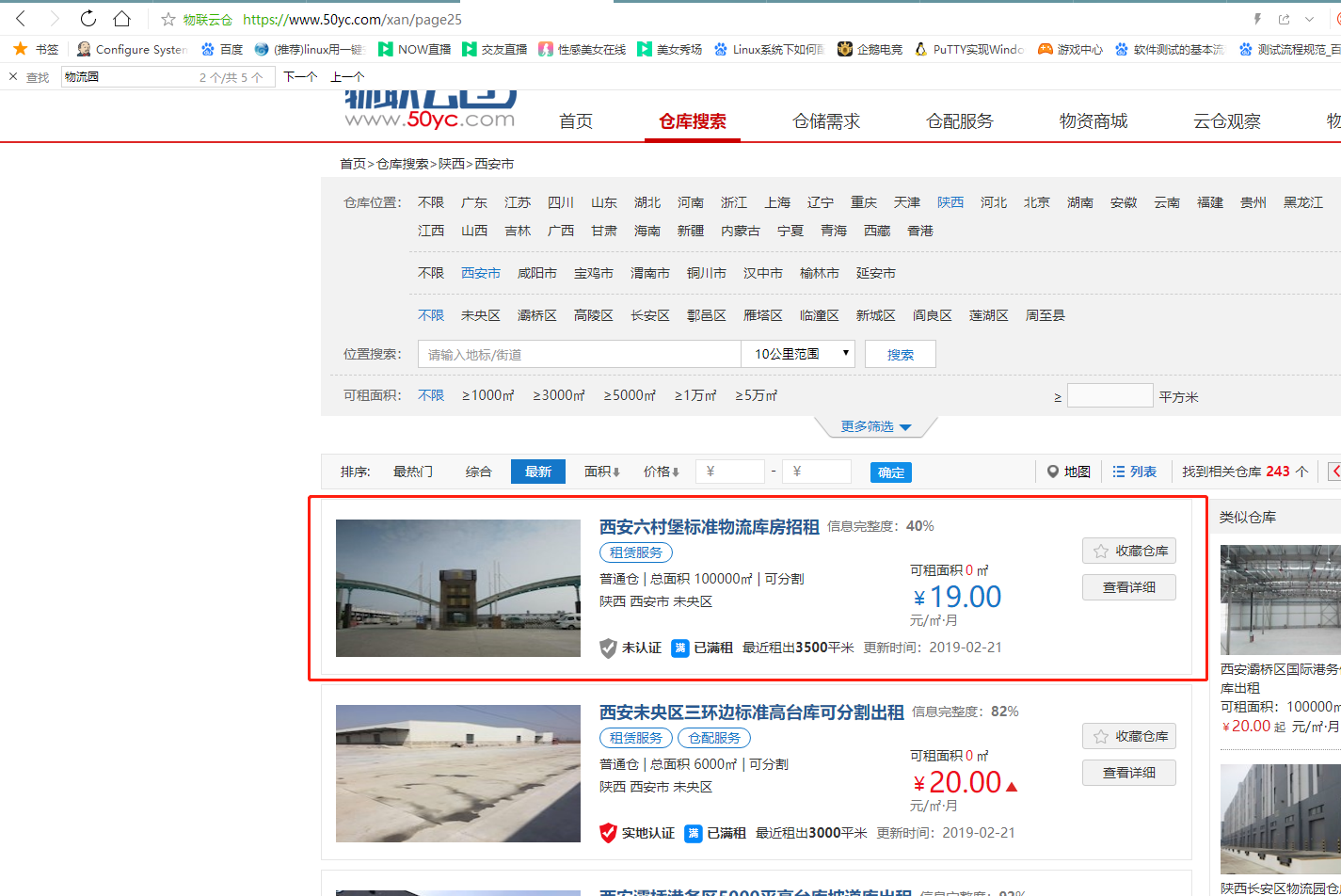
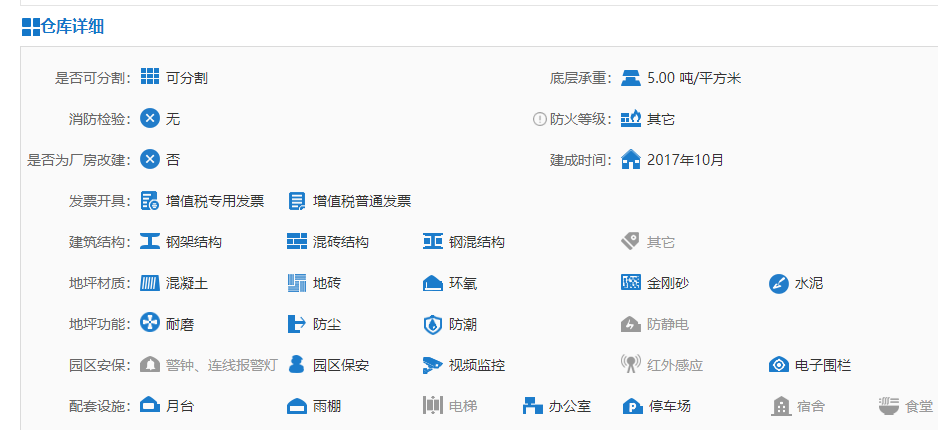
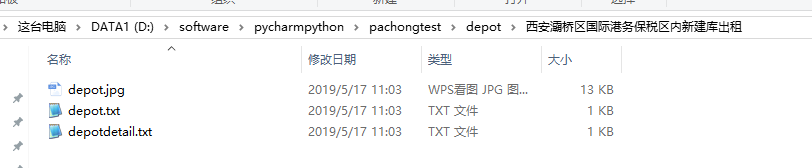
爬取结果如下:

[原创]python+beautifulsoup爬取整个网站的仓库列表与仓库详情的更多相关文章
- python爬虫--爬取某网站电影信息并写入mysql数据库
书接上文,前文最后提到将爬取的电影信息写入数据库,以方便查看,今天就具体实现. 首先还是上代码: # -*- coding:utf-8 -*- import requests import re im ...
- python爬虫--爬取某网站电影下载地址
前言:因为自己还是python世界的一名小学生,还有很多路要走,所以本文以目的为向导,达到目的即可,对于那些我自己都没弄懂的原理,不做去做过多解释,以免误人子弟,大家可以网上搜索. 友情提示:本代码用 ...
- Python爬虫学习之使用beautifulsoup爬取招聘网站信息
菜鸟一只,也是在尝试并学习和摸索爬虫相关知识. 1.首先分析要爬取页面结构.可以看到一列搜索的结果,现在需要得到每一个链接,然后才能爬取对应页面. 关键代码思路如下: html = getHtml(& ...
- Python多线程爬取某网站表情包
# 爬取网络图片import requestsfrom lxml import etreefrom urllib import requestfrom queue import Queue # 导入队 ...
- python 爬虫 爬取序列博客文章列表
python中写个爬虫真是太简单了 import urllib.request from pyquery import PyQuery as PQ # 根据URL获取内容并解码为UTF-8 def g ...
- Python 利用 BeautifulSoup 爬取网站获取新闻流
0. 引言 介绍下 Python 用 Beautiful Soup 周期性爬取 xxx 网站获取新闻流: 图 1 项目介绍 1. 开发环境 Python: 3.6.3 BeautifulSoup: ...
- 利用python的requests和BeautifulSoup库爬取小说网站内容
1. 什么是Requests? Requests是用Python语言编写的,基于urllib3来改写的,采用Apache2 Licensed 来源协议的HTTP库. 它比urllib更加方便,可以节约 ...
- python之简单爬取一个网站信息
requests库是一个简介且简单的处理HTTP请求的第三方库 get()是获取网页最常用的方式,其基本使用方式如下 使用requests库获取HTML页面并将其转换成字符串后,需要进一步解析HTML ...
- Python使用urllib,urllib3,requests库+beautifulsoup爬取网页
Python使用urllib/urllib3/requests库+beautifulsoup爬取网页 urllib urllib3 requests 笔者在爬取时遇到的问题 1.结果不全 2.'抓取失 ...
随机推荐
- day72_10_17 序列化组件之model的运用
一.拆分的序列化. model序列化的基本用法就是使用元类中的fields,其中model绑定的就是model中的表 如果需要多表查询,要在model中定义property: class BookMo ...
- java.net.URL类
package com.mozq.boot.kuayu01.demo; import java.net.MalformedURLException; import java.net.URL; publ ...
- IntelliJ IDEA创建一个简单的Java Project(二)
1. 选择要创建的项目类型,同时配置本地的JDK 2. 是否使用模板创建项目 3. 选择项目在本地的存储位置 4. 点击Finish,完成一个简单的Java工程的创建.
- python中实现单例模式
单例模式的目的是一个类有且只有一个实例对象存在,比如在复用类的过程中,可能重复创建多个实例,导致严重浪费内存,此时就适合使用单例模式. 前段时间需要用到单例模式,就称着机会在网上找了找,有包含了__n ...
- [日常] NOI2019 退役记
这次要彻底退役了 开个坑先 Day -2 出发坐车去gz 好像和上次去雅礼的车是同一趟于是大家都以为和上次一样是 \(10:40\) 开车, 于是提前2h大概八点多就去坐公交了 到了之后取票, 发现票 ...
- IPv6 邻居状态迁移
- python-2-条件判断
前言 python3当中的条件语句是非常简单简洁的,说下这两种:if 条件.while 条件. 一.if 条件语句 1.if 语句: # 如果条件成立,打印666 if True: print(666 ...
- nginx rewrite重写规则简明笔记
nginx rewrite重写规则简明笔记 比方说http://newmiracle.cn/?p=888我要改成能这个访问http://newmiracle.cn/p888/ 首先用正则获取888 ^ ...
- css不常用的4个选择器-个人向
①:element1.element2(给同时满足有element1和element2 2个类名的元素添加样式) <!DOCTYPE html> <html> <head ...
- Vue.js 源码分析(二十九) 高级应用 transition-group组件 详解
对于过度动画如果要同时渲染整个列表时,可以使用transition-group组件. transition-group组件的props和transition组件类似,不同点是transition-gr ...