Python爬虫学习之使用beautifulsoup爬取招聘网站信息
菜鸟一只,也是在尝试并学习和摸索爬虫相关知识。
1.首先分析要爬取页面结构。可以看到一列搜索的结果,现在需要得到每一个链接,然后才能爬取对应页面。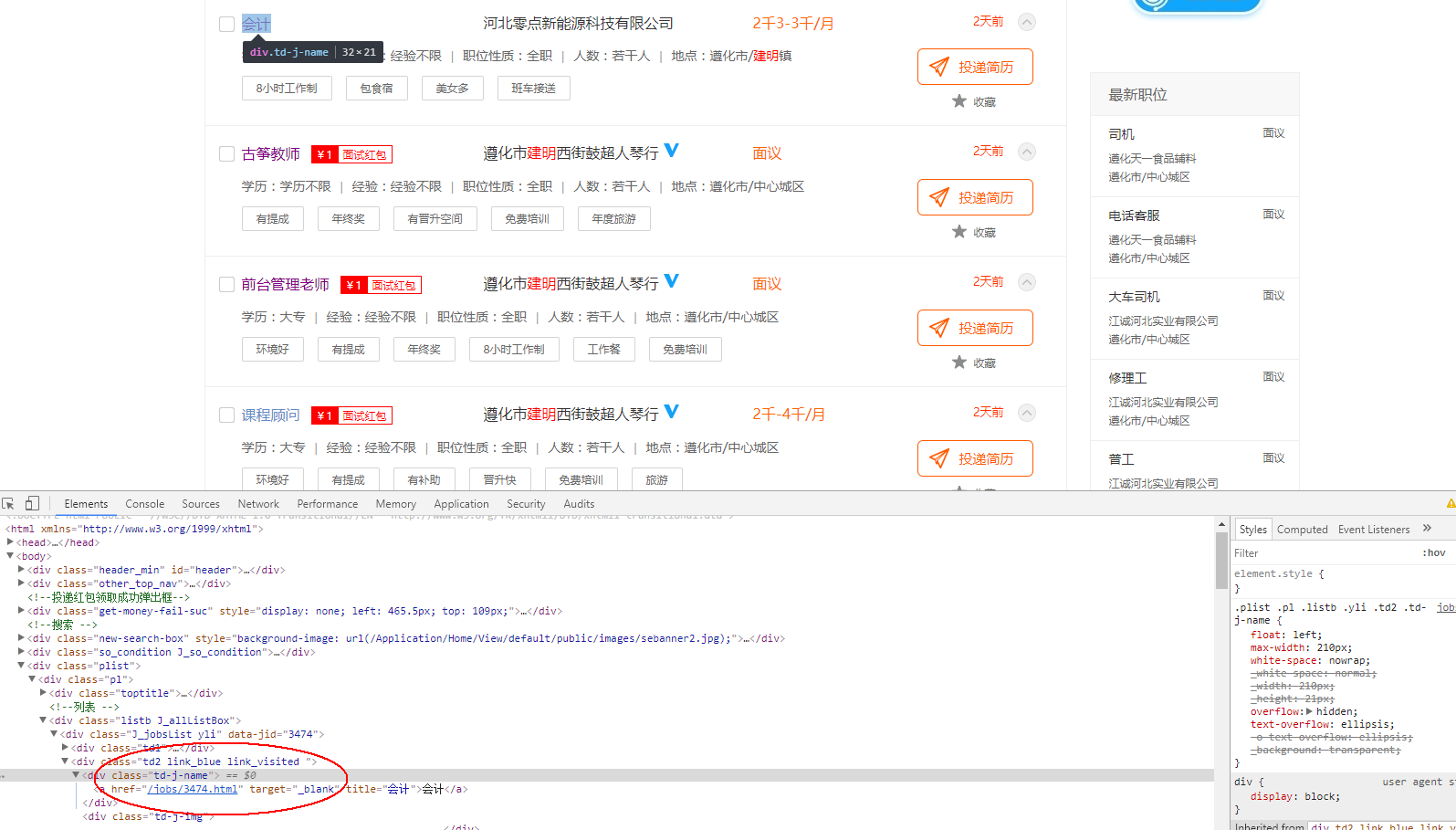
关键代码思路如下:
html = getHtml("http://www.zhrczp.com/jobs/jobs_list/key/%E5%BB%BA%E6%98%8E%E9%95%87/page/1.html")
soup = BeautifulSoup(html, 'lxml') #声明BeautifulSoup对象
hrefbox = soup.find_all("div","td-j-name",True);
links = [];
for href in range(0,len(hrefbox)):
links.append("http://www.zhrczp.com"+hrefbox[href].contents[0].get('href'));#拼接链接
现在已经得到一系列链接,下面分析需要爬取的链接页面的结构。
2.分析页面,页面所有感兴趣的内容均在 div标签里面,可以使用beautifulsoup提供的find_all函数来查找。
main = soup.find_all("div","main",True); 意思是查找div标签class为main的内容
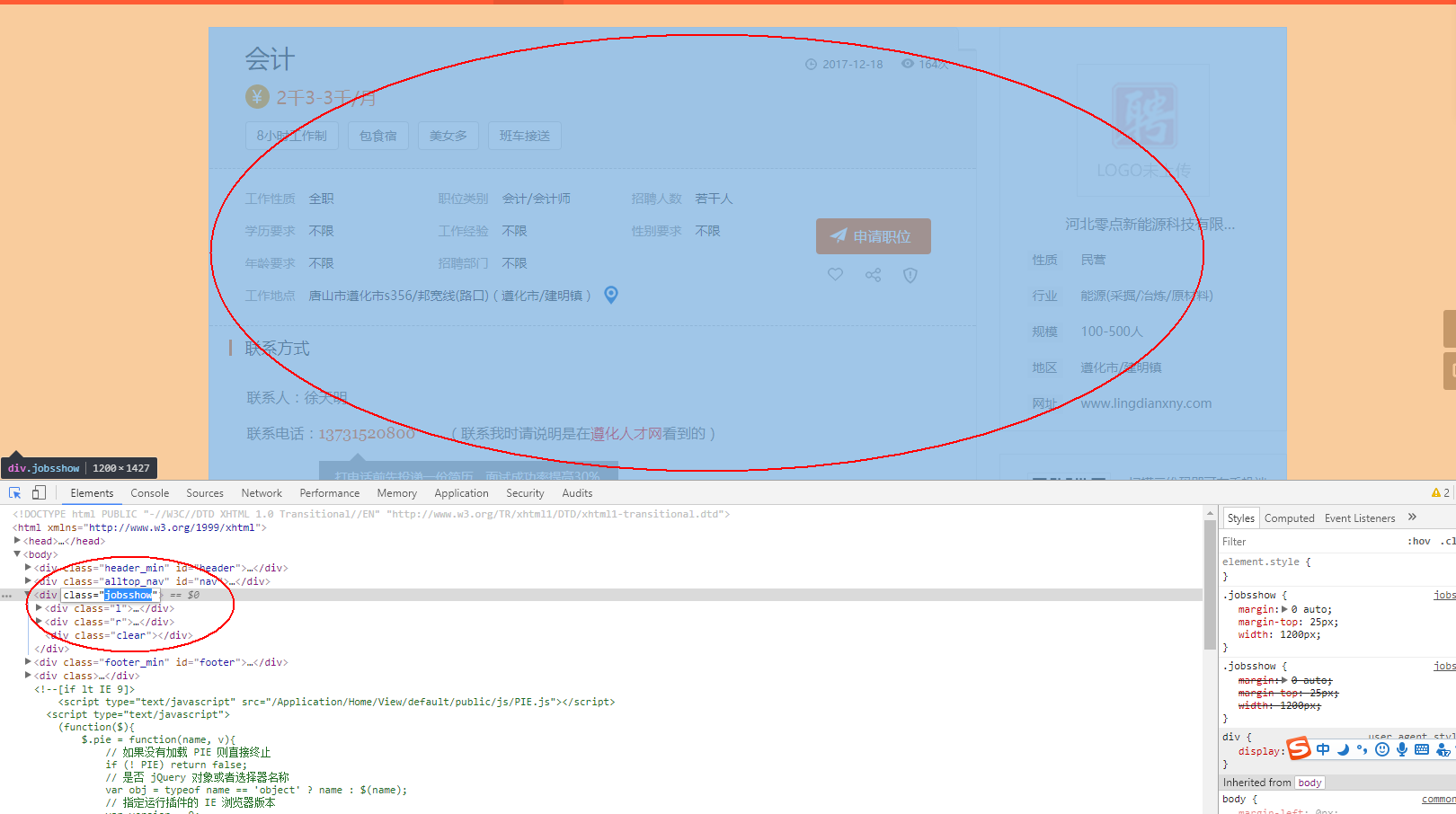
爬取并保存文件,效果如下:

详细代码如下:
#!/usr/bin/python
# -*- coding: utf-8 -*- import urllib
from bs4 import BeautifulSoup def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html html = getHtml("http://www.zhrczp.com/jobs/jobs_list/key/%E5%BB%BA%E6%98%8E%E9%95%87/page/1.html") soup = BeautifulSoup(html, 'lxml') #声明BeautifulSoup对象 hrefbox = soup.find_all("div","td-j-name",True); links = [];
for href in range(0,len(hrefbox)):
links.append("http://www.zhrczp.com"+hrefbox[href].contents[0].get('href'));#拼接链接 f=open('a.txt','w',encoding='utf-8')
for link in links:
print(link);
html = getHtml(link)
soup = BeautifulSoup(html, 'lxml') #声明BeautifulSoup对象 main = soup.find_all("div","main",True);
f.write("\n**********************************************************************\n\n")
f.write("职位名称:"+main[0].contents[1].contents[5].contents[1].contents[0]+"\n");#职位名称
f.write("发布时间:"+main[0].contents[1].contents[3].contents[1].contents[0]+"\n");#发布时间
f.write("\n--------------------职位待遇--------------------\n");
f.write("工资:"+main[0].contents[1].contents[7].contents[0]+"\n");#wage
f.write("福利:");
for i in range(1,len(main[0].contents[1].contents[9].contents)-3):
f.write(main[0].contents[1].contents[9].contents[i].contents[0]+" "); f.write("\n\n--------------------联系方式--------------------\n")
f.write(main[0].contents[5].contents[3].contents[0].strip()+"\n");#联系人 去掉空格
f.write(main[0].contents[5].contents[7].contents[0]+main[0].contents[5].contents[7].contents[1].contents[0]+"\n");#联系电话 f.write("\n--------------------联系描述--------------------\n")
describe = main[0].contents[7].contents;
f.write(describe[1].contents[0]+describe[3].contents[0]+"\n");#职位描述 item = soup.find_all("div","item",True);
f.write("\n--------------------职位要求--------------------\n");
f.write(item[0].contents[3].contents[0].contents[0]+":"+item[0].contents[3].contents[1]+"\n");#工作性质
f.write(item[0].contents[5].contents[0].contents[0]+":"+item[0].contents[5].contents[1]+"\n");#职位类别
f.write(item[0].contents[7].contents[0].contents[0]+":"+item[0].contents[7].contents[1]+"\n");#招聘人数
f.write(item[0].contents[11].contents[0].contents[0]+":"+item[0].contents[11].contents[1]+"\n");#学历要求
f.write(item[0].contents[13].contents[0].contents[0]+":"+item[0].contents[13].contents[1]+"\n");#工作经验
f.write(item[0].contents[15].contents[0].contents[0]+":"+item[0].contents[15].contents[1]+"\n");#性别要求
f.write(item[0].contents[19].contents[0].contents[0]+":"+item[0].contents[19].contents[1]+"\n");#年龄要求
f.write(item[0].contents[21].contents[0].contents[0]+":"+item[0].contents[21].contents[1]+"\n");#招聘部门
f.write(item[0].contents[25].contents[0].contents[0]+":"+item[0].contents[25].contents[1]+"\n");#招聘部门 company = soup.find_all("div","cominfo link_gray6",True);
f.write("\n--------------------公司信息--------------------\n");
f.write(company[0].contents[3].contents[1].contents[0]+"\n");#公司名称
f.write(company[0].contents[5].contents[0].contents[0]+":"+company[0].contents[5].contents[1]+"\n");#公司性质
f.write(company[0].contents[7].contents[0].contents[0]+":"+company[0].contents[7].contents[1]+"\n");#公司行业
f.write(company[0].contents[9].contents[0].contents[0]+":"+company[0].contents[9].contents[1]+"\n");#公司规模
f.write(company[0].contents[11].contents[0].contents[0]+":"+company[0].contents[11].contents[1]+"\n");#公司地区 f.write("\n**********************************************************************\n")
f.close();
参考:
http://www.cnblogs.com/Albert-Lee/p/6232745.html
https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
Python爬虫学习之使用beautifulsoup爬取招聘网站信息的更多相关文章
- Python爬虫学习三------requests+BeautifulSoup爬取简单网页
第一次第一次用MarkDown来写博客,先试试效果吧! 昨天2018俄罗斯世界杯拉开了大幕,作为一个伪球迷,当然也得为世界杯做出一点贡献啦. 于是今天就编写了一个爬虫程序将腾讯新闻下世界杯专题的相关新 ...
- Python爬虫学习(6): 爬取MM图片
为了有趣我们今天就主要去爬取以下MM的图片,并将其按名保存在本地.要爬取的网站为: 大秀台模特网 1. 分析网站 进入官网后我们发现有很多分类: 而我们要爬取的模特中的女模内容,点进入之后其网址为:h ...
- 爬虫学习(二)--爬取360应用市场app信息
欢迎加入python学习交流群 667279387 爬虫学习 爬虫学习(一)-爬取电影天堂下载链接 爬虫学习(二)–爬取360应用市场app信息 代码环境:windows10, python 3.5 ...
- 爬虫系列2:Requests+Xpath 爬取租房网站信息
Requests+Xpath 爬取租房网站信息 [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]:参考前文 ...
- Python爬虫初探 - selenium+beautifulsoup4+chromedriver爬取需要登录的网页信息
目标 之前的自动答复机器人需要从一个内部网页上获取的消息用于回复一些问题,但是没有对应的查询api,于是想到了用脚本模拟浏览器访问网站爬取内容返回给用户.详细介绍了第一次探索python爬虫的坑. 准 ...
- python爬虫实践(二)——爬取张艺谋导演的电影《影》的豆瓣影评并进行简单分析
学了爬虫之后,都只是爬取一些简单的小页面,觉得没意思,所以我现在准备爬取一下豆瓣上张艺谋导演的“影”的短评,存入数据库,并进行简单的分析和数据可视化,因为用到的只是比较多,所以写一篇博客当做笔记. 第 ...
- Python爬虫——使用 lxml 解析器爬取汽车之家二手车信息
本次爬虫的目标是汽车之家的二手车销售信息,范围是全国,不过很可惜,汽车之家只显示100页信息,每页48条,也就是说最多只能够爬取4800条信息. 由于这次爬虫的主要目的是使用lxml解析器,所以在信息 ...
- Python 爬虫实例(4)—— 爬取网易新闻
自己闲来无聊,就爬取了网易信息,重点是分析网页,使用抓包工具详细的分析网页的每个链接,数据存储在sqllite中,这里只是简单的解析了新闻页面的文字信息,并未对图片信息进行解析 仅供参考,不足之处请指 ...
- [原创]python+beautifulsoup爬取整个网站的仓库列表与仓库详情
from bs4 import BeautifulSoup import requests import os def getdepotdetailcontent(title,url):#爬取每个仓库 ...
随机推荐
- POJ1222EXTENDED LIGHTS OUT(高斯消元)
EXTENDED LIGHTS OUT Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 11815 Accepted: 7 ...
- K - 迷宫问题 POJ - 3984
定义一个二维数组: int maze[5][5] = { 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 1, ...
- Fibonacci Check-up
Fibonacci Check-up Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) ...
- CUDA C Best Practices Guide 在线教程学习笔记 Part 1
0. APOD过程 ● 评估.分析代码运行时间的组成,对瓶颈进行并行化设计.了解需求和约束条件,确定应用程序的加速性能改善的上限. ● 并行化.根据原来的代码,采用一些手段进行并行化,例如使用现有库, ...
- DOM 遍历-同胞
在 DOM 树中水平遍历 有许多有用的方法让我们在 DOM 树进行水平遍历: siblings() next() nextAll() nextUntil() prev() prevAll() prev ...
- C 程序实现密码隐秘输入 linux系统可执行
读写用户输入,屏幕不回显 char *getpass( const char *prompt); getpass用于从键盘读取用户输入,但屏幕不回显. 参数prompt为屏幕提示字符. 函数返回值为用 ...
- 【Win 10 应用开发】UI Composition 札记(五):灯光
UI Composition 除了能够为 UI 元素建立三维空间外,还有相当重要的一个部件——灯光.宇宙万物的精彩缤纷,皆源于光明,光,使我们看到各种东西,除了黑洞之外的世界都是五彩斑谰的.故而,真要 ...
- Scrum Meeting Alpha - 1 (团队任务分解)
团队任务分解 Alpha阶段项目目标 实现一个博客园班级博客的Android 客户端: 实现班级博客的常用功能(不包括投票.公告.校区) 有一个较为简洁美观.操作方便的界面 添加消息提醒功能. 任务拆 ...
- 向TRichEdit插入图片的单元
很简单, 就3个函数, 直接看代码吧 unit RichEditBmp; { 2005-03-04 LiChengbin Added: Insert bitmap or gif into RichEd ...
- jQuery学习笔记之Ajax用法详解
这篇文章主要介绍了jQuery学习笔记之Ajax用法,结合实例形式较为详细的分析总结了jQuery中ajax的相关使用技巧,包括ajax请求.载入.处理.传递等,需要的朋友可以参考下 本文实例讲述了j ...