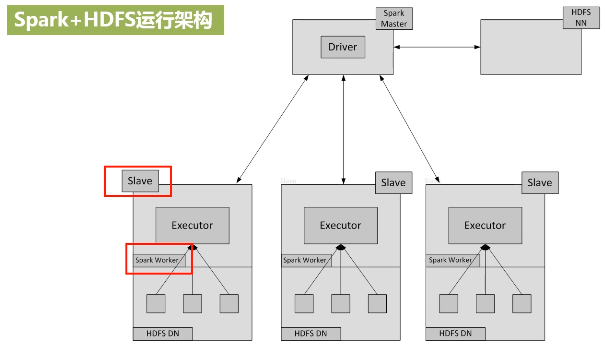
4.Spark环境搭建和使用方法
一、安装Spark
spark和Hadoop可以部署在一起,相互协作,由Hadoop的HDFS、HBase等组件复制数据的存储和管理,由Spark负责数据的计算。
Linux:CentOS Linux release 7.6.1810(Core)(cat /etc/centos-release 查看linux版本)
Hadoop:2.8.5(hadoop version)
JDK:1.8.0_171(java -version)
Spark:2.3.0(先在命令行中查找spark-shell所在的位置,命令为find / -name spark-shell,然后运行spark-shell,就能看到spark的版本号了)
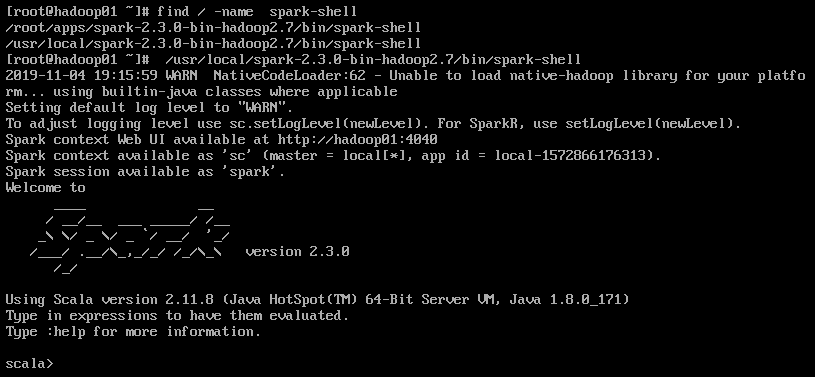
二、在spark-shell中运行代码
1.四种模式
(1)local



(2)独立集群

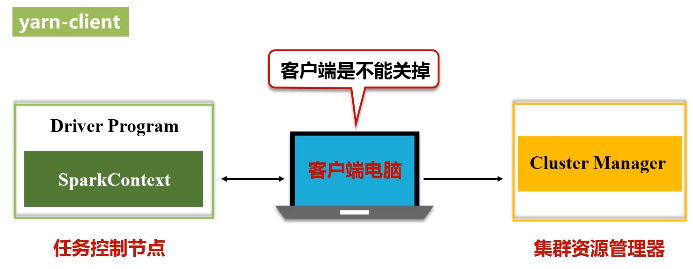
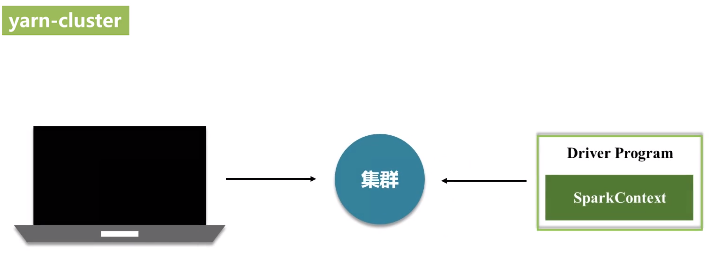
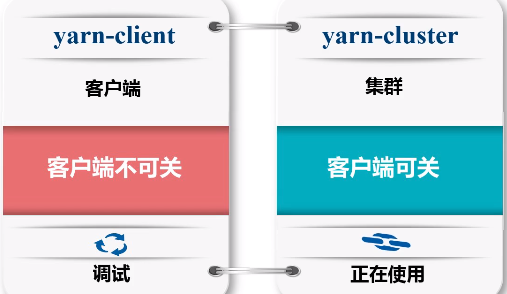
(3)yarn


(4)MESOS

举例:


启动spark shell成功后在输出信息的末尾可以看到"scala >"的命令提示符
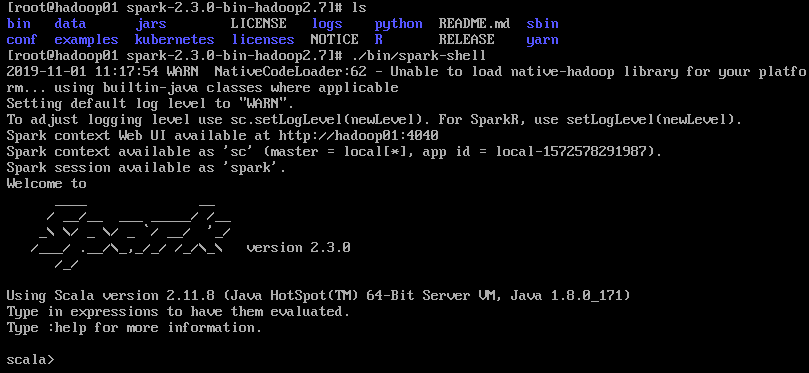

三、编写Spark独立应用程序

第一步:

第二步:

(1)sbt
步骤一:安装sbt



步骤2:用sbt打包
需要在应用程序的目录下构建simple.sbt文件(只要扩展名是.sbt都可以),在sbt中给出依赖说明,说明中包括当前应用的名称,版本号,scala版本,依赖的groupID




在正式打包编译之前,需要检查一下目录结构,必须要满足下面的目录结构,才允许打包,编译。



打包成功,会出现success信息

(2)Maven
步骤一:安装Maven


在写本地文件的时候一定是file:///


步骤二:建一个新的目录叫sparkapp2,在该目录下建立src/main/scala,增加SimpleApp.scala代码
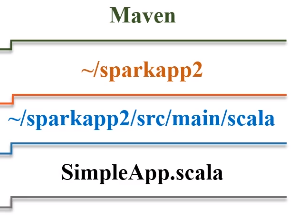
在“~/sparkapp2”目录中新建pom.xml文件


四、Spark集群环境搭建
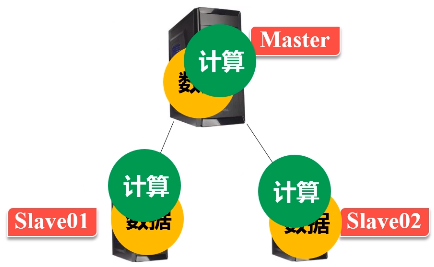
在实验室用三台机器搭建spark集群,一台作为主节点master,两台作为辅节点slave,将三台设备配置在同一个局域网内。 底层的Hadoop也要用集群进行配置,数据分布式保存,计算也要分布式运算

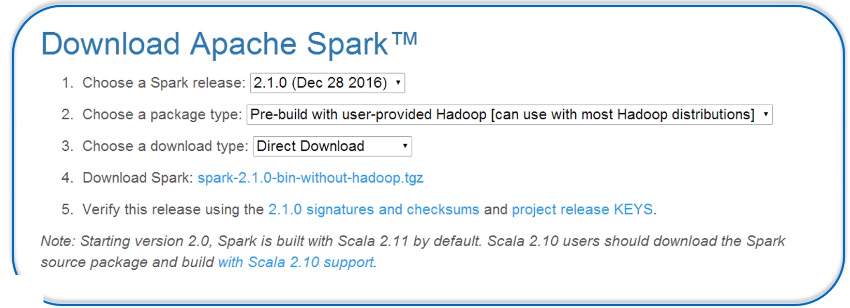
(1)在master节点上访问Spark官网下载Spark安装包

在master节点主机的终端中执行如下命令:
在.bashrc添加如下配置

运行source命令,使配置立即生效

(2)在master节点上配置slaves文件,该文件包含了所有从节点的相关信息,slaves文件是在Spark安装目录下面的conf子目录下,在conf子目录下有一个slave.template模块文件,把这个模板文件复制,重命名为Slaves文件。打开这个文件,把刚才两个从节点主机名称放到这个slave文件中保存一下,

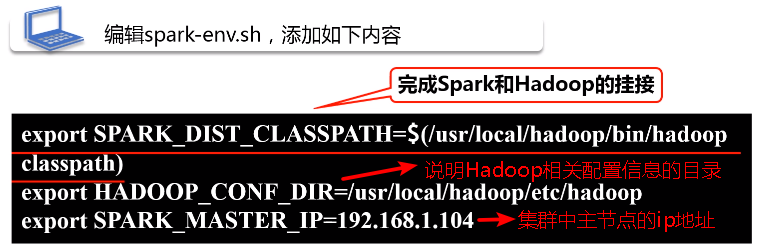
(3)配置spark-env.sh文件

将spark-env.template拷贝到spark-env.sh,在这个文件中,需要添加三行配置信息。
(4)将Master主机上的/usr/local/spark文件夹复制到各个节点上

在两个从节点上分别执行下面的操作,

(5)启动集群
启动Hadoop集群,然后启动Master节点,

然后再在master节点上,运行start-slaves.sh这个脚本文件,去启动另外两个从节点,

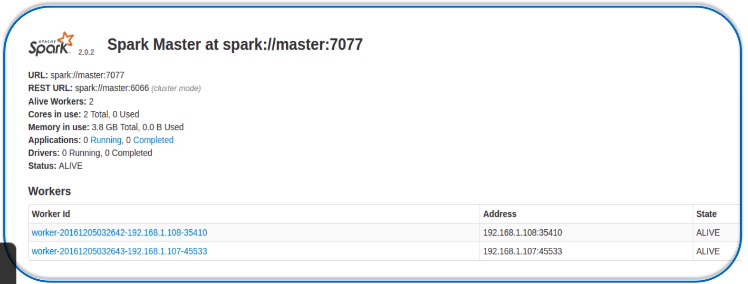
在master主机上打开浏览器,访问http://master:8080,就会显示下图集群信息
(6)关闭集群
先关闭spark(都是在master节点上执行,不用到slave节点关闭),再关闭Hadoop

五、在集群上运行Spark应用程序
1.启动Hadoop集群、Master节点和所有slaves节点

2.在集群汇总运行应用程序JAR包
安装目录是/usr/local/spark/,在这个目录下油锅spark-submit命令,用这个命令去提交刚才的应用程序,



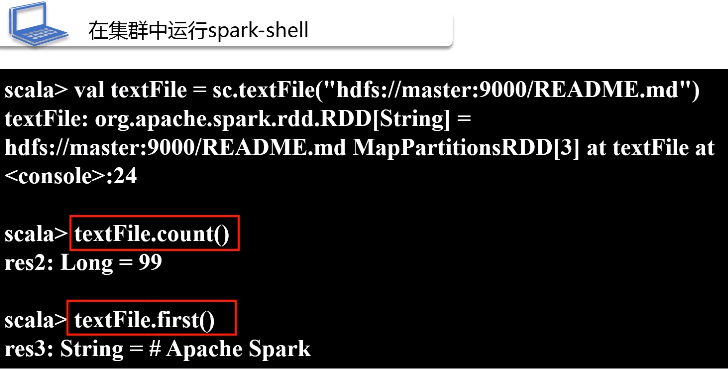
3.在集群中运行spark-shell
在交互式命令下,运行程序。下面写法表示spark-shell一进入交互式环境,就连接到独立集群资源管理器上面,通过它来调度指挥资源。

在spark交互式环境中,系统会自动生成一个名词为sc的SparkContext对象


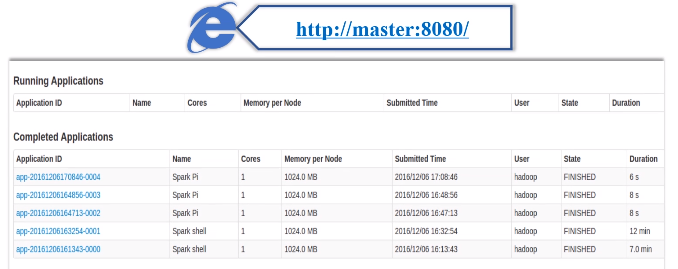
用户在独立集群管理Web界面查看应用的运行情况:在浏览器中输入http://master:8080/,就可以查看当前的运行状态。
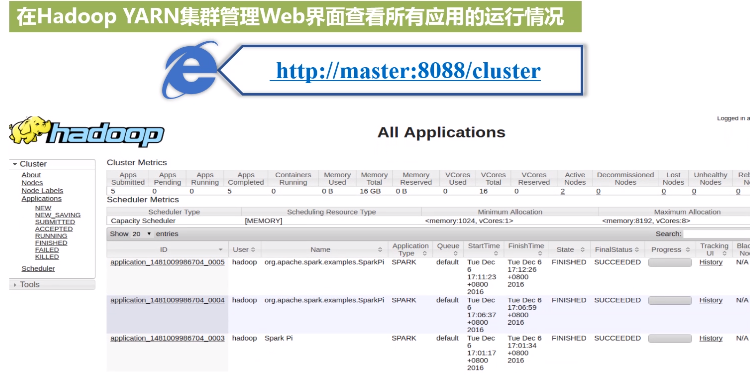
4.向Hadoop YARN集群管理器提交应用
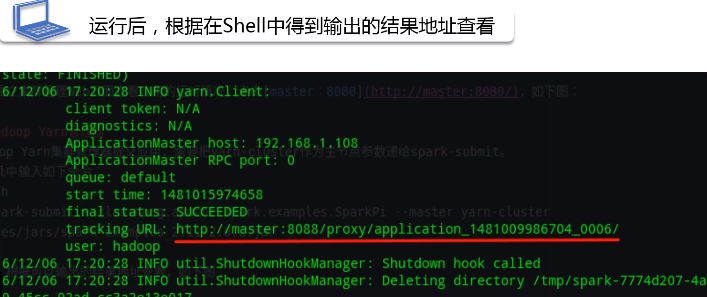
在当前master节点的安装目录下去运行命令,

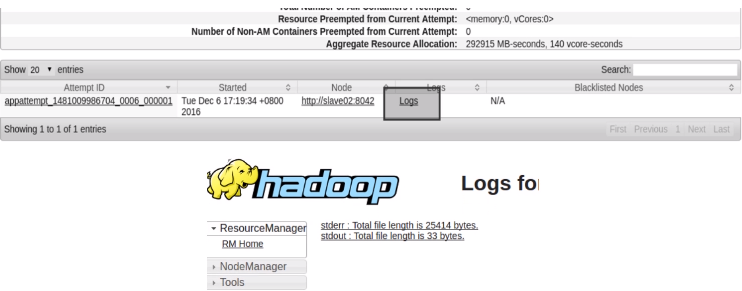
运行后,根据在shell中得到输出的结果地址进行查看
5.用spark-shell连接到YARN集群管理器上
在客户端启动一个spark-shell,是在客户端的交互式环境下执行,不可能是cluster模式,肯定是一个client模式。

参考文献:
4.Spark环境搭建和使用方法的更多相关文章
- Hive On Spark环境搭建
Spark源码编译与环境搭建 Note that you must have a version of Spark which does not include the Hive jars; Spar ...
- 分布式计算框架-Spark(spark环境搭建、生态环境、运行架构)
Spark涉及的几个概念:RDD:Resilient Distributed Dataset(弹性分布数据集).DAG:Direct Acyclic Graph(有向无环图).SparkContext ...
- Spark学习进度-Spark环境搭建&Spark shell
Spark环境搭建 下载包 所需Spark包:我选择的是2.2.0的对应Hadoop2.7版本的,下载地址:https://archive.apache.org/dist/spark/spark-2. ...
- Spark环境搭建(上)——基础环境搭建
Spark摘说 Spark的环境搭建涉及三个部分,一是linux系统基础环境搭建,二是Hadoop集群安装,三是Spark集群安装.在这里,主要介绍Spark在Centos系统上的准备工作--linu ...
- Eclipse+maven+scala+spark环境搭建
准备条件 我用的Eclipse版本 Eclipse Java EE IDE for Web Developers. Version: Luna Release (4.4.0) 我用的是Eclipse ...
- 学习Spark——环境搭建(Mac版)
大数据情结 还记得上次跳槽期间,与很多猎头都有聊过,其中有一个猎头告诉我,整个IT跳槽都比较频繁,但是相对来说,做大数据的比较"懒"一些,不太愿意动.后来在一篇文中中也证实了这一观 ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- Spark环境搭建(六)-----------sprk源码编译
想要搭建自己的Hadoop和spark集群,尤其是在生产环境中,下载官网提供的安装包远远不够的,必须要自己源码编译spark才行. 环境准备: 1,Maven环境搭建,版本Apache Maven 3 ...
- Spark环境搭建(四)-----------数据仓库Hive环境搭建
Hive产生背景 1)MapReduce的编程不便,需通过Java语言等编写程序 2) HDFS上的文缺失Schema(在数据库中的表名列名等),方便开发者通过SQL的方式处理结构化的数据,而不需要J ...
随机推荐
- 【cf1046】A. AI robots(动态开点线段树)
传送门 题意: 坐标轴上有\(n\)个机器人,每个机器人带有属性\(x,r,q\),分别表示位置.可视半径以及智商. 现在定义智商相近为两个机器人的智商差的绝对值不超过$K. 现在问有多少对机器人,他 ...
- [C2P3] Andrew Ng - Machine Learning
##Advice for Applying Machine Learning Applying machine learning in practice is not always straightf ...
- 4.web基础$_POST
- 肖哥讲jquery:
jquery 是一个模块 一个库 js封装的一个库 导入jq <script src="jquery.js"></script> <script ...
- 线程让步yield
一.yield()的作用 yield()的作用是让步.它能让当前线程由“运行状态”进入到“就绪状态”,从而让其它具有相同优先级的等待线程获取执行权:但是,并不能保证在当前线程调用yield()之后,其 ...
- MySQL SQL DML (数据操作语言)
包括 SELECT, UPDATE, DELETE, INSERT SELECT 从数据库表中获取数据 用法 SELECT name FROM students; SELECT name,age FR ...
- <LinkedList> 369 (高)143 (第二遍)142 148
369. Plus One Linked List 1.第1次while: 从前往后找到第一个不是9的位,记录. 2.第2次while: 此位+1,后面的所有值设为0(因为后面的位都是9). 返回时注 ...
- 微信小程序跳转web-vie时提示appId无法读取:Cannot read property 'appId' of undefined
微信小程序报web-view错无法读取appId:Cannot read property 'appId' of undefined 问题描述: 我以前一直如下写代码没报错也都是可以使用的,并且小程序 ...
- internet信息服务(IIS)管理器 在哪里?
我们在搭建网络配置时就需要找到internet信息服务(IIS)管理器,下面我们就来看看internet信息服务(IIS)管理器在哪里能够找到. 工具/材料 使用工具:电脑 01 02 03 04 0 ...
- VS2019已还原ReSharper的功能
本文只谈论 ReSharper 的那些常用功能中,Visual Studio 2019 能还原多少,主要提供给那些正在考虑不使用 ReSharper 插件的 Visual Studio 用户作为参考. ...