ElasticSearch 中文分词搜索环境搭建
ElasticSearch 是强大的搜索工具,并且是ELK套件的重要组成部分
好记性不如乱笔头,这次是在windows环境下搭建es中文分词搜索测试环境,步骤如下
1、安装jdk1.8,配置好环境变量
2、下载ElasticSearch7.1.1,版本变化比较快,刚才看了下最新版已经是7.2.0,本环境基于7.1.1搭建,下载地址https://www.elastic.co/cn/downloads/elasticsearch,得到一个zip压缩包,解压缩后cmd下运行下面的命令即可启动ES
./bin/elasticsearch.bat
正常启动的话提示符下回输出一些日志记录
浏览器中输入http://localhost:9200/测试服务是否能够正常访问,正常情况会显示下面的概要信息,说明ES搭建成功
3、ElasticSearch 虽然提供了强大Restful接口,但没有一个UI界面操作起来不是很直观,elasticsearch-head很好的解决这个问题,elasticsearch-head是基于node的一个工具,通过连接ES服务提供可视化展示界面,详细参考:
https://github.com/mobz/elasticsearch-head,安装步骤也是很简单,如下
git clone git://github.com/mobz/elasticsearch-head.git
cd elasticsearch-head
npm install
npm run start
服务正常启动后显示界面如下
浏览器中输入http://localhost:9100/可以看到对应UI

4、中文分词插件详细介绍见https://github.com/medcl/elasticsearch-analysis-ik,注意版本不要选错,否则会按照失败,es7.1.1选择对应版本,安装步骤如下:
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.1.1/elasticsearch-analysis-ik-7.1.1.zip
5、测试中文分词检索功能,先建立索引,在postman或者elasticsearch-head中发送如下请求
--创建索引
curl -XPUT http://localhost:9200/news --索引中添加数据
curl -XPOST http://localhost:9200/news/_create/1 -H 'Content-Type:application/json' -d'
{"content":"美国留给伊拉克的是个烂摊子吗"}
'
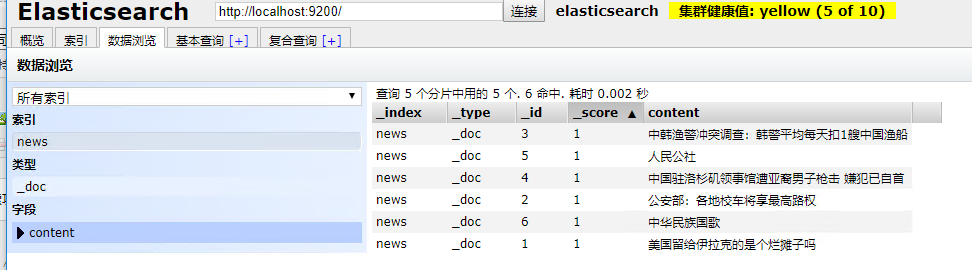
添加的数据如下
添加索引映射
curl -XPOST http://localhost:9200/news/_mapping -H 'Content-Type:application/json' -d'
{
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
} }'
ik_max_word ik_smart两者的区别
ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合,适合 Term Query;
ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”,适合 Phrase 查询。
测试示例:
http://localhost:9200/_analyze,通过ik_max_word分词,结果如下
输入
{"text":"中华人民共和国人民大会堂","analyzer":"ik_max_word" }
输出
{
"tokens": [
{
"token": "中华人民共和国",
"start_offset": 0,
"end_offset": 7,
"type": "CN_WORD",
"position": 0
},
{
"token": "中华人民",
"start_offset": 0,
"end_offset": 4,
"type": "CN_WORD",
"position": 1
},
{
"token": "中华",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 2
},
{
"token": "华人",
"start_offset": 1,
"end_offset": 3,
"type": "CN_WORD",
"position": 3
},
{
"token": "人民共和国",
"start_offset": 2,
"end_offset": 7,
"type": "CN_WORD",
"position": 4
},
{
"token": "人民",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 5
},
{
"token": "共和国",
"start_offset": 4,
"end_offset": 7,
"type": "CN_WORD",
"position": 6
},
{
"token": "共和",
"start_offset": 4,
"end_offset": 6,
"type": "CN_WORD",
"position": 7
},
{
"token": "国人",
"start_offset": 6,
"end_offset": 8,
"type": "CN_WORD",
"position": 8
},
{
"token": "人民大会堂",
"start_offset": 7,
"end_offset": 12,
"type": "CN_WORD",
"position": 9
},
{
"token": "人民大会",
"start_offset": 7,
"end_offset": 11,
"type": "CN_WORD",
"position": 10
},
{
"token": "人民",
"start_offset": 7,
"end_offset": 9,
"type": "CN_WORD",
"position": 11
},
{
"token": "大会堂",
"start_offset": 9,
"end_offset": 12,
"type": "CN_WORD",
"position": 12
},
{
"token": "大会",
"start_offset": 9,
"end_offset": 11,
"type": "CN_WORD",
"position": 13
},
{
"token": "会堂",
"start_offset": 10,
"end_offset": 12,
"type": "CN_WORD",
"position": 14
}
]
}
如果输入
{"text":"中华人民共和国人民大会堂","analyzer":"ik_smart" }
输出
{
"tokens": [
{
"token": "中华人民共和国",
"start_offset": 0,
"end_offset": 7,
"type": "CN_WORD",
"position": 0
},
{
"token": "人民大会堂",
"start_offset": 7,
"end_offset": 12,
"type": "CN_WORD",
"position": 1
}
]
}
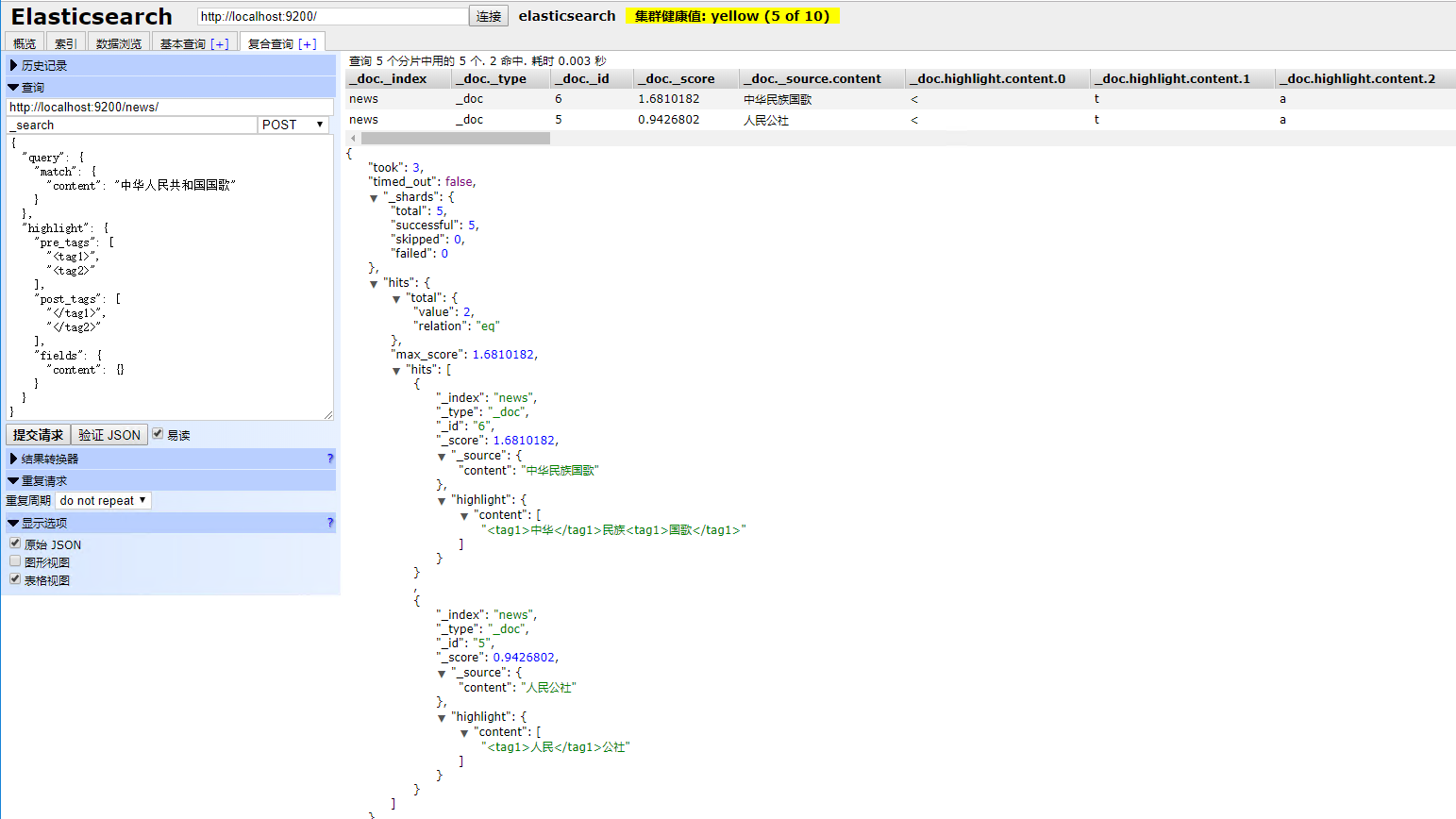
根据分词检索输入语法,请求url:http://localhost:9200/news/_search
输入:
{
"query" : { "match" : { "content" : "中华人民共和国国歌" }},
"highlight" : {
"pre_tags" : ["<tag1>", "<tag2>"],
"post_tags" : ["</tag1>", "</tag2>"],
"fields" : {
"content" : {}
}
}
}
输出:
{
"took": 11,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1.6810182,
"hits": [
{
"_index": "news",
"_type": "_doc",
"_id": "6",
"_score": 1.6810182,
"_source": {
"content": "中华民族国歌"
},
"highlight": {
"content": [
"<tag1>中华</tag1>民族<tag1>国歌</tag1>"
]
}
},
{
"_index": "news",
"_type": "_doc",
"_id": "5",
"_score": 0.9426802,
"_source": {
"content": "人民公社"
},
"highlight": {
"content": [
"<tag1>人民</tag1>公社"
]
}
}
]
}
}
运行效果如下
ElasticSearch 中文分词搜索环境搭建的更多相关文章
- 分布式搜索ElasticSearch单机与服务器环境搭建
从上方插件官网中下载适合的dist包,然后解压.进入bin目录,可以看到一堆sh脚本.在bin目录下创建一个test.sh: bin=/home/csonezp/Dev/elasticsearch-j ...
- Elasticsearch简单使用和环境搭建
Elasticsearch简单使用和环境搭建 1 Elasticsearch简介 Elasticsearch是一个可用于构建搜索应用的成品软件,它最早由Shay Bannon创建并于2010年2月发布 ...
- Sphinx + Coreseek 实现中文分词搜索
Sphinx + Coreseek 实现中文分词搜索 Sphinx Coreseek 实现中文分词搜索 全文检索 1 全文检索 vs 数据库 2 中文检索 vs 汉化检索 3 自建全文搜索与使用Goo ...
- elasticsearch 中文分词(elasticsearch-analysis-ik)安装
elasticsearch 中文分词(elasticsearch-analysis-ik)安装 下载最新的发布版本 https://github.com/medcl/elasticsearch-ana ...
- Elasticsearch 中文分词(elasticsearch-analysis-ik) 安装
由于elasticsearch基于lucene,所以天然地就多了许多lucene上的中文分词的支持,比如 IK, Paoding, MMSEG4J等lucene中文分词原理上都能在elasticsea ...
- Elasticsearch中文搜索环境搭建
Elasticsearch是一个建立在全文搜索引擎 Apache Lucene™ 基础上的搜索引擎,功能强大,最近刚好要研究搜索这一块,简要记录备日后查阅 安装Java JDK,由于Lucene是用J ...
- elasticsearch中文分词+全文搜索demo
本文假设你已经搭建好elasticsearch服务器,并在上面装了kibana和IK中文分词组件 elasticsearch+kibana+ik的安装,之前的文章有介绍,可参考. mapping介绍: ...
- Elasticsearch快速入门和环境搭建
内容概述 什么是Elasticsearch,为什么要使用它? 基础概念简介 节点(node) 索引(index) 类型映射(mapping) 文档(doc) 本地环境搭建,创建第一个index 常用R ...
- ElasticSearch中文分词(IK)
ElasticSearch常用的很受欢迎的是IK,这里稍微介绍下安装过程及测试过程. 1.ElasticSearch官方分词 自带的中文分词器很弱,可以体检下: [zsz@VS-zsz ~]$ c ...
随机推荐
- LCD编程_简单测试
首先,需要编写一个led_test.c的文件,依据代码框架,在led_test.c中我们能够看到的只是led.c.我们是看不到led_controller.c的.比如说,在led_test.c中,需要 ...
- excel隔行选中内容如何操作
查看log日志是站长经常要做的事,从日志中可以发现很多问题,spider最近有没来爬,爬了哪些url,哪些页面不存在了等等,这些都可以看得到.然后你要根据不同的情况采取相应的措施.ytkah喜欢把这些 ...
- zzulioj - 2617 体检
题目链接: http://acm.zzuli.edu.cn/problem.php?id=2617 题目描述: VX玩了这么多游戏以后,感觉自己身体素质和智商都有所下降,所以决定去医院体检一下.已知V ...
- sublime3插件BracketHighlighter的配置
BracketHighlighter插件能为Sublime Text提供括号,引号这类高亮功能,但安装此插件后,默认没有高亮,只有下划线表示,不是很醒目,需要配置:1.在Sublime Text中用p ...
- Socket网络编程——C++实现
本代码可直接使用 根据TCP/IP三次握手,实验时可使用两台电脑,或者打开两个终端模拟通信. 服务器端: #include <iostream> #include <windows. ...
- 洛谷 P2996 [USACO10NOV]拜访奶牛Visiting Cows
P2996 传送门 题意: 给你一棵树,每一条边上最多选一个点,问你选的点数. 我的思想: 一开始我是想用黑白点染色的思想来做,就是每一条边都选择一个点. 可以跑两边一遍在意的时候染成黑,第二遍染成白 ...
- PATB1048数字加密
关于代码都是可以在PAT上跑通的 自己是在VS2017上写的,所以会有语句system("pause");,表示暂定方便查看结果. *在一个是VS2017中使用scanf会报错,所 ...
- ES6解构赋值常见用法
解构赋值出现的契机: let obj = { a: 1, b: 2 } // 取值 let a = obj.a let b = obj.b 问题核心: 每次取值既要确定对象属性名,还得重新定义一个变量 ...
- React_01_ECMAScript6
ECMAScript6 1.ES6简介 1.1.什么是ES6 ECMAScript 6.0(以下简称 ES6)是 JavaScript 语言的下一代标准,已经在 2015 年 6 月正式发布了.它的目 ...
- E-value identity bitscore
E-value: The E-value provides information about the likelihood that a given sequence match is purely ...