网格搜索与K近邻中更多的超参数
网格搜索与K近邻中更多的超参数
网格搜索,Grid Search:一种超参寻优手段;在所有候选的参数选择中,通过循环遍历,尝试每一种可能性,表现最好的参数就是最终的结果。(为什么叫网格搜索?以有两个参数的模型为例,参数a有3种可能,参数b有4种可能,把所有可能性列出来,可以表示成一个3*4的表格,循环过程就像是在每个网格里遍历、搜索,所以叫grid search)
一、knn网格搜索超参寻优
- 首先,准备好数据集。
from sklearn import datasets
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
digits = datasets.load_digits()
x = digits.data
y = digits.target
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
2. 创建网络搜索的参数:
param_grid = [
{
'weights':['uniform'],
'n_neighbor':[i for i in range(1, 11)]
},
{
'weights':['distance'],
'n_neighbor':[i for i in range(1, 11)],
'p':[i for i in range(1, 6)]
}
]
- 开始对knn的上述超参进行搜索:
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV
knn_clf = KNeighborsClassifier()
grid_search = GridSearchCV(knn_clf, param_grid)
%%time
grid_search.fit(x_train, y_train)
输出结果:
Wall time: 2min 20s
GridSearchCV(cv='warn', error_score='raise-deprecating',
estimator=KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=None, n_neighbors=5, p=2,
weights='uniform'),
fit_params=None, iid='warn', n_jobs=None,
param_grid=[{'weights': ['uniform'], 'n_neighbors': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]}, {'weights': ['distance'], 'n_neighbors': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10], 'p': [1, 2, 3, 4, 5]}],
pre_dispatch='2*n_jobs', refit=True, return_train_score='warn',
scoring=None, verbose=0)
grid_search.best_estimator_
grid_search.best_score_
grid_search.best_params_
knn_clf = grid_search.best_estimator_
knn_clf.predict(x_test)
knn_clf.score(x_test, y_test)
其实GridSearch这个类的超参数还有metric_params, metrics等。此外还有一些帮助我们更好理解网格搜索的参数,比如n_jobs表示计算机用多少个核进行。如果为-1表示使用全部的核。比如在搜索的过程中能够显示一些日志信息,verbose,这个值越大输出的值越详细,一般取2就够用了。
%%time
grid_search = GridSearchCV(knn_clf, param_grid, n_jobs=-1, verbose=2)
grid_search.fit(x_train, y_train)
输出结果:
Fitting 3 folds for each of 60 candidates, totalling 180 fits
[Parallel(n_jobs=-1)]: Done 29 tasks | elapsed: 9.5s
[Parallel(n_jobs=-1)]: Done 150 tasks | elapsed: 28.7s
Wall time: 35.5 s
[Parallel(n_jobs=-1)]: Done 180 out of 180 | elapsed: 35.4s finished
二、更多距离的定义
在knn中如果使用distance这个参数,默认使用的是明可夫斯基距离,其中如果p为1,就是曼哈顿距离,p为2,就是欧拉距离。除了这些还有一些距离的定义:
曼哈顿距离
例如在平面上,坐标(x1, y1)的i点与坐标(x2, y2)的j点的曼哈顿距离为:
d(i,j)=|X1-X2|+|Y1-Y2|.
欧式距离
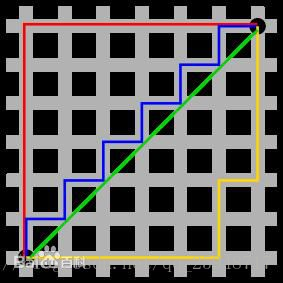

明可夫斯基距离
可以看做是曼哈顿距离和欧式距离的推广。
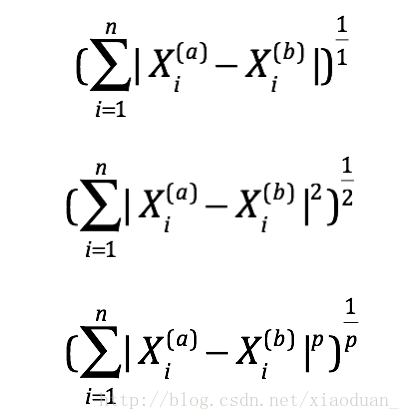
在数学中,距离是有严格定义的,需要满足三个性质:非负、对称、三角不等式成立。
1、向量空间余弦相似度
余弦相似度,又称为余弦相似性,是通过计算两个向量的夹角余弦值来评估他们的相似度。
两个向量间的余弦值可以通过使用欧几里得点积公式求出:

余弦距离,就是用1减去这个获得的余弦相似度。余弦距离不满足三角不等式,严格意义上不算是距离。
2、调整余弦相似度
修正cosine相似度的目的是解决cosine相似度仅考虑向量维度方向上的相似而没考虑到各个维度的量纲的差异性,所以在计算相似度的时候,做了每个维度减去均值的修正操作。
比如现在有两个点:(1,2)和(4,5),使用余弦相似度得到的结果是0.98。余弦相似度对数值的不敏感导致了结果的误差,需要修正这种不合理性就出现了调整余弦相似度,即所有维度上的数值都减去一个均值。那么调整后为(-2,-1)和(1,2),再用余弦相似度计算,得到-0.8。
3、皮尔森相关系数
也称皮尔森积矩相关系数(Pearson product-moment correlation coefficient) ,是一种线性相关系数。皮尔森相关系数是用来反映两个变量线性相关程度的统计量。
两个变量之间的皮尔逊相关系数定义为两个变量之间的协方差和标准差的商:

对比协方差公式:皮尔逊相关系数由两部分组成,分子是协方差公式,分母是两个变量的方差乘积。协方差公式有一些缺陷,虽然能反映两个随机变量的相关程度,但其数值上受量纲的影响很大,不能简单地从协方差的数值大小给出变量相关程度的判断。所以,皮尔森相关系数用方差乘积来消除量纲的影响。
4、杰卡德相似系数
杰卡德相似系数
两个集合A和B交集元素的个数在A、B并集中所占的比例,称为这两个集合的杰卡德系数。

杰卡德距离
杰卡德距离用两个两个集合中不同元素占所有元素的比例来衡量两个集合的区分度。
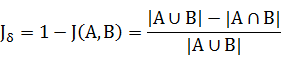
网格搜索与K近邻中更多的超参数的更多相关文章
- 【笔记】KNN之网格搜索与k近邻算法中更多超参数
网格搜索与k近邻算法中更多超参数 网格搜索与k近邻算法中更多超参数 网络搜索 前笔记中使用的for循环进行的网格搜索的方式,我们可以发现不同的超参数之间是存在一种依赖关系的,像是p这个超参数,只有在 ...
- 机器学习算法中的网格搜索GridSearch实现(以k-近邻算法参数寻最优为例)
机器学习算法参数的网格搜索实现: //2019.08.031.scikitlearn库中调用网格搜索的方法为:Grid search,它的搜索方式比较统一简单,其对于算法批判的标准比较复杂,是一种复合 ...
- 机器学习算法中如何选取超参数:学习速率、正则项系数、minibatch size
机器学习算法中如何选取超参数:学习速率.正则项系数.minibatch size 本文是<Neural networks and deep learning>概览 中第三章的一部分,讲机器 ...
- 机器学习(四) 机器学习(四) 分类算法--K近邻算法 KNN (下)
六.网格搜索与 K 邻近算法中更多的超参数 七.数据归一化 Feature Scaling 解决方案:将所有的数据映射到同一尺度 八.scikit-learn 中的 Scaler preprocess ...
- 1.K近邻算法
(一)K近邻算法基础 K近邻(KNN)算法优点 思想极度简单 应用数学知识少(近乎为0) 效果好 可以解释机器学习算法使用过程中的很多细节问题 更完整的刻画机器学习应用的流程 图解K近邻算法 上图是以 ...
- 机器学习中 K近邻法(knn)与k-means的区别
简介 K近邻法(knn)是一种基本的分类与回归方法.k-means是一种简单而有效的聚类方法.虽然两者用途不同.解决的问题不同,但是在算法上有很多相似性,于是将二者放在一起,这样能够更好地对比二者的异 ...
- 机器学习:使用scikit-learn库中的网格搜索调参
一.scikit-learn库中的网格搜索调参 1)网格搜索的目的: 找到最佳分类器及其参数: 2)网格搜索的步骤: 得到原始数据 切分原始数据 创建/调用机器学习算法对象 调用并实例化scikit- ...
- K近邻分类法
K近邻法 K近邻法:假定存在已标记的训练数据集,分类时对新的实例根据其K个最近邻的训练实例的类别,通过多数表决等分类决策规则进行预测. k近邻不具有显示学习的过程,是“懒惰学习”(lazy learn ...
- 机器学习随笔01 - k近邻算法
算法名称: k近邻算法 (kNN: k-Nearest Neighbor) 问题提出: 根据已有对象的归类数据,给新对象(事物)归类. 核心思想: 将对象分解为特征,因为对象的特征决定了事对象的分类. ...
随机推荐
- Eclipse中如何配置lombok
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/qq_41441210/article/d ...
- Fiborial 题解——2019.10.14
一看到这个题 就感觉...cao,, 什么东西...??! 然后就开始暴力求Fn 然鹅我并不会写高精(我太菜了) 只能求到大概10左右 在吧Fn给质因数分解 求出其因子个数 妄图找到什么有关的规律 但 ...
- .NET总结--ASP.NET工作原理
前言 前前后后写了不少关于某些技术啥的博客,一直在追新求深,而真正使用上的时候才发现了解的太少太少了,从事.net开发三年有余了不是它不行了而是我坚持不住了,如今不得不向生活低头,这个系列作为三年技术 ...
- BDD的概念
BDD的概念Behavior-Driven Development (BDD) is a set of software engineering practices designed to help ...
- 初始化错误——从一个简单的算例看UDF各个宏的调用顺序
感谢西安交通大学en_phert的问题和尝试 Fluent版本:Fluent 19.0 Visual Studio版本:Visual Studio 2013 在UDF的宏的调用中大家常看见下图: 这个 ...
- Tocmat 统计tomcat进程内的线程数
获取tomcat进程pid ps -ef | grep tomcat 统计该tomcat进程内的线程个数 ps -Lf 558899 | wc -l
- Hash算法及java HashMap底层实现原理理解(含jdk 1.7以及jdk 1.8)
现在很多公司面试都喜欢问java的HashMap原理,特在此整理相关原理及实现,主要还是因为很多开发集合框架都不甚理解,更不要说各种其他数据结构了,所以造成面子造飞机,进去拧螺丝. 1.哈希表结构的优 ...
- 使用 Microsoft.Web.Administration 管理iis
How to Automate IIS 7 Configuration with .NET How to Automate IIS 7 Configuration with .NET Are you ...
- Python10大热门项目
文章地址:https://baijiahao.baidu.com/s?id=1625230403885659615&wfr=spider&for=pc 今天给大家盘点一下实验楼最热门的 ...
- 试图从目录中执行 CGI、ISAPI 或其他可执行程序
首先来看我遇到问题时的情况,直接上图! 从上图的错误提示信息可以看出,是权限不够,被拒绝访问,开始我以为是我的程序的php程序的原因,但是其他站点没事啊,就对这个站点的权限重新分配了下,给了最高权 ...