c# 爬虫(二) 模拟登录
有了上一篇的介绍,这次我们来说说模拟登录,上一篇见 :c# 爬虫(一) HELLO WORLD
原理
我们知道,一般需要登录的网站,服务器和客户端都会有一段时间的会话保持,而这个会话保持是在登录时候建立的, 服务端和客户端都会持有这个KEY,在后续访问时,都需要核对这两个KEY是否一致。 而客户端的这个KEY就存在cookie中。 因此,我们需要获取登录后的cookie值,并在后续的访问中,都添加这个cookie。这样才能做到模拟登录的效果。
例子:
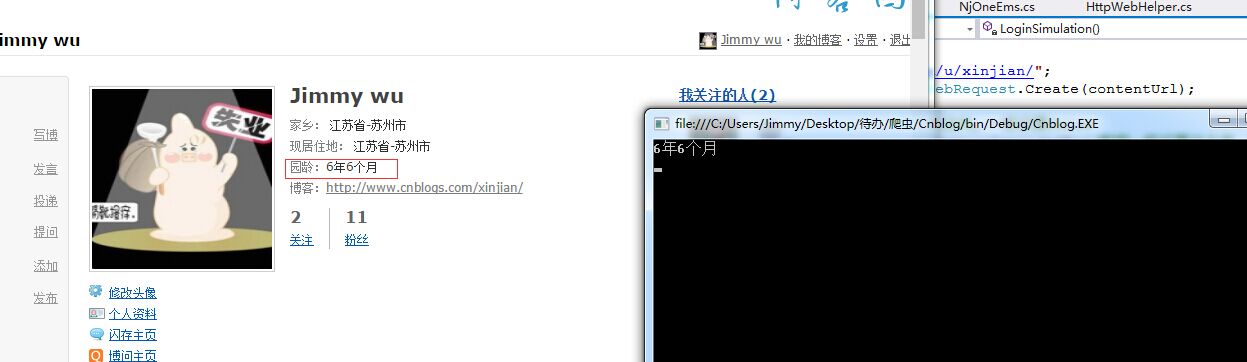
我们以获取博客园首页的园龄为例。需要做三步
1. 模拟登录博客园
2. 构建个人主页的Request请求,包括cookie
3. 获取个人主页的数据后, 分析页面,并获取园龄的数据。
代码如下:
static void Main(string[] args)
{
//string html= Hello();
string html = LoginSimulation();
Console.WriteLine(html);
Console.Read();
}
static string LoginSimulation()
{ string url = "https://passport.cnblogs.com/user/signin";
string postData = "{\"input1\":\"MvxmwEWfUF26IvKNa1dUiZn1xmSBhNW0wJyoaUlDPXoh+Mb+z2eZK3r3c9Jd0aT0/Wzz3ht7LMeTllu8ISY9nfQIuKB0C19Y9/IfKYSktpZZOVaKx/XP3i/mGxXC3K5m2la91ViRh3BO36xT4E98dbqVHPtynjuNafuVIBF5a2M=\",\"input2\":\"xxxx":false}"; //1.获取登录Cookie
HttpWebRequest req = (HttpWebRequest)WebRequest.Create(url);
req.Method = "POST";// POST OR GET, 如果是GET, 则没有第二步传参,直接第三步,获取服务端返回的数据
req.AllowAutoRedirect = false;//服务端重定向。一般设置false
req.ContentType = "application/x-www-form-urlencoded";//数据一般设置这个值,除非是文件上传 byte[] postBytes = Encoding.UTF8.GetBytes(postData);
req.ContentLength = postBytes.Length;
Stream postDataStream = req.GetRequestStream();
postDataStream.Write(postBytes, , postBytes.Length);
postDataStream.Close(); HttpWebResponse resp = (HttpWebResponse)req.GetResponse();
string cookies = resp.Headers.Get("Set-Cookie");//获取登录后的cookie值。 //2.登录想爬取页面的构造,主要多一个Cookie的构造
string contentUrl = "https://home.cnblogs.com/u/xinjian/";
HttpWebRequest reqContent = (HttpWebRequest)WebRequest.Create(contentUrl);
reqContent.Method = "GET";
reqContent.AllowAutoRedirect = false;//服务端重定向。一般设置false
reqContent.ContentType = "application/x-www-form-urlencoded";//数据一般设置这个值,除非是文件上传 reqContent.CookieContainer = new CookieContainer();
reqContent.CookieContainer.SetCookies(reqContent.RequestUri, cookies);//将登录的cookie值赋予此次的请求。 HttpWebResponse respContent = (HttpWebResponse)reqContent.GetResponse();
string html = new StreamReader(respContent.GetResponseStream()).ReadToEnd(); //3. 分析读取该页面的数据,可以使用HtmlAgilityPack第三方类,这里比较简单,自己写个获取方法就行
string age= GetVal(html, "<span title='入园时间:2010-6-28'>", "</span>");
return age;
}
注意事项
1. 本次模拟登录,我发现chrome的开发人员工具,并没有抓到真正的Post包,和我之前遇到的情况一样, 后来还是使用了httpwatch后,才抓到了真正的数据包。博客园做的不错,提交的数据进行了加密。 当然我的密码我也已经改成了XXX,用户需要运行的话,需要自行抓包获取对应的postData。
2. 针对cookie的赋值,主要由这两句完成
reqContent.CookieContainer = new CookieContainer();
reqContent.CookieContainer.SetCookies(reqContent.RequestUri, cookies);//将登录的cookie值赋予此次的请求。
但是听说C#封装的不是很好,有时候会漏掉数据,但我目前还没遇到过, 如果遇到,需要将cookie的string手工转换成CookieCollection,并赋予CookieContainer。
3. 针对ASP.NET的网页, 会存在__VIEWSTATE & __EVENTVALIDATION 这两个post字段, 对于没建立会话时,这两个值是不会变的,而一旦建立会话(模拟登陆后),每次访问的页面,这两个值都会改变, 解决办法是先使用GET获取该页面的数据后,获取这两个字段的值, 然后在post的时候,进行赋值。
4. 在遇到500错误的时候,说实话,我也很头疼,不知道如何调试,但我总结下来,一定是request构建的不对。主要查看如下问题:
4.1. 对比post的数据的key和value,看看格式是否正确,如是否进行了编码 WebUtility.UrlEncode()。
4.2. 对比post的数据的,是否Post了全部的数据, 当然这里不光是当前页面,有时候还会用到其他页面,我举个例子, 我在订单页面上传附件, 在附件上传页面,发现并没有Post订单的id,那么这个时候,就需要查找订单的id服务端是什么时候获取的,这个时候就需要猜了,有可能是在打开订单页面的时候,服务端就把此id存储到session中了。所以先需要模拟打开订单页面,然后在模拟订单附件上传的post。
4.3 注意是是否犯了__VIEWSTATE & __EVENTVALIDATION的错误,注意,针对数据型的post,需要进行urlEncode。
4.4 Request的Head是否构建全了, 有时候客户端会提交自定义的head,注意查看。同时UserAgent有时候也会需要进行变化,但目前我还没遇到过。
4.5. 如果确定Post的数据全了,并且还是500错误的话,考虑下是否cookie有问题,虽然我还没遇到过。
目前就想到这么多,模拟登录当时我也卡了两天,主要当时对__VIEWSTATE & __EVENTVALIDATION的理解还是不够,后续如果有疑问的话,我会专门开一篇ASP.NET的模拟登录。
参考文献:
http://www.crifan.com/emulate_login_website_using_csharp/
http://www.cnblogs.com/zuoguanglin/archive/2012/03/28/2421153.html
https://msdn.microsoft.com/en-us/library/ms972976.aspx
c# 爬虫(二) 模拟登录的更多相关文章
- Python爬虫-百度模拟登录(二)
上一篇-Python爬虫-百度模拟登录(一) 接上一篇的继续 参数 codestring codestring jxG9506c1811b44e2fd0220153643013f7e6b1898075 ...
- Python爬虫之模拟登录微信wechat
不知何时,微信已经成为我们不可缺少的一部分了,我们的社交圈.关注的新闻或是公众号.还有个人信息或是隐私都被绑定在了一起.既然它这么重要,如果我们可以利用爬虫模拟登录,是不是就意味着我们可以获取这些信息 ...
- Java爬虫——人人网模拟登录
人人网登录地址:http://www.renren.com/ 此处登录没有考虑验证码验证码. 首先对登录方法进行分析 有两种方法. 一)在Elements中分析源码 发现登录点击后的事件是http:/ ...
- Python爬虫-百度模拟登录(一)
千呼万唤屎出来呀,百度模拟登录终于要呈现在大家眼前了,最近比较忙,晚上又得早点休息,这篇文章写了好几天才完成.这个成功以后,我打算试试百度网盘的其他接口实现.看看能不能把服务器文件上传到网盘,好歹也有 ...
- Python 爬虫之模拟登录
最近应朋友要求,帮忙爬取了小红书创作平台的数据,感觉整个过程很有意思,因此记录一下.在这之前自己没怎么爬过需要账户登录的网站数据,所以刚开始去看小红书的登录认证时一头雾水,等到一步步走下来,最终成功, ...
- urllib库利用cookie实现模拟登录慕课网
思路 1.首先在网页中使用账户和密码名登录慕课网 2.其次再分析请求头,如下图所示,获取到请求URL,并提取出cookie信息,保存到本地 3.最后在代码中构造请求头,使用urllib.request ...
- 模拟登录新浪微博(Python)
PC 登录新浪微博时, 在客户端用js预先对用户名.密码都进行了加密, 而且在POST之前会GET 一组参数,这也将作为POST_DATA 的一部分. 这样, 就不能用通常的那种简单方法来模拟POST ...
- C#程序模拟登录批量获取各种邮件内容信息
一般来说,如果现实中你有这样一种需求“假如你是褥羊毛的羊毛党,你某日发现了一个app有一个活动,通过邮箱注册账号激活可以领5元红包,而恰恰你手上又有一批邮箱可用,那么批量获取邮箱中的激活链接去激活则是 ...
- 模拟登录新浪微博(Python) - 转
Update: 如果只是写个小爬虫,访问需要登录的页面,采用填入cookie 的方法吧,简单粗暴有效,详细见:http://www.douban.com/note/264976536/模拟登陆有时需要 ...
- Java爬虫模拟登录——不给我毛概二的H某大学
你的账号访问太频繁,请一分钟之后再试! 从大一开始 就用脚本在刷课 在专业课踢的只剩下一门C#的情况下 活活刷到一周的课 大二开始教务系统多了一个非常**的操作 退课池 and 访问频繁缓冲 难道,我 ...
随机推荐
- Sublime Text 3图标更改
Sublime Text 3图标更改 步骤: 1.下载ico图标 2.然后更改图标 注意:重点讲解下,如何将png文件转换为ico图标: 网络上单独找sublime text 3的ico图标比较不好找 ...
- 2018-2019-1 20189215《Linux内核原理与分析》第五周作业
<庖丁解牛>第四章书本知识总结 系统调用的三层机制 API(应用程序编程接口) 中断向量(系统调用处理入口) 服务程序(系统调用内核处理系统) 计算机的硬件资源是有限的,为了减少有限资源的 ...
- 如何把本地git仓库托管到码云上
提交代码到本地git仓库 git init git status git add . git status git commit -m "init my project" ...
- git中Untracked files如何清除
$ git status # On branch test # Untracked files: # (use "git add <file>..." to inclu ...
- cygwin安装方法
一.环境 OS:windows 二.安装cygwin以及各类cygwin下的软件 2.1 从官网http://www.cygwin.com/获取最新的版本 2.2 安装过程如下图
- Nginx反向代理缓冲区优化
内容目录 proxy_buffering proxy_buffer_size proxy_buffers proxy_busy_buffers_size proxy_max_temp_file_siz ...
- UVa 11552 最小的块数(序列划分模型:状态设计)
https://vjudge.net/problem/UVA-11552 题意:输入一个正整数k和字符串S,字符串的长度保证为k的倍数.把S的字符按照从左到右的顺序每k个分成一组,每组之间可以任意重排 ...
- UVa 10054 项链(欧拉回路)
https://vjudge.net/problem/UVA-10054 题意:有一种由彩色珠子连接成的项链.每个珠子的两半由不同颜色组成.相邻两个珠子在接触的地方颜色相同.现在有一些零碎的珠子,需要 ...
- python 执行字符串中的python代码
mycode = 'print("hello world")' code = """ def mutiply(x,y): return x*y pri ...
- Mac Hadoop2.6(CDH5.9.2)伪分布式集群安装
操作系统: MAC OS X 一.准备 1. JDK 1.8 下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-dow ...