NLTK和Stanford NLP两个工具的安装配置
这里安装的是两个自然语言处理工具,NLTK和Stanford NLP。
声明:笔者操作系统是Windows10,理论上Windows都可以;
版本号:NLTK 3.2
Stanford NLP 3.6.0
JDK 1.8
重要文件在讲述过程中会以网盘链接给出,可随时下载。
注:笔者是通过Anaconda安装的python,所以有关路径都与Anaconda有关。
一、 NLTK的安装

下载后直接运行exe文件进行安装,会自动匹配到python安装路径,如果没有找到路径则说明NLTK版本不正确,或者说python版本不正确。
3. 打开python编辑器,输入“import nltk”,再输入“nltk.download()”,下载NLTK数据包,在下载界面选中book模块,这个模块包含了许多数据案例和内置函数。
修改book下载目的路径建议如下:D:\DevelopmentTools\Anaconda3\nltk_data,也就是在Anaconda下创建一个nltk_data的文件夹,将book下载目标路径放在此处即可,这样做便于管理和维护。如下如:
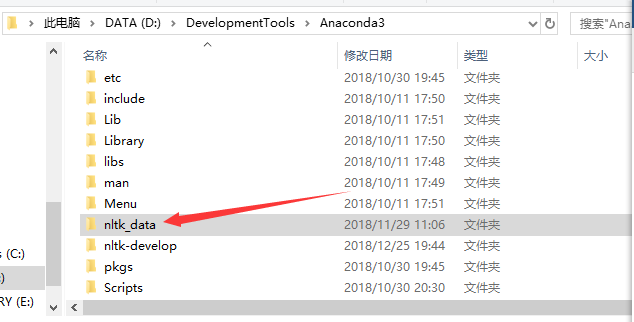
4、环境变量的配置:计算机→属性→高级系统设置→高级→环境变量-系统变量→path,在path中加入刚刚定的路径:D:\DevelopmentTools\Anaconda3\nltk_data
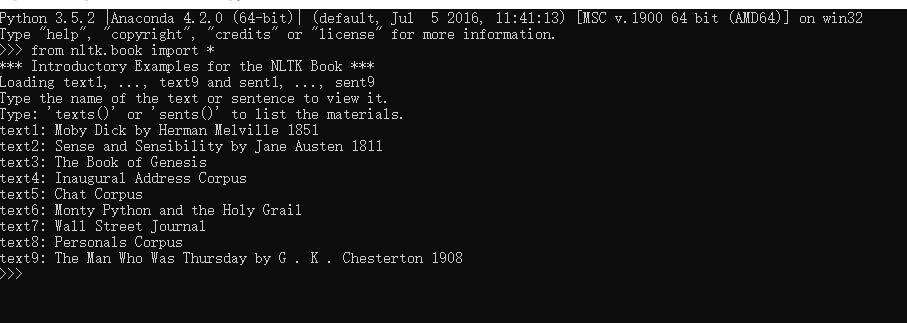
5、配置完成之后,打开python编辑器,输入from nltk.book import *,只要没有输出明显的错误,正确显示了相关信息,就表示NLTK安装成功了,如下图:
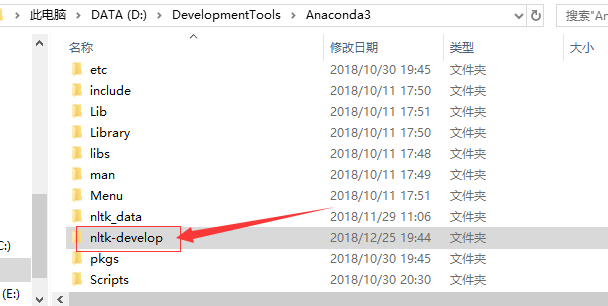
二、Stanford NLP工具的安装
3、然后进入Windows的cmd命令行
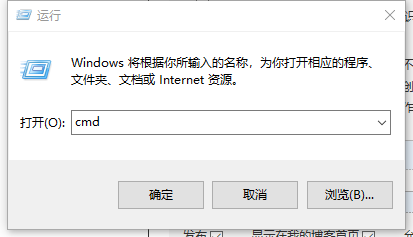
从命令进入到刚刚复制的路径下:D:\DevelopmentTools\Anaconda3\nltk-develop ,然后输入python setup.py install,并执行 如下:
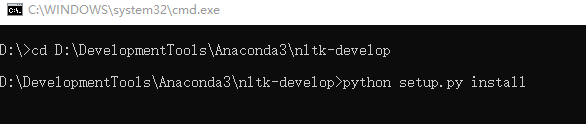
等待安装即可,由于笔者已经安装过了,就不展示安装后的信息了。
4、Stanford NLP版本是3.6.0,所有文件可在网盘下载:https://pan.baidu.com/s/15y7gfy167cfLJhvRurWMCA
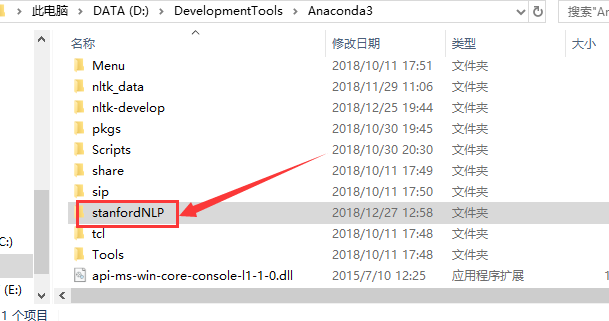
5、下面就来开始设置刚刚“stanfordNLP”文件夹下各个文件的环境变量,环境变量都是在系统变量的classpath中来操作。
设置环境变量的目的是为了能随时快速的调用,设置环境变量之后,以后的所有调用都不需要传输绝对路径的参数了。
(1)StanfordSegmenter环境变量的设置
进入“stanfordNLP”文件夹,将stanford-segmenter.jar的绝对路径拷贝到classpath下,分别如下:
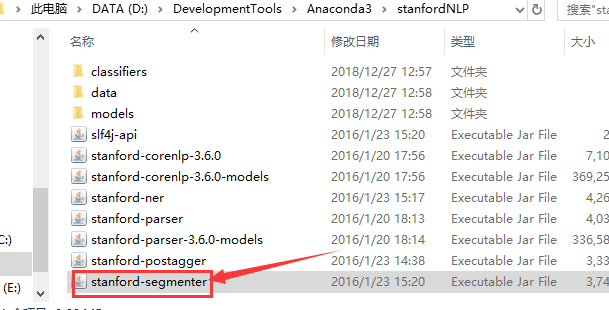
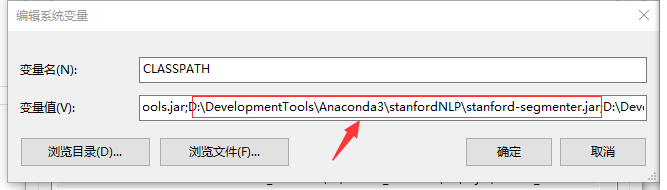
注意,每一个不同路径之间要用分号分隔。
(2)slf4j-api.jar加入classpath环境变量。slf4j-api.jar是stanford-segmenter-2015-12-09.zip解压后含有的文件。
同理,将“stanfordNLP”中的slf4j-api.jar的绝对路径加入到classpath中去,如下:

(3)StanfordPOSTagger环境变量的设置
同理,进入“stanfordNLP”文件夹,将stanford-postagger.jar文件的绝对路径添加到classpath中,如下:

(4)StanfordNERTagger环境变量的设置
同理,进入“stanfordNLP”文件夹,将stanford-ner.jar文件的绝对路径添加到classpath中,如下:
(5)将classifiers文件夹也添加入classpath环境变量。classifiers文件夹是从stanford-ner-2015-12-09.zip解压后含有的文件夹,直接复制提取的
(6)将models文件夹添加入classpath环境变量。models文件夹是stanford-postagger-full-2015-12-09.zip解压后含有的文件夹。环境变量如下:
(7)StanfordParser环境变量的设置
同理,进入“stanfordNLP”文件夹,将stanford-parser.jar和stanford-parser-3.6.0-models.jar分别添加到classpath环境变量中去,分别如下:

(8)StanfordNeuralDependencyParser环境变量的设置
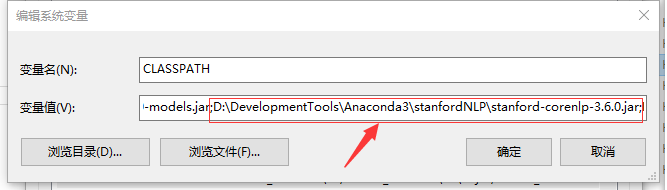
同上,进入“stanfordNLP”文件夹,分别将stanford-corenlp-3.6.0.jar和stanford-corenlp-3.6.0-models.jar添加入classpath环境变量,分别如下:

三、测试
由于Stanford NLP工具安装最繁琐,也最容易出问题,于是特别展示对Stanford NLP的测试,所有简短的代码都是在python编辑器中执行的,其它地方也可:
代码如下:
路径:相应路径是笔者前面安装所使用的路径,结合更改为自己电脑的实际路径。只要按照上述步骤将所有环境变量配置了,那么,在所有函数的调用中,函数参数就不用再输入绝对路径了,只需要直接输入相应的文件名即可,函数运行时自会在环境变量的路径下来找该文件,找不到的话就会报错的。
(1)中文分词
segmenter = StanfordSegmenter(
path_to_sihan_corpora_dict="D:\DevelopmentTools\Anaconda3\stanfordNLP\data\", path_to_model="D:\DevelopmentTools\Anaconda3\stanfordNLP\data\pku.gz", path_to_dict="D:\DevelopmentTools\Anaconda3\stanfordNLP\data\dict-chris6.ser.gz")
str="我在博客园开了一个博客,我的博客名字叫钝学累功。"
result = segmenter.segment(str)
tokenizer=StanfordTokenizer()
sent="Good muffins cost $3.88\nin New York. Please buy me\ntwo of them.\nThanks."
print(tokenizer.tokenize(sent))
(1)英文命名实体识别
from nltk.tag import StanfordNERTagger
eng_tagger=StanfordNERTagger(model_filename=r'D:\DevelopmentTools\Anaconda3\stanfordNLP\classifiers\english.all.3class.distsim.crf.ser.gz')
print(eng_tagger.tag('Rami Eid is studying at Stony Brook University in NY'.split()))
(1)英文词性标注
from nltk.tag import StanfordPOSTagger
eng_tagger=StanfordPOSTagger(model_filename=r'D:\DevelopmentTools\Anaconda3\stanfordNLP\models\english-bidirectional-distsim.tagger')
print(eng_tagger.tag('What is the airspeed of an unladen swallow ?'.split()))
from nltk.tag import StanfordPOSTagger
chi_tagger=StanfordPOSTagger(model_filename=r'chinese-distsim.tagger')
result="四川省 成都 信息 工程 大学 我 在 博客 园 开 了 一个 博客 , 我 的 博客 名叫 钝学累功 。 \r\n"
print(chi_tagger.tag(result.split()))
(1)英文句法分析
from nltk.parse.stanford import StanfordParser
eng_parser=StanfordParser()
print(list(eng_parser.parse("the quick brown for jumps over the lazy dog".split())))
from nltk.parse.stanford import StanfordParser
chi_parser=StanfordParser()
sent=u'北海 已 成为 中国 对外开放 中 升起 的 一 颗 明星'
print(list(chi_parser.parse(sent.split())))
(1)英文依存句法分析
from nltk.parse.stanford import StanfordDependencyParser
eng_parser=StanfordDependencyParser()
res=list(eng_parser.parse("the quick brown fox jumps over the lazy dog".split()))
for row in res[0].triples():
print(row)
from nltk.parse.stanford import StanfordDependencyParser
chi_parser=StanfordDependencyParser()
res=list(chi_parser.parse(u'四川 已 成为 中国 西部 对外开放 中 升起 的 一 颗 明星'.split()))
for row in res[0].triples():
print(row)
总结,环境变量的设置总的来说是自由的,但是要设置的便于自己识别和 维护,笔者只是提供了自己的设置方案。只要能正常运行上述测试代码,就表示Stanford NLP和NLTK安装成功了,之后开发可以结合两个工具一起使用。。。
参考链接:https://www.jianshu.com/p/4b3c7e7578e6
NLTK和Stanford NLP两个工具的安装配置的更多相关文章
- 【NLP】干货!Python NLTK结合stanford NLP工具包进行文本处理
干货!详述Python NLTK下如何使用stanford NLP工具包 作者:白宁超 2016年11月6日19:28:43 摘要:NLTK是由宾夕法尼亚大学计算机和信息科学使用python语言实现的 ...
- [转]【NLP】干货!Python NLTK结合stanford NLP工具包进行文本处理 阅读目录
[NLP]干货!Python NLTK结合stanford NLP工具包进行文本处理 原贴: https://www.cnblogs.com/baiboy/p/nltk1.html 阅读目录 目 ...
- 代码静态分析工具PC-LINT安装配置
代码静态分析工具PC-LINT安装配置--step by step 作者:ehui928 ...
- 第【一】部分Netzob项目工具的安装配置
第[一]部分Netzob项目工具的安装配置 声明: 1)本报告由博客园bitpeach撰写,版权所有,免费转载,请注明出处,并请勿作商业用途. 2)若本文档内有侵权文字或图片等内容,请联系作者bitp ...
- python操作三大主流数据库(3)python操作mysql③python操作mysql的orm工具sqlaichemy安装配置和使用
python操作mysql③python操作mysql的orm工具sqlaichemy安装配置和使用 手册地址: http://docs.sqlalchemy.org/en/rel_1_1/orm/i ...
- 画图工具Graphviz安装配置
Graphviz (英文:Graph Visualization Software的缩写)是一个由AT&T实验室启动的开源工具包,用于绘制DOT语言脚本描述的图形.它也提供了供其它软件使用的库 ...
- ②---Java开发工具Eclipse安装配置
Java开发工具Eclipse安装及配置 以下将为大家介绍Java开发工具Eclipse安装及配置. 一.下载Eclipse安装文件 正所谓工欲善其事必先利其器,我们在开发java语言过程中同样需要依 ...
- Linux性能实时监测工具netdata安装配置
netdata:功能强大的实时性能检测工具,展示地址. github地址:https://github.com/firehol/netdata 本文介绍在CentOS 6.7下安装netdata 1. ...
- BUG管理工具——Mantis安装配置
配置环境: CentOS6.5(所有操作在root用户下面操作) 1. 关闭防火墙, service iptables stop(防止防火墙捣乱,或者还得手动添加端口号的麻烦) 2. Disable ...
随机推荐
- python的pip源在windows和linux修改
windows和linux修改python的pip源 https://www.cnblogs.com/cwp-bg/p/8497075.html windows和linux修改python的pip源 ...
- CH1806 Matrix
题意 描述 给定一个M行N列的01矩阵(只包含数字0或1的矩阵),再执行Q次询问,每次询问给出一个A行B列的01矩阵,求该矩阵是否在原矩阵中出现过. 输入格式 第一行四个整数M,N,A,B. 接下来一 ...
- vue+webpack多个项目共用组件动态打包单个项目
原文复制:https://www.jianshu.com/p/fa19a07b1496 修改了一些东西,因为sh脚本不能再window电脑执行,所以改成了node脚本.这是基于vue-cli2.0配置 ...
- sysfs文件系统学习--sysfs
一.sysfs简介1.sysfs就是利用VFS的接口去读写kobject的层次结构,建立起来的文件系统.其更新与删除是那些xxx_register()/unregister()做的事 情.从sysfs ...
- cratedb 集群搭建说明
此为搭建说明,实际上搭建过es 集群的都是可以的,和es 基本一样 配置文件 crate.yaml 参考集群架构图 集群名称 cluster.name: my_cluster 每个node节点名称 如 ...
- 显示Deprecated: Assigning the return value of new by reference is deprecated in解决办法
很多朋友的php程序当php的版本升级到5.3以后,会出现”Deprecated: Assigning the return value of new by reference is deprecat ...
- mschart 使用心得和部署。
参考: http://www.cnblogs.com/suguoqiang/archive/2013/01/16/2862945.html 1.在统计时可能需要多条数据,需要整合数据源 Chart1. ...
- (判断)window.open()窗口被关闭后执行事件
$(function() { // start ready var $article_share=$('#body .article').find('li.share'); // $article_s ...
- 黄聪:js 获取浏览器、Body、滚动条、可见区域、页面、边框、窗口高度和宽度值(多浏览器)
IE中:document.body.clientWidth ==> BODY对象宽度document.body.clientHeight ==> BODY对象高度document.docu ...
- 黄聪:利用iframe实现ajax 跨域通信的解决方案(转)
原文:http://www.cnblogs.com/xueming/archive/2013/02/01/crossdomainajax.html 在漫长的前端开发旅途上,无可避免的会接触到ajax, ...