1st 英文文章词频统计
英文文章词频统计:
功能:统计一篇英文文章的单词总数及出现频数并输出,之后排序,输出频数前十的单词及其频数。
实现方法:使用C语言,用fopen函数读入txt文件,fscanf函数逐个读入单词,结构体wordNode存储单词及其频数,以链表的形式连接在一起,最后使用插入排序进行分析,输出频数最高的5个单词。
头文件
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
定义宏
#define ERROR 1
#define OK 0
#define WORD_LENGTH 250
自定义数据类型
typedef int status; typedef struct Node
{
char word[WORD_LENGTH];
int time;
struct Node *next;
}wordNode;
定义全局变量
wordNode *headNode = NULL;
声明所有使用的函数
wordNode *wordSearch(char *word,int *num);
status wordCount(char *word,int *num);
void printCountList(int *num);
void PrintFirstFiveTimes();
void mergeSort(wordNode **head);
void FrontBackSplit(wordNode *head,wordNode **pre,wordNode **next);
void wordJob(char word[]);
wordNode *SortedMerge(wordNode *pre,wordNode *next);
void release();
主函数
status main(int argc,char *argv[])
{
char temp[WORD_LENGTH];//定义用以临时存放单词的数组
FILE *file;
int count;
int articleWordNum = ;//定义统计结点个数的变量
int *num = &articleWordNum;
if((file = fopen("F:\\zc\\c\\yjs\\file.txt", "r")) == NULL)
{
printf("文件读取失败!");
exit();
}
while((fscanf(file,"%s",temp))!= EOF)
{
wordJob(temp);
count = wordCount(temp,num);
}
fclose(file);
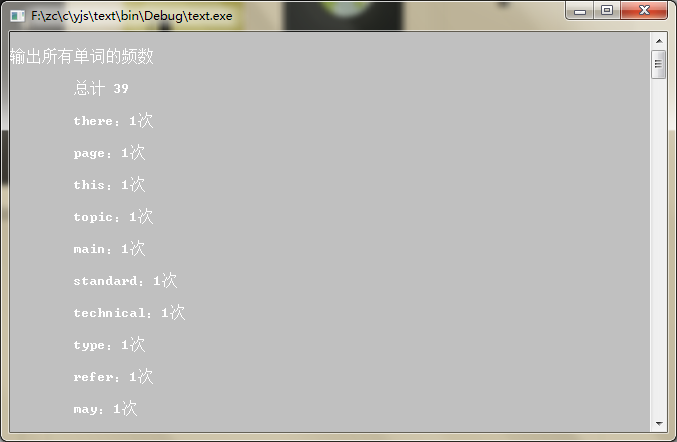
printf("\n输出所有单词的频数\n");
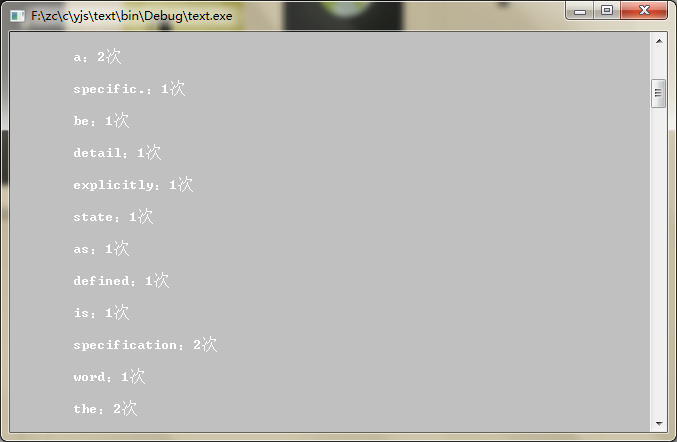
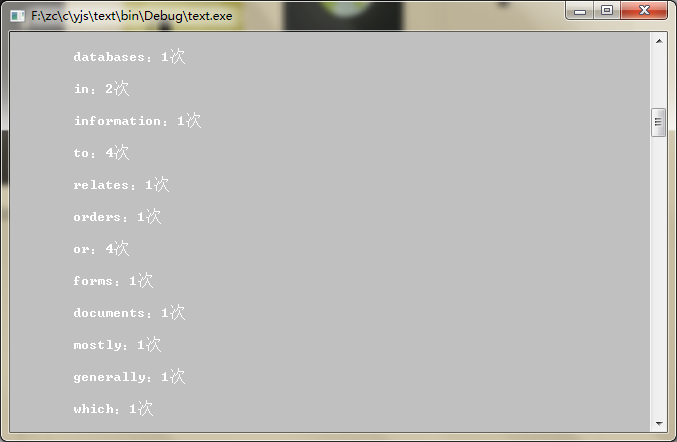
printCountList(num);
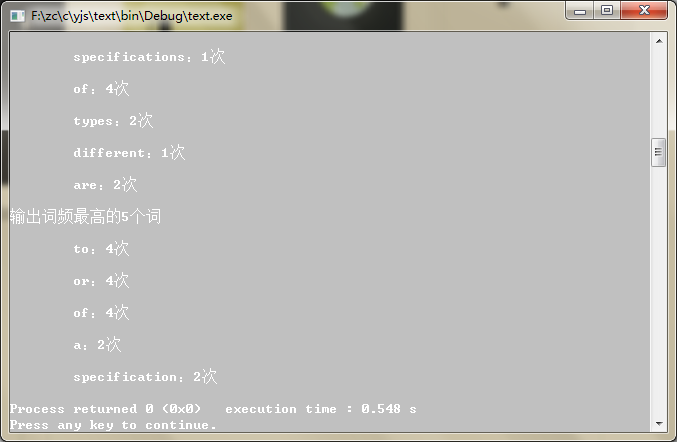
printf("\n输出词频最高的5个词\n");
mergeSort(&headNode); //排序
PrintFirstFiveTimes();
release();
return ;
}
查找单词所在结点并返回其地址
wordNode *wordSearch(char *word,int *num)
{
wordNode *node;
wordNode *nextNode = headNode;
wordNode *preNode = NULL;
char a[WORD_LENGTH];
if(headNode == NULL)
{
node = (wordNode*)malloc(sizeof(wordNode));
strcpy(node->word, word);
node->time = ;
*num+=;
headNode = node;
return node;
}
while(nextNode != NULL) //查找匹配单词
{
strcpy(a,nextNode->word);
if(strcmp(a, word) == )
{
return nextNode;
}
preNode = nextNode;
nextNode = nextNode->next;
} if(nextNode == NULL)
{
node = (wordNode*)malloc(sizeof(wordNode));
strcpy(node->word, word);
node->time = ;
node->next = headNode->next;
headNode->next = node;
*num+=;
return node;
}
else
return nextNode;
}
进行词频统计
status wordCount(char *word,int *num)
{
wordNode *tmpNode = NULL;
tmpNode = wordSearch(word,num); //word所在的节点
if(tmpNode == NULL)
{
return ERROR;
}
tmpNode->time++;
return ;
}
输出所有词频
void printCountList(int *num)
{
if(headNode == NULL)
{
printf("该文件无内容!");
}
else
{
wordNode *preNode = headNode;
printf("\n\t总计 %d \n",*num);
while(preNode != NULL)
{
printf("\n\t%s:%d次\n",preNode->word,preNode->time);
preNode = preNode->next;
}
}
}
输出词频最高的10个词
void PrintFirstFiveTimes()
{
if(headNode == NULL)
{
printf("该文件无内容!");
}
else
{
wordNode *preNode = headNode;
int i = ;
while (preNode != NULL && i<=)
{
printf("\n\t%s:%d次\n",preNode->word,preNode->time);
preNode = preNode->next;
i++;
}
}
}
对词频统计结果进行归并排序
void mergeSort(wordNode **headnode)
{
wordNode *pre,*next,*head;
head = *headnode;
if(head == NULL || head->next == NULL)
{
return;
}
FrontBackSplit(head,&pre,&next);
mergeSort(&pre);
mergeSort(&next);
*headnode = SortedMerge(pre,next);
}
取尾节点
void FrontBackSplit(wordNode *source,wordNode **pre,wordNode **next)
{
wordNode *fast;
wordNode *slow;
if(source == NULL || source->next == NULL)
{
*pre = source;
*next = NULL;
}
else
{
slow = source;
fast = source->next;
while(fast != NULL)
{
fast = fast->next;
if(fast != NULL)
{
slow = slow->next;
fast = fast->next;
}
}
*pre = source;
*next = slow->next;
slow->next = NULL;
}
}
取频数最大的节点作为头节点
wordNode *SortedMerge(wordNode *pre,wordNode *next)
{
wordNode *result = NULL;
if(pre == NULL)
return next;
else if(next == NULL)
return pre;
if(pre->time >= next->time)
{
result = pre;
result->next = SortedMerge(pre->next,next);
}
else
{
result = next;
result->next = SortedMerge(pre,next->next);
}
return result;
}
处理单词
void wordJob(char word[])
{
int i,k;
for(i = ;i<strlen(word);i++)
{
if(word[i]>='A'&& word[i]<='Z')
{
word[i] += ;
continue;
}
if(word[i]<'a'||word[i]>'z')
{
if(i == (strlen(word)-))
{
word[i] = '\0';
}
else
{
k = i;
while(i < strlen(word))
{
word[i] = word[i+];
i++;
}
i = k;
}
}
}
}
释放所有结点内存
void release()
{
if(headNode == NULL)
return;
wordNode *pre = headNode;
while(pre != NULL)
{
headNode = pre->next;
free(pre);
pre = headNode;
}
}
git@git.coding.net:amberpass/Calculate_words.git
https://git.coding.net/amberpass/Calculate_words.git
程序运行结果:
1st 英文文章词频统计的更多相关文章
- 【第二周】Java实现英语文章词频统计(改进1)
本周根据杨老师的spec对英语文章词频统计进行了改进 1.需求分析: 对英文文章中的英文单词进行词频统计并按照有大到小的顺序输出, 2.算法思想: (1)构建一个类用于存放英文单词及其出现的次数 cl ...
- 【第二周】Java实现英语文章词频统计
1.需求:对于给定的英文文章进行单词频率的统计 2.分析: (1)建立一个如下图所示的数据库表word_frequency用来存放单词和其对应数量 (2)Scanner输入要查询的英文文章存入Stri ...
- java词频统计——web版支持
需求概要: 1.把程序迁移到web平台,通过用户上传TXT的方式接收文件. 2.用户直接输入要统计的文本,服务器返回结果 3.在页面上给出链接 (如果有封皮.作者.字数.页数等信息更佳)或表格,展示经 ...
- 词频统计Web工程
本次将原本控制台工程迁移到了web工程上.. 需求: 1.把程序迁移到web平台,通过用户上传TXT的方式接收文件: 2.在页面上给出链接 (如果有封皮.作者.字数.页数等信息更佳)或表格,展示经典英 ...
- 个人项目----词频统计WEB(部分功能)
需求分析 1.使用web上传txt文件,对上传的txt进行词频统计. 2.将统计后的结果输出到web页面,力求界面优美. 3.在界面上展示所给url的文章词频统计,力求界面优美. 3.将每个单词同四. ...
- Java实现的词频统计——Web迁移
本次将原本控制台工程迁移到了web工程上,依旧保留原本控制台的版本. 需求: 1.把程序迁移到web平台,通过用户上传TXT的方式接收文件: 2.在页面上给出链接 (如果有封皮.作者.字数.页数等信息 ...
- 1.字符串操作:& 2.英文词频统计预处理
1.字符串操作: 解析身份证号:生日.性别.出生地等. ID = input('请输入十八位身份证号码: ') if len(ID) == 18: print("你的身份证号码是 " ...
- Python——字符串、文件操作,英文词频统计预处理
一.字符串操作: 解析身份证号:生日.性别.出生地等. 凯撒密码编码与解码 网址观察与批量生成 2.凯撒密码编码与解码 凯撒加密法的替换方法是通过排列明文和密文字母表,密文字母表示通过将明文字母表向左 ...
- 组合数据类型,英文词频统计 python
练习: 总结列表,元组,字典,集合的联系与区别.列表,元组,字典,集合的遍历. 区别: 一.列表:列表给大家的印象是索引,有了索引就是有序,想要存储有序的项目,用列表是再好不过的选择了.在python ...
随机推荐
- 简单记录一下ruby 循环
今天整理一下ruby中的循环用法: 备注:“do~end”部分也可以写做{~} 1.break:直接跳出整个循环 i= 0 ["perl","python",& ...
- 20155224 《实验二 Java面向对象程序设计》实验报告
实验二 Java面向对象程序设计 实验内容 初步掌握单元测试和TDD 理解并掌握面向对象三要素:封装.继承.多态 初步掌握UML建模 熟悉S.O.L.I.D原则 了解设计模式 实验要求 没有Linux ...
- 20155306 实验一《Java开发环境的熟悉》实验报告
实验一 Java开发环境的熟悉(Linux + Eclipse) 实验内容 1.使用JDK编译.运行简单的Java程序: 2.使用Eclipse 编辑.编译.运行.调试Java程序. 实验要求 1. ...
- 虚拟机与Linux的初体验
很早的时候就知道虚拟机这个神奇东西的存在,但也仅仅是只闻其名,未见其身.后来在信息安全素质教育的这门课程上,为了做木马实验.暴力破解实验以及邮件窃取实验,这才比较直接的接触到了虚拟机.当我看着在另一个 ...
- 20155338 《Java程序设计》实验三(敏捷开发与XP实践)实验报告
20155338 <Java程序设计>实验三(敏捷开发与XP实践)实验报告 一.实验内容及步骤 (一)使用Code菜单 • 在IDEA中使用工具(Code->Reformate Co ...
- 20155339 2017-2018-1《信息安全系统设计》第四周课堂测试、Makefile以及myod
20155339 2017-2018-1<信息安全系统设计>第四周课堂测试.Makefile以及myod 测试1-vi 每个.c一个文件,每个.h一个文件,文件名中最好有自己的学号 用Vi ...
- 【Unity3d】WWW类发起web连接
初学unity3d,解决一个游戏与web服务器连接问题. 看了项目中原始代码,发现每次之前的程序员每次调用WWW类都需要写一遍StartCoroutine,然后各种重复代码. 于是写了一个简单的封装类 ...
- uvaoj 156Ananagrams(map和vector组合使用)
https://uva.onlinejudge.org/index.php?option=com_onlinejudge&Itemid=8&page=show_problem& ...
- kubeadm构建k8s之Prometheus-operated监控(0.18.1)
介绍: 大家好,k8s的搭建有许多方式,也有许多快速部署的,为了简化部署的复杂度,官方也提供了开源的kubeadm快速部署,最新1.10.x版本已经可以实现部署集群, 如果你对k8s的原理已经非常了解 ...
- Python操作摄像头
实践环境: 操作系统:Windows 7(X64) Python版本:python-2.7.13.msi 使用插件:pygame-1.9.1.win32-py2.7.msi 软件下载: python- ...