hbase(三)coprocessor
介绍
coprocessor这个单词看起来很神秘,直译为协处理器,其实可以理解成依赖于regionserver进程的辅助处理接口。
hbae在0.92版本之后提供了coprocessor接口。目前hbase支持两种coprocessor,endpoint和observer。hbase在未来版本可能考虑将coprocessor进程独立出来,单独起个服务。
endpoint coprocessor
Endpoint 协处理器类似传统数据库中的存储过程,客户端可以调用这些 Endpoint 协处理器执行一段 Server 端代码,并将 Server 端代码的结果返回给客户端进一步处理,最常见的用法就是进行聚集操作。如果没有协处理器,当用户需要找出一张表中的最大数据,即 max 聚合操作,就必须进行全表扫描,在客户端代码内遍历扫描结果,并执行求最大值的操作。这样的方法无法利用底层集群的并发能力,而将所有计算都集中到 Client 端统一执行,势必效率低下。利用 Coprocessor,用户可以将求最大值的代码部署到 HBase Server 端,HBase 将利用底层 cluster 的多个节点并发执行求最大值的操作。即在每个 Region 范围内执行求最大值的代码,将每个 Region 的最大值在 Region Server 端计算出,仅仅将该 max 值返回给客户端。在客户端进一步将多个 Region 的最大值进一步处理而找到其中的最大值。这样整体的执行效率就会提高很多。说白了,coprocessor就是hbase提供一些接口和规则,让你可以在regionserver服务中执行你自定义的代码。这个规则就是基于google的protobuf。
endpoint observer在多个regionserver上执行,执行结果返回给client,这个过程有点像mapreduce,map操作在regionserver端,reduce在client端。下图为endpoint执行流程。
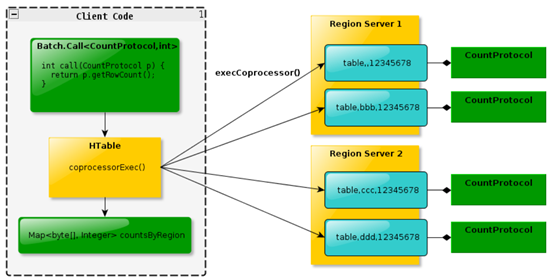
observer coprocessor
另外一种协处理器叫做 Observer Coprocessor,这种协处理器类似于传统数据库中的触发器,思路上类似AOP的思想,当发生某些事件的时候这类协处理器会被 Server 端调用。Observer Coprocessor 就是一些散布在 HBase Server 端代码中的 hook 钩子.
在Region层面,比如:put 操作之前有钩子函数 prePut,该函数在 put 操作执行前会被 Region Server 调用;在 put 操作之后则有 postPut 钩子函数。还有例如get,delete,scan等其他操作的钩子.
在regionserver层面,observer coprocessor还提供了WALObserver
在MasterObserver层面,提供了DDL操作的相关钩子,create,delete等
下图为observer coprocessor执行流程,注意最后的regionObserver是在服务端执行的,因此自定义的observer coprocessor代码打包后需要放在hbase服务端也就是regionserver的classpath下。

例子
参考hbaes源码中的src/example/coprocessor
引用
https://blogs.apache.org/hbase/entry/coprocessor_introduction
hbase(三)coprocessor的更多相关文章
- Hbase(三) hbase协处理器与二级索引
一.协处理器—Coprocessor 1. 起源Hbase 作为列族数据库最经常被人诟病的特性包括:无法轻易建立“二级索引”,难以执 行求和.计数.排序等操作.比如,在旧版本的(<0.92)Hb ...
- SHDP--Working with HBase(三)之HBase+Phoenix实现分页
先简单讲讲只用HBase来实现分页的思路: HBase利用scan来扫描表,通过startKey,stopKey来确定扫描范围,在需要进行分页时可以结合HBase提供的PagefFilter过滤扫描的 ...
- HBase(三): Azure HDInsigt HBase表数据导入本地HBase
目录: hdfs 命令操作本地 hbase Azure HDInsight HBase表数据导入本地 hbase hdfs命令操作本地hbase: 参见 HDP2.4安装(五):集群及组件安装 , ...
- 【Hbase三】Java,python操作Hbase
Java,python操作Hbase 操作Hbase python操作Hbase 安装Thrift之前所需准备 安装Thrift 产生针对Python的Hbase的API 启动Thrift服务 执行p ...
- hbase的coprocessor使用(转)
http://www.360doc.com/content/13/0320/09/4675893_272623864.shtml
- hbase实践之协处理器Coprocessor
HBase客户端查询存在的问题 Scan 用Get/Scan查询数据, Filter 用Filter查询特定数据 以上情况只适合几千行数据以及不是很多的列的"小数据". 当表扩展为 ...
- hbase 协处理器
一.服务端1.安装Protobuf2.RPC proto 定义文件:Examples.protooption java_package = "org.apache.hadoop.hbase. ...
- 大数据架构-使用HBase和Solr将存储与索引放在不同的机器上
大数据架构-使用HBase和Solr将存储与索引放在不同的机器上 摘要:HBase可以通过协处理器Coprocessor的方式向Solr发出请求,Solr对于接收到的数据可以做相关的同步:增.删.改索 ...
- HBase Endpoint
引言 假设HBase某张表有1000个Region,里面存储着100万行数据,现在需要统计满足某些条件的行数,普通的做法是使用Filter(过滤条件),通过HBase API将满足过滤条件的行数据 ...
- Hbase多列范围查找(效率)
Hbase索引表的结构 Hbase Rowkey 设计 Hbase Filter Hbase二级索引 Hbase索引表的结构 在HBase中,表格的Rowkey按照字典排序,Region按照RowKe ...
随机推荐
- 树链剖分-点的分治(dis[i]+dis[j]==k的点对数量)
poj2114 Boatherds Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 1195 Accepted: 387 ...
- c++Template 的辨析
1.在c++Template中很多地方都用到了typename与class这两个关键字,而且好像可以替换,是不是这两个关键字完全一样呢? 答:class用于定义类,在模板引入c++后,最初定义模板的方 ...
- thymeleaf 学习笔记-基础篇(中文教程)
(一)Thymeleaf 是个什么? 简单说, Thymeleaf 是一个跟 Velocity.FreeMarker 类似的模板引擎,它可以完全替代 JSP .相较与其他的模板引擎,它有如下 ...
- Composer 添加 Laravel-china 的国内源
不知道由于什么原因,原来的 Composer 的国内镜像 https://pkg.phpcomposer.com/ 不能正常使用,经常连不上. 找了半天,发现还有一个 laravel-china 的国 ...
- 170523、快速提升你 MySQL 数据库的段位
MySQL 数据库知识脉络,大致可以分为四大模块: ● MySQL 体系结构: ● MySQL 备份恢复: ● MySQL 高可用集群: ● MySQL 优化. 从四大模块中,抽离7个部分给大家做分析 ...
- 用Squid实现反向代理
Last-Modified: 告诉反向代理页面什么时间被修改 Expires: 告诉反向代理页面什么时间应该从缓冲区中删除 Cache-Control: 告诉反向代理页面是否应该被缓冲 Pragma: ...
- Code Forces 18D Seller Bob(简单DP)
D. Seller Bob time limit per test 2 seconds memory limit per test 128 megabytes input standard input ...
- codeforces#512 Div2
pre过了三题 终测又挂了一题 又掉分了 真的是 太菜了 A-In Search of an Easy Problem 水题 有一个1就是hard #include <bits/stdc++.h ...
- 朴素贝叶斯算法的python实现 -- 机器学习实战
import numpy as np import re #词表到向量的转换函数 def loadDataSet(): postingList = [['my', 'dog', 'has', 'fle ...
- stark - filter、pop、总结
一.filter 效果图 知识点 1.配置得显示Filter,不配置就不显示了 list_filter = ['title','publish', 'authors'] 2.前端显示 后端返回 字典 ...