Whitening
The goal of whitening is to make the input less redundant; more formally, our desiderata are that our learning algorithms sees a training input where (i) the features are less correlated with each other, and (ii) the features all have the same variance.
example
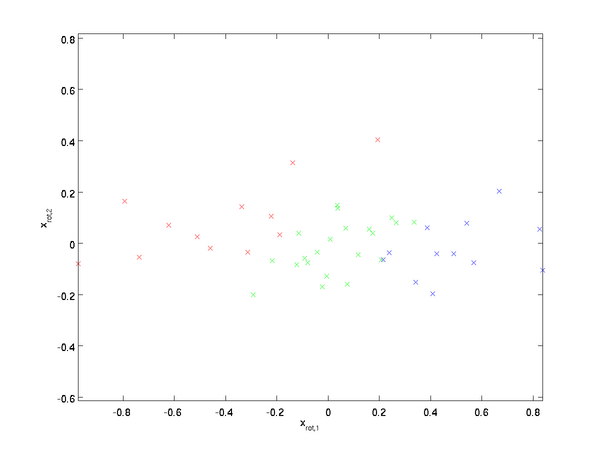
How can we make our input features uncorrelated with each other? We had already done this when computing
. Repeating our previous figure, our plot for
was:
The covariance matrix of this data is given by:
It is no accident that the diagonal values are
and
. Further, the off-diagonal entries are zero; thus,
and
are uncorrelated, satisfying one of our desiderata for whitened data (that the features be less correlated).
To make each of our input features have unit variance, we can simply rescale each feature
by
. Concretely, we define our whitened data
as follows:
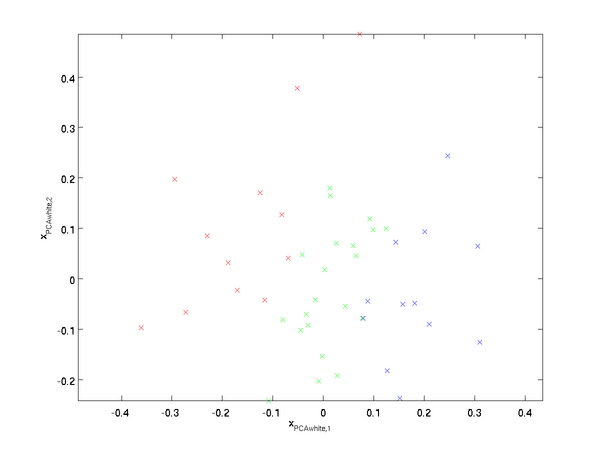
Plotting
, we get:
This data now has covariance equal to the identity matrix
. We say that
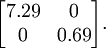
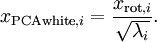
ZCA Whitening
Finally, it turns out that this way of getting the data to have covariance identity
is any orthogonal matrix, so that it satisfies
(less formally, if
will also have identity covariance. In ZCA whitening, we choose
. We define
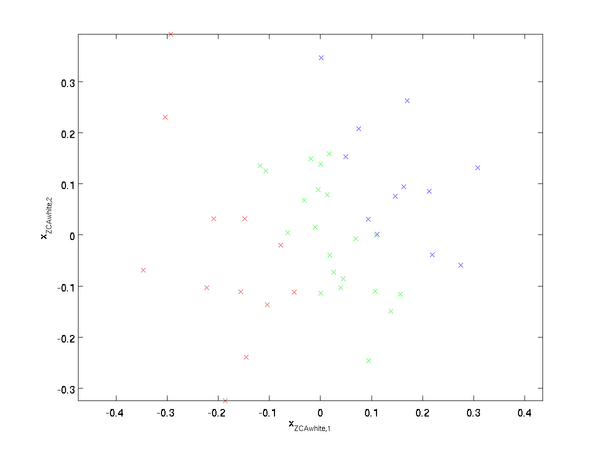
Plotting
, we get:
It can be shown that out of all possible choices for
.
When using ZCA whitening (unlike PCA whitening), we usually keep all
dimensions of the data, and do not try to reduce its dimension.
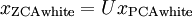
Regularizaton
When implementing PCA whitening or ZCA whitening in practice, sometimes some of the eigenvalues
will be numerically close to 0, and thus the scaling step where we divide by
would involve dividing by a value close to zero; this may cause the data to blow up (take on large values) or otherwise be numerically unstable. In practice, we therefore implement this scaling step using a small amount of regularization, and add a small constant
to the eigenvalues before taking their square root and inverse:
When
, a value of
might be typical.
For the case of images, adding
ZCA whitening is a form of pre-processing of the data that maps it from
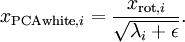
Whitening的更多相关文章
- (六)6.8 Neurons Networks implements of PCA ZCA and whitening
PCA 给定一组二维数据,每列十一组样本,共45个样本点 -6.7644914e-01 -6.3089308e-01 -4.8915202e-01 ... -4.4722050e-01 -7.4 ...
- (六)6.7 Neurons Networks whitening
PCA的过程结束后,还有一个与之相关的预处理步骤,白化(whitening) 对于输入数据之间有很强的相关性,所以用于训练数据是有很大冗余的,白化的作用就是降低输入数据的冗余,通过白化可以达到(1)降 ...
- UFLDL教程之(三)PCA and Whitening exercise
Exercise:PCA and Whitening 第0步:数据准备 UFLDL下载的文件中,包含数据集IMAGES_RAW,它是一个512*512*10的矩阵,也就是10幅512*512的图像 ( ...
- Deep Learning学习随记(二)Vectorized、PCA和Whitening
接着上次的记,前面看了稀疏自编码.按照讲义,接下来是Vectorized, 翻译成向量化?暂且这么认为吧. Vectorized: 这节是老师教我们编程技巧了,这个向量化的意思说白了就是利用已经被优化 ...
- Modeling Filters and Whitening Filters
Colored and White Process White Process White Process,又称为White Noise(白噪声),其中white来源于白光,寓意着PSD的平坦分布,w ...
- 白化(Whitening): PCA 与 ZCA (转)
转自:findbill 本文讨论白化(Whitening),以及白化与 PCA(Principal Component Analysis) 和 ZCA(Zero-phase Component Ana ...
- CS229 6.8 Neurons Networks implements of PCA ZCA and whitening
PCA 给定一组二维数据,每列十一组样本,共45个样本点 -6.7644914e-01 -6.3089308e-01 -4.8915202e-01 ... -4.4722050e-01 -7.4 ...
- CS229 6.7 Neurons Networks whitening
PCA的过程结束后,还有一个与之相关的预处理步骤,白化(whitening) 对于输入数据之间有很强的相关性,所以用于训练数据是有很大冗余的,白化的作用就是降低输入数据的冗余,通过白化可以达到(1)降 ...
- PCA和Whitening
PCA: PCA的具有2个功能,一是维数约简(可以加快算法的训练速度,减小内存消耗等),一是数据的可视化. PCA并不是线性回归,因为线性回归是保证得到的函数是y值方面误差最小,而PCA是保证得到的函 ...
- 【DeepLearning】Exercise:PCA and Whitening
Exercise:PCA and Whitening 习题链接:Exercise:PCA and Whitening pca_gen.m %%============================= ...
随机推荐
- Spring项目的配置文件们(web.xml context servlet springmvc)
我们的spring项目目前用到的配置文件包括1--web.xml文件,这是java的web项目的配置文件.我理解它是servlet的配置文件,也就是说,与spring无关.即使你开发的是一个纯粹jsp ...
- pc端如何引用日期插件
页面的html部分 <li> <span>出生日期</span> <input type="text" placeholder=" ...
- Redis数据持久化的两种方式RDB和AOF
由于Redis的数据都存放在内存中,如果没有配置持久化,redis重启后数据就全丢失了,于是需要开启redis的持久化功能,将数据保存到磁 盘上,当redis重启后,可以从磁盘中恢复数据.redis提 ...
- java 基于 bootstrap_datagrid 分页
1.首先引入datagrid js ,css $("#datagrid").bootstrap_datagrid({ url : "<%=path%>/us ...
- APUE 学习笔记 —— 文件I/O
本章节主要讲了 Linux 系统下的关于文件I/O操作的几个函数:open.read.write.lseek.close 的使用和需要注意的一些细节.接着,又介绍了多进程见如何共享文件.下面开始知识点 ...
- [CQOI2013]新Nim游戏(线性基)
P4301 [CQOI2013]新Nim游戏 题目描述 传统的Nim游戏是这样的:有一些火柴堆,每堆都有若干根火柴(不同堆的火柴数量可以不同).两个游戏者轮流操作,每次可以选一个火柴堆拿走若干根火柴. ...
- Python学习笔记(4)--数据结构之元组tuple
元组(tuple) 定义:tuple和list十分相似,但是tuple是不可变的,即不能修改tuple 初始化:(), ('a', ) , ('a', 'b') //当只有一个元素时,需加上逗号, ...
- vue22 路由
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- KDD 2011 最佳工业论文中机器学习的实践方法-翻译
作者:黄永刚 Practical machine learning tricks from the KDD 2011 best industry paper 原文链接:http://blog.davi ...
- Android setBackgroundResource和setBackgroundDrawable和用法
两个方法的效果是一样,只是区别于效率! playBtn.setBackgroundResource(R.drawable.pause_selecor); 从上面可以看出来是从资源文件中获取drawab ...