CS229 6.7 Neurons Networks whitening
PCA的过程结束后,还有一个与之相关的预处理步骤,白化(whitening)
对于输入数据之间有很强的相关性,所以用于训练数据是有很大冗余的,白化的作用就是降低输入数据的冗余,通过白化可以达到(1)降低特征之间的相关性(2)所有特征同方差,白化是需要与平滑与PCA结合的,下边来看如何结合。
对于训练数据{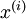 },找到其所有特征组成的新基U,计算在新基的坐标
},找到其所有特征组成的新基U,计算在新基的坐标 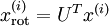 ,这里
,这里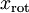 就会消除数据的相关性:
就会消除数据的相关性:
这个数据的协方差矩阵如下:
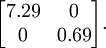
协方差矩阵对角元素的值为 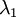 和
和 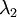 ,且非对角线元素取值为0,课件不同纬度的特征之间是不相关的,对应的
,且非对角线元素取值为0,课件不同纬度的特征之间是不相关的,对应的 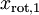 和
和 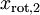 是不相关的,这便满足白化的第一个要求,降低相关性,下面就要使特征之间同方差(注意是变化后的特征同方差)中每个特征 i 的方差为
是不相关的,这便满足白化的第一个要求,降低相关性,下面就要使特征之间同方差(注意是变化后的特征同方差)中每个特征 i 的方差为 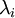 我们可以直接使用
我们可以直接使用 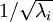 作为缩放因子来缩放每个特征
作为缩放因子来缩放每个特征 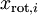 。具体地,我们定义白化后的数据
。具体地,我们定义白化后的数据 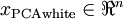 如下:
如下:
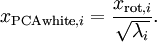
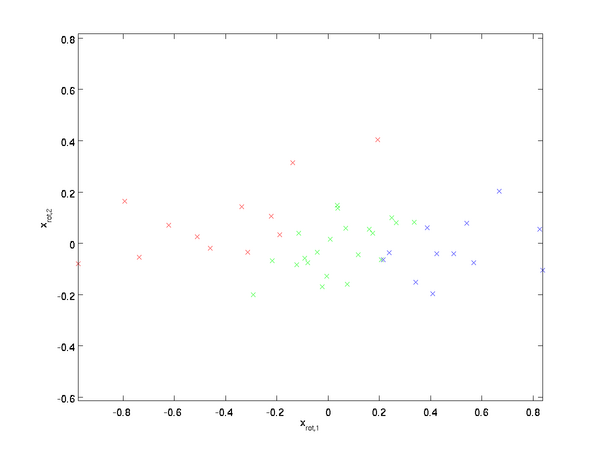
绘制出 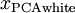 ,可以得到:
,可以得到:
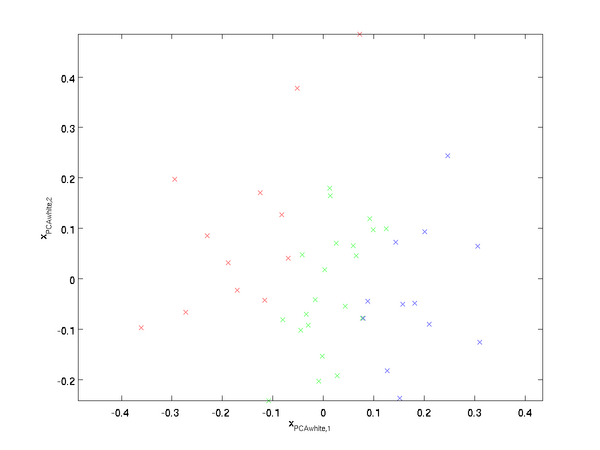
这些数据现在的协方差矩阵为单位矩阵 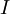 。 是数据经过PCA白化后的版本: 中不同的特征之间不相关并且具有单位方差。
。 是数据经过PCA白化后的版本: 中不同的特征之间不相关并且具有单位方差。
白化与降维相结合。 如果你想要得到经过白化后的数据,并且比初始输入维数更低,可以仅保留 中前  个成分。当我们把PCA白化和正则化结合起来时(在稍后讨论), 中最后的少量成分将总是接近于0,因而舍弃这些成分不会带来很大的问题。
个成分。当我们把PCA白化和正则化结合起来时(在稍后讨论), 中最后的少量成分将总是接近于0,因而舍弃这些成分不会带来很大的问题。
最后要说明的是,使数据的协方差矩阵变为单位矩阵 的方式并不唯一。具体地,如果 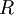 是任意正交矩阵,即满足
是任意正交矩阵,即满足 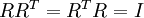 (说它正交不太严格, 可以是旋转或反射矩阵), 那么
(说它正交不太严格, 可以是旋转或反射矩阵), 那么 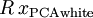 仍然具有单位协方差。在ZCA白化中,令
仍然具有单位协方差。在ZCA白化中,令 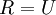 。定义ZCA白化的结果为:
。定义ZCA白化的结果为:
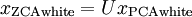
绘制 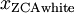 ,得到:
,得到:
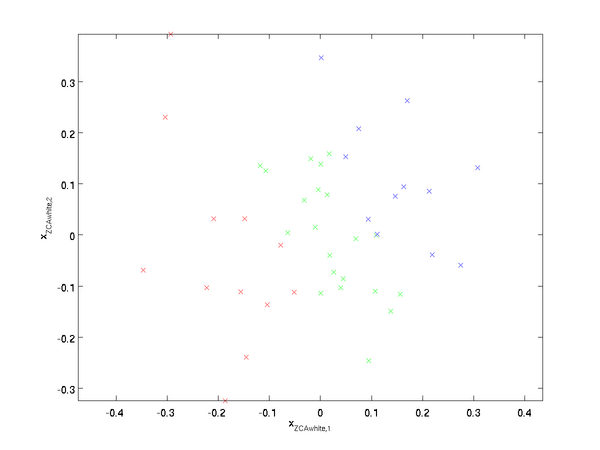
可以证明,对所有可能的 ,这种旋转使得 尽可能地接近原始输入数据  。
。
当使用 ZCA白化时(不同于 PCA白化),我们通常保留数据的全部 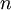 个维度,不尝试去降低它的维数。
个维度,不尝试去降低它的维数。
实践中需要实现PCA白化或ZCA白化时,有时一些特征值 在数值上接近于0,这样在缩放步骤时我们除以 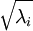 将导致除以一个接近0的值;这可能使数据上溢 (赋为大数值)或造成数值不稳定。因而在实践中,我们使用少量的正则化实现这个缩放过程,即在取平方根和倒数之前给特征值加上一个很小的常数
将导致除以一个接近0的值;这可能使数据上溢 (赋为大数值)或造成数值不稳定。因而在实践中,我们使用少量的正则化实现这个缩放过程,即在取平方根和倒数之前给特征值加上一个很小的常数 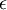 :
:
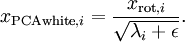
当 在区间 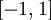 上时, 一般取值为
上时, 一般取值为 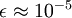 。
。
对图像来说, 这里加上 ,对输入图像也有一些平滑(或低通滤波)的作用。这样处理还能消除在图像的像素信息获取过程中产生的噪声,改善学习到的特征。
CS229 6.7 Neurons Networks whitening的更多相关文章
- CS229 6.10 Neurons Networks implements of softmax regression
softmax可以看做只有输入和输出的Neurons Networks,如下图: 其参数数量为k*(n+1) ,但在本实现中没有加入截距项,所以参数为k*n的矩阵. 对损失函数J(θ)的形式有: 算法 ...
- CS229 6.1 Neurons Networks Representation
面对复杂的非线性可分的样本是,使用浅层分类器如Logistic等需要对样本进行复杂的映射,使得样本在映射后的空间是线性可分的,但在原始空间,分类边界可能是复杂的曲线.比如下图的样本只是在2维情形下的示 ...
- CS229 6.8 Neurons Networks implements of PCA ZCA and whitening
PCA 给定一组二维数据,每列十一组样本,共45个样本点 -6.7644914e-01 -6.3089308e-01 -4.8915202e-01 ... -4.4722050e-01 -7.4 ...
- (六)6.7 Neurons Networks whitening
PCA的过程结束后,还有一个与之相关的预处理步骤,白化(whitening) 对于输入数据之间有很强的相关性,所以用于训练数据是有很大冗余的,白化的作用就是降低输入数据的冗余,通过白化可以达到(1)降 ...
- CS229 6.16 Neurons Networks linear decoders and its implements
Sparse AutoEncoder是一个三层结构的网络,分别为输入输出与隐层,前边自编码器的描述可知,神经网络中的神经元都采用相同的激励函数,Linear Decoders 修改了自编码器的定义,对 ...
- CS229 6.15 Neurons Networks Deep Belief Networks
Hintion老爷子在06年的science上的论文里阐述了 RBMs 可以堆叠起来并且通过逐层贪婪的方式来训练,这种网络被称作Deep Belife Networks(DBN),DBN是一种可以学习 ...
- CS229 6.2 Neurons Networks Backpropagation Algorithm
今天得主题是BP算法.大规模的神经网络可以使用batch gradient descent算法求解,也可以使用 stochastic gradient descent 算法,求解的关键问题在于求得每层 ...
- CS229 6.17 Neurons Networks convolutional neural network(cnn)
之前所讲的图像处理都是小 patchs ,比如28*28或者36*36之类,考虑如下情形,对于一副1000*1000的图像,即106,当隐层也有106节点时,那么W(1)的数量将达到1012级别,为了 ...
- CS229 6.14 Neurons Networks Restricted Boltzmann Machines
1.RBM简介 受限玻尔兹曼机(Restricted Boltzmann Machines,RBM)最早由hinton提出,是一种无监督学习方法,即对于给定数据,找到最大程度拟合这组数据的参数.RBM ...
随机推荐
- removing-guest-session-at-login-in-ubuntu-14-04
http://askubuntu.com/questions/451526/removing-guest-session-at-login-in-ubuntu-14-04
- kafka 的 docker 镜像使用
Kafka 还没有提供官方的镜像(2019.01.29),能找到的都是一些社区维护的镜像包. 这里使用这个镜像:https://hub.docker.com/r/spotify/kafka
- redis 的 docker 镜像使用
redis 镜像使用: 创建容器(暴露端口:6379,使用 Redis 可视化界面工具(如:Fastoredis)连接 redis 时连接该端口): docker run -it -p 6379:63 ...
- Linux中硬盘物理扇区与文件系统文件对应关系(转)
1 概述 系统读写文件过程中,如下面内核打印信息,报告读写某个扇区错误.那么我们如何能够通过sector找到读写哪个文件错误? kernel: end_request: I ...
- Eclipse安装插件的“最好方法”:dropins文件夹的妙用
在Eclipse3.4以前安装插件非常繁琐. 在Eclipse3.5以后插件安装的功能做了改进.而且非常方便易用. 我们只需要把需要的插件复制(拖放)到eclipse\dropins,然后插件就安装成 ...
- IText简介及示例
一.iText简介 iText是著名的开放源码的站点sourceforge一个项目,是用于生成PDF文档的一个java类库.通过iText不仅可以生成PDF或rtf的文档,而且可以将XML.Html文 ...
- 数据科学VS机器学习
数据科学是一个范围很广的学科.机器学习和统计学都是数据科学的一部分.机器学习中的学习一词表示算法依赖于一些数据(被用作训练集)来调整模型或算法的参数.这包含了许多的技术,比如回归.朴素贝叶斯或监督聚类 ...
- python 中变量引用问题
普通变量,如a=10,str="fdaf",它们在函数内的值是不会被带到函数外的,除非在函数内加上global,而引用是惰性原则,从最近的同名父级同名变量引用值 其它变量如列表,字 ...
- java cp命令
java -cp .;c:\dir1\lib.jar Test -cp 和 -classpath 一样,是指定类运行所依赖其他类的路径,通常是类库,jar包之类,需要全路径到jar包,windo ...
- ThreadPoolExecutor简单学习
Executors和ThreadPoolExecutor两者的区别和联系 jdk中文文档 https://blog.fondme.cn/apidoc/jdk-1.8-google/ 还可以的两个博客 ...