elasticsearch 分布式阅读笔记(二)
说明
扩展分为
纵向扩展:购买更好的服务器
横向扩展:增加服务器(elasticsearch更适合横向扩展)
elasticsearch可以用于构建高可用和可扩展的系统,elasticsearch天生就是分布式的 它知道如何管理各个节点 我们程序并不需要关心
elasticsearch默认就是一个集群,比如前面的例子的集群看起来如下图

主节点只用于临时的管理节点的 删除索引 移除或新增节点 主节点不参与文档的变更和搜索,那么表示主节点并不会出现性能瓶颈, 请求都平均分配给了其他节点,各个子节点都知道数据保存在哪个节点上。子节点负责将我们的请求转发到相应数据的节点 获得数据 并返回给客户端
集群健康
get请求:http://127.0.0.1:9200/_cluster/health
结果
{
"cluster_name": "elasticsearch",//集群名称
"status": "yellow",//集群状态(yellow,grren,red)
"timed_out": false,//是否超时
"number_of_nodes": 1,//总节点数
"number_of_data_nodes": 1,//总节点数
"active_primary_shards": 15,//可用的主分片数量
"active_shards": 15,//可用的总分片数量
"relocating_shards": 0,//正在迁移的分片数量
"initializing_shards": 0,//正在初始化的分片数量
"unassigned_shards": 15,//未分配的分片数量
"delayed_unassigned_shards": 0,//延迟未分配的分片数量
"number_of_pending_tasks": 0,//等待执行任务数量0
"number_of_in_flight_fetch": 0,
"task_max_waiting_in_queue_millis": 0,//任务在队列中等待的较大时间(毫秒)
"active_shards_percent_as_number": 50//可用的总分片数量所占百分比
}
status 的值为:yellow,grren,red
yellow:所有主要分片可用,但是不是所有复制分片可以使用
red:不是所有主要分片都可用
grren:所有主要分片和复制分片都可用
添加索引
索引里面存在一个或者多个shard(分片),分片保存了 索引中数据的一部分。我们检索数据都是在分片上,分片又存在集群中的各个节点上,当集群节点扩展或缩小会自动迁移分片
分片可以是主分片和复制分片:
主分片可以理解为索引中的一个文档,主分片的数量决定了索引最多能存储多少条数据,
复制分片可以理解为主分片的数据备份,防止硬件故障导致的数据丢失,同时可以提供请求
当索引建立后 主分片的数量就固定了 但是可以调整复制分片数量
例子
添加一个3个主分片一个复制分片的的blogs索引
先把我们之前存在的索引清空
查询存在的所有索引
get 请求:http://127.0.0.1:9200/_cat/indices?v
结果
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open opcmdevpretty BuAOTDdqSIOGsemOQD9TuQ 5 1 0 0 1.2kb 1.2kb
yellow open blogs2 1k8UpYTPTk2JnTrclogVUA 3 1 0 0 783b 783b
yellow open opcmdev FrXbou2aR061erz6913_BQ 5 1 3 0 18.7kb 18.7kb
yellow open blogs4 BWHZTGSSQbWPpUGqPVdA1w 3 1 0 0 783b 783b
yellow open opcm 1dqGOUuPSIeuyGMEyL0Y-w 5 1 11 0 45.4kb 45.4kb
yellow open blogs 7GTeHqQrTjWJAyiBKy-2DA 3 1 0 0 783b 783b
删除所有 delete请求:http://127.0.0.1:9200/_all
我们再查看集群健康
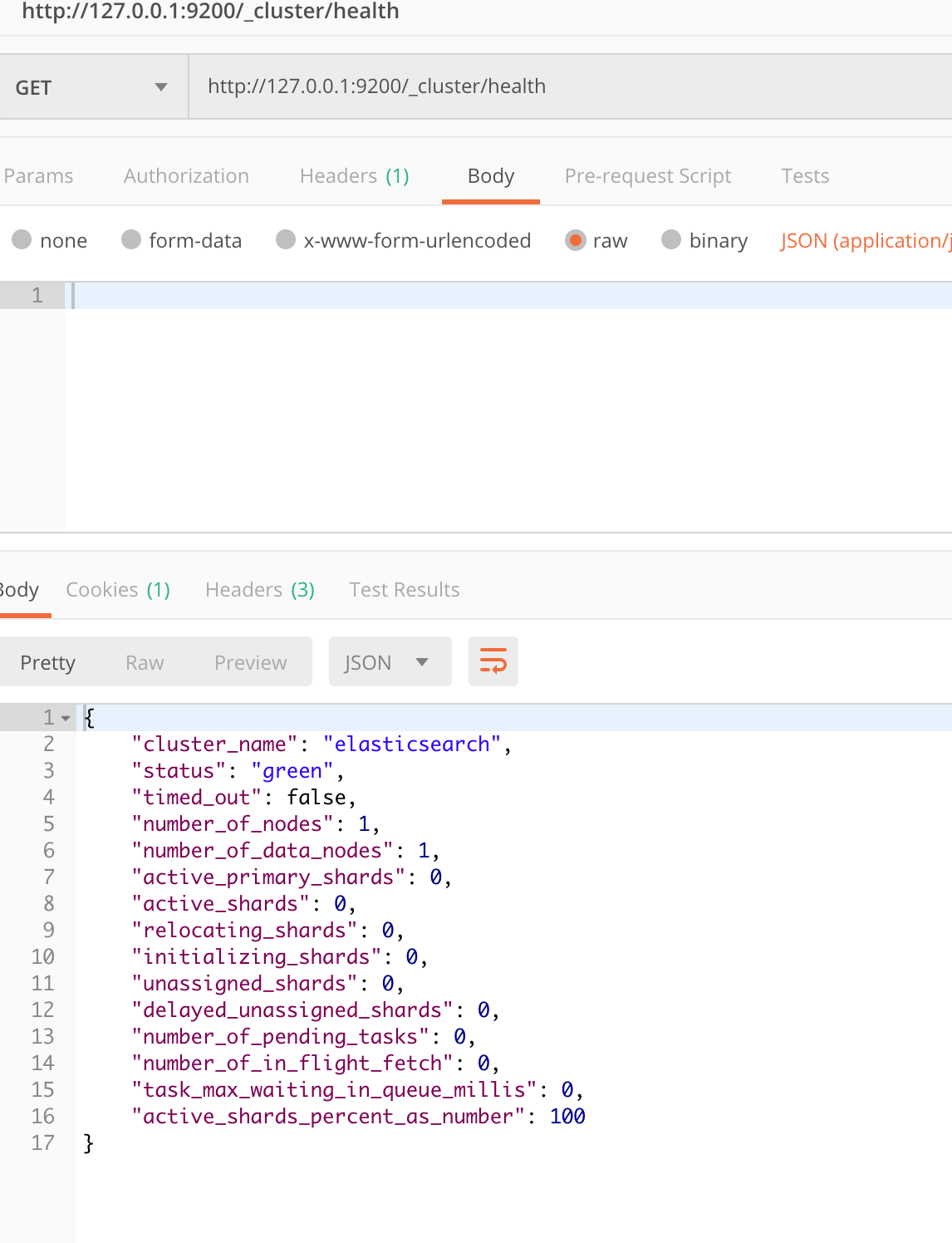
可以看到我们的分片数量都是0
现在我们为blogs索引添加一个 3个主分片1个复制分片
put请求:http://127.0.0.1:9200/blogs
参数
{
"settings":{
"number_of_shards":3,
"number_of_replicas":1
}
}
再查看集群健康
{
"cluster_name": "elasticsearch",
"status": "yellow",
"timed_out": false,
"number_of_nodes": 1,
"number_of_data_nodes": 1,
"active_primary_shards": 3,
"active_shards": 3,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 3,
"delayed_unassigned_shards": 0,
"number_of_pending_tasks": 0,
"number_of_in_flight_fetch": 0,
"task_max_waiting_in_queue_millis": 0,
"active_shards_percent_as_number": 50
}
上面我们提到yellow是表示所有主分片都可用 但是并不是所有复制分片都可用 unassigned_shards其实就是主分片对应的几个复制分片。因为我们单节点为主分片备份数据是没有必要的,这个节点异常 备份数据也会丢失。所以是3个复制分片是unassined
先不研究了 环境部署有其他人弄。先学习各种特性
分片原理
当索引一条shard=hash(routing)%number_of_parimary_shard 会通过_Id(默认) 的hash%主分片的数量 得出的余数 得出的数一定在0~主分片数量-1之间 所以有分片的索引就能路由到对应的分片
主分片和复制分片怎么交互的
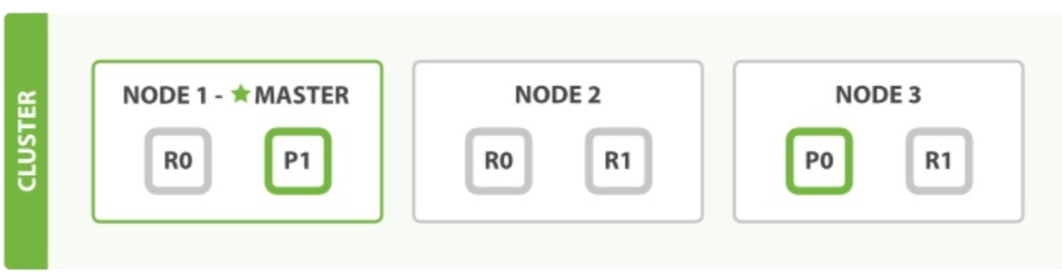
上图3个集群节点有2个主分片p*他们各有2个复制分片R*
上图任意一个节点都能接收请求,都知道文档的位置。如果文档不在当前节点当转发到文档存在节点。
所以集群情况下 我们最好根据算法负载均衡发送请求到节点
elasticsearch 分布式阅读笔记(二)的更多相关文章
- 《Java编程思想》阅读笔记二
Java编程思想 这是一个通过对<Java编程思想>(Think in java)进行阅读同时对java内容查漏补缺的系列.一些基础的知识不会被罗列出来,这里只会列出一些程序员经常会忽略或 ...
- Java Jdk1.8 HashMap源代码阅读笔记二
三.源代码阅读 3.元素包括containsKey(Object key) /** * Returns <tt>true</tt> if this map contains a ...
- Detectron2源码阅读笔记-(二)Registry&build_*方法
Trainer解析 我们继续Detectron2代码阅读笔记-(一)中的内容. 上图画出了detectron2文件夹中的三个子文件夹(tools,config,engine)之间的关系.那么剩下的 ...
- werkzeug源码阅读笔记(二) 下
wsgi.py----第二部分 pop_path_info()函数 先测试一下这个函数的作用: >>> from werkzeug.wsgi import pop_path_info ...
- 论文阅读笔记二十七:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks(CVPR 2016)
论文源址:https://arxiv.org/abs/1506.01497 tensorflow代码:https://github.com/endernewton/tf-faster-rcnn 室友对 ...
- 论文阅读笔记二十五:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition(SPPNet CVPR2014)
论文源址:https://arxiv.org/abs/1406.4729 tensorflow相关代码:https://github.com/peace195/sppnet 摘要 深度卷积网络需要输入 ...
- 论文阅读笔记二十四:Rich feature hierarchies for accurate object detection and semantic segmentation Tech report(R-CNN CVPR2014)
论文源址:http://www.cs.berkeley.edu/~rbg/#girshick2014rcnn 摘要 在PASCAL VOC数据集上,最好的方法的思路是将低级信息与较高层次的上下文信息进 ...
- <<梦断代码>>阅读笔记二
这是第二篇读书笔记,这本书我已经读了有一大半了,感觉书中所描述的人都是疯子,一群有创造力,却又耐得住寂寞的疯子. 我从书中发现几点我比较感兴趣的内容. 第一个,乐高之梦.将程序用乐高积木一样拼接起来. ...
- <<浪潮之巅>>阅读笔记二
好的文章总是慢慢吸引着你去阅读,这本书的作者是吴军博士,让我很钦佩的是他还是一个很著名的程序员.其实我感觉理科生在写作方面的能力是很欠缺的,我们经常做到了有观点,但是做不到和别人表达清楚你的观点想法, ...
随机推荐
- 创造HTTPS的是个神
HTTP 是一个明文传输的协议,很多网络监听工具都可以轻易窃取网络中传输的用户信息,如密码,信用卡, 直到后来发明HTTPS, 世界一下子安静了 Why HTTPS? HTTPS可以保证用户提交的信息 ...
- 使用匿名类型做为ComboBox的DataSource
使用匿名类型做为ComboBox的DataSource ArrayList list = new ArrayList(); list.Add(new { id = " ...
- C# WinForm小程序(技术改变世界-cnblog)
WinForm小程序(技术改变世界-cnblog) 需求: 1.点击按钮 更新 当前时间 2.输入 身份证,必须身份证 排序(类似银行卡那样的空格),自动生成空格排序 3.实现 必须按 第一个按 ...
- suse的安装命令zypper,类似apt
例子:添加11.3的官方软件和升级源zypper ar http://download.opensuse.org/distribution/11.3/repo/oss/ mainzypper ar h ...
- P2532 [AHOI2012]树屋阶梯 卡特兰数
这个题是一个卡特兰数的裸题,为什么呢?因为可以通过划分来导出递推式从而判断是卡特兰数,然后直接上公式就行了.卡特兰数的公式见链接. https://www.luogu.org/problemnew/s ...
- HTML 打印 换页
打印 HTML 无法强制换页其实是一件很令人困扰的事,要达到这个功能其实可以透过 CSS 的 Pagebreak 来处理. 强制分页有大概只有二种用的到: { page-break-after: al ...
- Electron结合React开发环境遇到的问题
链接 将create-react-app与electron集成在了一个项目中.但是在React中无法使用electron 当在React中使用require('electron')时就会报TypeEr ...
- Inception搭建
Inception安装Inception是集审核.执行.回滚于一体的一个自动化运维系统,它是根据MySQL代码修改过来的,用它可以很明确的,详细的,准确的审核MySQL的SQL语句,它的工作模式和My ...
- Swift - AnyClass,元类型和 .self
在Swift中能够表示 “任意” 这个概念的除了 Any 和 AnyObject 以外,还有一个AnyClass.我们能够使用AnyClass协议作为任意类型实例的具体类型.AnyClass在Swif ...
- 团体程序设计天梯赛-练习集-L1-034. 点赞
L1-034. 点赞 时间限制 200 ms 内存限制 65536 kB 代码长度限制 8000 B 判题程序 Standard 作者 陈越 微博上有个“点赞”功能,你可以为你喜欢的博文点个赞表示支持 ...