并不对劲的字符串专题(二):kmp
据说这些并不对劲的内容是《信息学奥赛一本通提高篇》的配套练习。
先感叹一句《信息学奥赛一本通提高篇》上对kmp的解释和matrix67的博客相似度99%(还抄错了),莫非matrix67藏在编者之中?
但这不重要,因为并不对劲的人不会对kmp作出任何解释。
课后练习:
1.bzoj1355->
可以将题目中给出的字符串看成形如这样的串:

那么,对于其中的某一位:

它到当前前缀的第二个循环节的开始组成的子串和前缀相等:
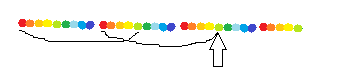
所以,对于当前位置x,fail[x]就是它到当前前缀的第二个循环节的开始组成的子串的长度,x-fail[x]就相当于字符串的开始到当前前缀的第二个循环节的开始的长度,也就是一个循环节的长度:
但是,随着x增大,x-fail[x]不降,所以对于长度为n的串,答案就是n-fail[n]。

代码就是求fail指针就行了。
#include<bits/stdc++.h>
using namespace std;
#define maxn 1000010
int fa[maxn],n,ans;
char s[maxn];
int main()
{
scanf("%d%s",&n,s+1);
fa[0]=-1,fa[1]=0;ans=1;
for(int i=2;i<=n;i++)
{
int u=i-1;
while(u&&s[fa[u]+1]!=s[i])u=fa[u];
if(u)fa[i]=fa[u]+1;
else fa[i]=0;
}
printf("%d",n-fa[n]);
return 0;
}
2.bzoj1511->
并不能读懂题面,求大佬帮助。
3.bzoj3620->
题目中要找形如A+B+A的子串,所以可以枚举左端点,再算出每个右端点是否可行。
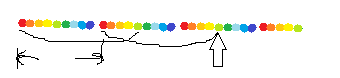
首先,固定左端点后,求出fail指针。对于fail[x]*2<x的,肯定是没问题了(如图):

对于fail[x]*2>=x的呢?会发现,1到fail[x]的子串和x-fail[x]+1到x的子串一样,1到fail[fail[x]]的子串和fail[x]-fail[fail[x]]+1到fail[x]的子串一样,所以1到fail[fail[x]]的子串和x-fail[fail[x]]+1到x的子串一样。那么就可以顺着fail指针往上找,直到长度*2<x且长度>=k。
不断顺着fail指针往上找的过程听上去很暴力,这题本来就很暴力了,就要避免这种暴力的。发现对于点x求出合法解为y后,对于x在fail树所有子孙,就都是合法的了。那么可以标记x,这样计算x在fail树所有子孙时,走到x就可以停了。
这个优化听上去很扯,它还是O(n2)的,但是15000的数据还是过了,是因为kmp常数小的缘故?
#include<algorithm>
#include<cmath>
#include<cstdio>
#include<cstdlib>
#include<cstring>
#include<iomanip>
#include<iostream>
#include<map>
#include<stack>
#include<set>
#include<queue>
#define maxn 15010
using namespace std;
int read()
{
int x=0,f=1;
char ch=getchar();
while(!isdigit(ch)&&ch!='-')ch=getchar();
if(ch=='-')f=-1,ch=getchar();
while(isdigit(ch))x=(x<<3)+(x<<1)+ch-'0',ch=getchar();
return x*f;
}
void write(int x)
{
int f=0;char ch[20];
if(x==0){putchar('0'),putchar('\n');return;}
if(x<0){putchar('-'),x=-x;}
while(x)ch[++f]=x%10+'0',x/=10;
while(f)putchar(ch[f--]);
putchar('\n');
}
int ans,k,fa[maxn],n,lst[maxn];
char s[maxn];
void rebuild()
{
for(int i=1;i<n;i++)s[i]=s[i+1];
n--;
}
int main()
{
scanf("%s%d",s+1,&k);
n=strlen(s+1);
for(;n>=(k<<1|1);)
{
fa[1]=0,fa[0]=-1;lst[0]=lst[1]=-1;
for(int i=2;i<=n;i++)
{
lst[i]=-1;
int u=i-1;
while(s[fa[u]+1]!=s[i]&&u)u=fa[u];
if(!u)fa[i]=0;
else fa[i]=fa[u]+1;
}
for(int i=1;i<=n;i++)
{
int u=fa[i];
while((u<<1|1)>i&&fa[u]>=k){if(lst[u]!=-1)u=lst[u];else u=fa[u];}
//cout<<u<<endl;
if((u<<1|1)<=i&&u>=k) lst[i]=u,ans++;
//cout<<lst[i]<<" ";
}
//cout<<"+++"<<endl;
rebuild();
}
write(ans);
return 0;
}
/*
aaaaa
1
*/
4.bzoj3942->
先想一个比较暴力的:让一个指针k从头往后扫S,每次判断长度为|T|的后缀是否等于T。
这个的时间复杂度是O(|S|*|T|),发现判断长度为|T|的后缀是否等于T有点像kmp。
那么就可以再维护一个指针p,表示T中走到的位置。对于S的每一位,开一个数组记录k走到这里时p走到的位置。
每当p走到T的结尾时,k退回|T|前的位置,p变成之前记录的k走到该点时p的位置。
#include<algorithm>
#include<cmath>
#include<cstdio>
#include<cstdlib>
#include<cstring>
#include<iomanip>
#include<iostream>
#include<map>
#include<set>
#include<stack>
#include<queue>
#define maxn 1000010
using namespace std;
char s[maxn],t[maxn];
int fa[maxn],mat[maxn],top,ns,nt,ans[maxn];
void go(int & u,char c)
{
while(t[u+1]!=c){u=fa[u];if(!u)break;}
if(t[u+1]==c)u++;
else u=0;
}
int main()
{
//freopen("censor.in","r",stdin);
//freopen("censor.out","w",stdout);
scanf("%s%s",s+1,t+1);
ns=strlen(s+1),nt=strlen(t+1);
fa[1]=0;
for(int i=2;i<=nt;i++)
{
int u=i-1;
while(t[fa[u]+1]!=t[i]&&u)u=fa[u];
if(!u)fa[i]=0;
else fa[i]=fa[u]+1;
}
int u=0;
for(int i=1;i<=ns;i++)
{
go(u,s[i]);
mat[i]=u;
ans[++top]=i;
if(u==nt)
{
top-=nt;
u=mat[ans[top]];
}
}
//for(int i=1;i<=ns;i++)cout<<mat[i]<<" ";cout<<endl;
for(int i=1;i<=top;i++)putchar(s[ans[i]]);
return 0;
}
并不对劲的字符串专题(二):kmp的更多相关文章
- 字符串专题之KMP算法
写点自己对KMP的理解,我们有两个字符串A和B,求A中B出现了多少次. 这种问题就可以用KMP来求解. 朴素的匹配最坏情况是O(n^2)的.KMP是个高效的算法,效率是O(n)的. KMP算法的思想是 ...
- 字符串专题:KMP POJ 3561
http://poj.org/problem?id=3461 KMP这里讲的不错next的求法值得借鉴 http://blog.sina.com.cn/s/blog_70bab9230101g0qv. ...
- 并不对劲的字符串专题(三):Trie树
据说这些并不对劲的内容是<信息学奥赛一本通提高篇>的配套练习. 并不会讲Trie树. 1.poj1056-> 模板题. 2.bzoj1212-> 设dp[i]表示T长度为i的前 ...
- LeetCode 字符串专题(一)
目录 LeetCode 字符串专题 <c++> \([5]\) Longest Palindromic Substring \([28]\) Implement strStr() [\(4 ...
- 「kuangbin带你飞」专题二十二 区间DP
layout: post title: 「kuangbin带你飞」专题二十二 区间DP author: "luowentaoaa" catalog: true tags: - ku ...
- NOIP2018提高组金牌训练营——字符串专题
NOIP2018提高组金牌训练营——字符串专题 1154 回文串划分 有一个字符串S,求S最少可以被划分为多少个回文串. 例如:abbaabaa,有多种划分方式. a|bb|aabaa - 3 个 ...
- SQL语句复习【专题二】
SQL语句复习[专题二] 单行函数(日期.数学.字符串.通用函数.转换函数)多行函数.分组函数.多行数据计算一个结果.一共5个.sum(),avg(),max(),min(),count()分组函数 ...
- 【算法系列学习三】[kuangbin带你飞]专题二 搜索进阶 之 A-Eight 反向bfs打表和康拓展开
[kuangbin带你飞]专题二 搜索进阶 之 A-Eight 这是一道经典的八数码问题.首先,简单介绍一下八数码问题: 八数码问题也称为九宫问题.在3×3的棋盘,摆有八个棋子,每个棋子上标有1至8的 ...
- 数据结构学习之字符串匹配算法(BF||KMP)
数据结构学习之字符串匹配算法(BF||KMP) 0x1 实验目的 通过实验深入了解字符串常用的匹配算法(BF暴力匹配.KMP.优化KMP算法)思想. 0x2 实验要求 编写出BF暴力匹配.KM ...
随机推荐
- XTU 二分图和网络流 练习题 C. 方格取数(1)
C. 方格取数(1) Time Limit: 5000ms Memory Limit: 32768KB 64-bit integer IO format: %I64d Java class ...
- github新建本地仓库,再同步远程仓库基本用法
github新建本地仓库,再同步远程仓库基本用法 1 mkdir gitRepo 2 cd gitRepo 3 git init #初始化本地仓库 4 git add xxx #添加要push到远 ...
- android AlertDialog常见使用
android AlertDialog常见使用 简单提示框: AlertDialog.Builder alertDialog = new AlertDialog.Builder(this); aler ...
- google play上获取apk文件
先说一种测试不通过的方法(chrome浏览器添加Direct APK downloader拓展程序),浪费了我很多的时间,结果发现根本用不了,记录一下过程给大家参考. 使用chrome浏览器,点击左上 ...
- poj——1274 The Perfect Stall
poj——1274 The Perfect Stall Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 25709 A ...
- POJ 1780 【手工递归】【欧拉回路】
题意: 1.提供密码的位数. 2.密码的输入可以一直保持,取后n位作为密码.如果密码正确则开锁. 3.设计一种方法使得在输入最少的情况下破译.(即保证每个密码只输入一次) 4.输出输入的数字的序列. ...
- Servlet的Service方法和doget 和 dopost方法的区别,常见的错误解析
package com.sxt.in; import java.io.IOException; import javax.servlet.ServletException; import javax. ...
- Java中@SuppressWarnings注解用法(转)
背景: J2SE提供的最后一个注解是@SuppressWarnings.该批注的作用是给编译器一条指令,告诉它对被批注的代码元素内部的某些警告保持静默. @SuppressWarnings注解允许您选 ...
- ModelAndView对象作用
ModelAndView ModelAndView对象有两个作用: 作用一 :设置转向地址,如下所示(这也是ModelAndView和ModelMap的主要区别) ModelAndView mv = ...
- Win7 SP1 安装SQL Server 2012时提示“此计算机上的操作系统不符合 SQL Server 2012的最低要求”