Mac配置Hadoop最详细过程
Mac配置Hadoop最详细过程
原文链接: http://www.cnblogs.com/blog5277/p/8565575.html
原文作者: 博客园-曲高终和寡
https://www.cnblogs.com/landed/p/6831758.html
一.准备工作:
1. JDK1.7版本及以上(貌似Hadoop只支持1.6以上的版本,不确定,保险起见用1.7,我自己用的是1.8)
2. 2.7.3版本的Hadoop https://archive.apache.org/dist/hadoop/common/hadoop-2.7.3/ 下载那个二百多M的那个
二.配置SSH免密登录
1.打开Mac的远程连接
系统偏好设置-->共享-->远程登录

2.如果你读过,并且跟着配置过
[从零开始搭网站二]服务器环境配置:Mac电脑连接CentOS不用每次都输入密码
,可以跳过这一步,否则的话:
打开终端(terminal),输入并一直回车,问你yes/no记得输yes
ssh-keyagent -t
完成以后跳转到 ~/.ssh 目录下
cd ~/.ssh
查看目录下的文件
ls
确保你目录下有这两个密钥文件

3.输入以下代码,即可免密登录
cat ~/.ssh/id_rsa.pub > ~/.ssh/authorized_keys
4.验证,输入以下代码
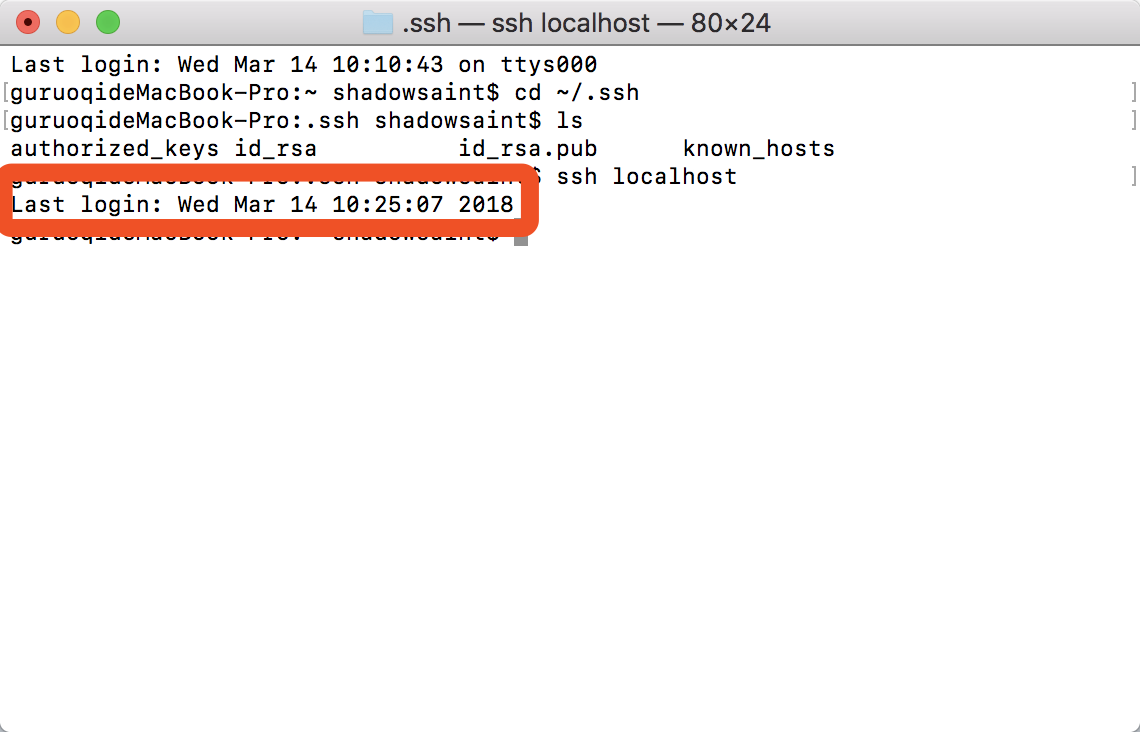
ssh localhost
如果如下图所示,直接提示 last login + 时间 就是没输密码直接登录了
三:解压缩并配置Hadoop
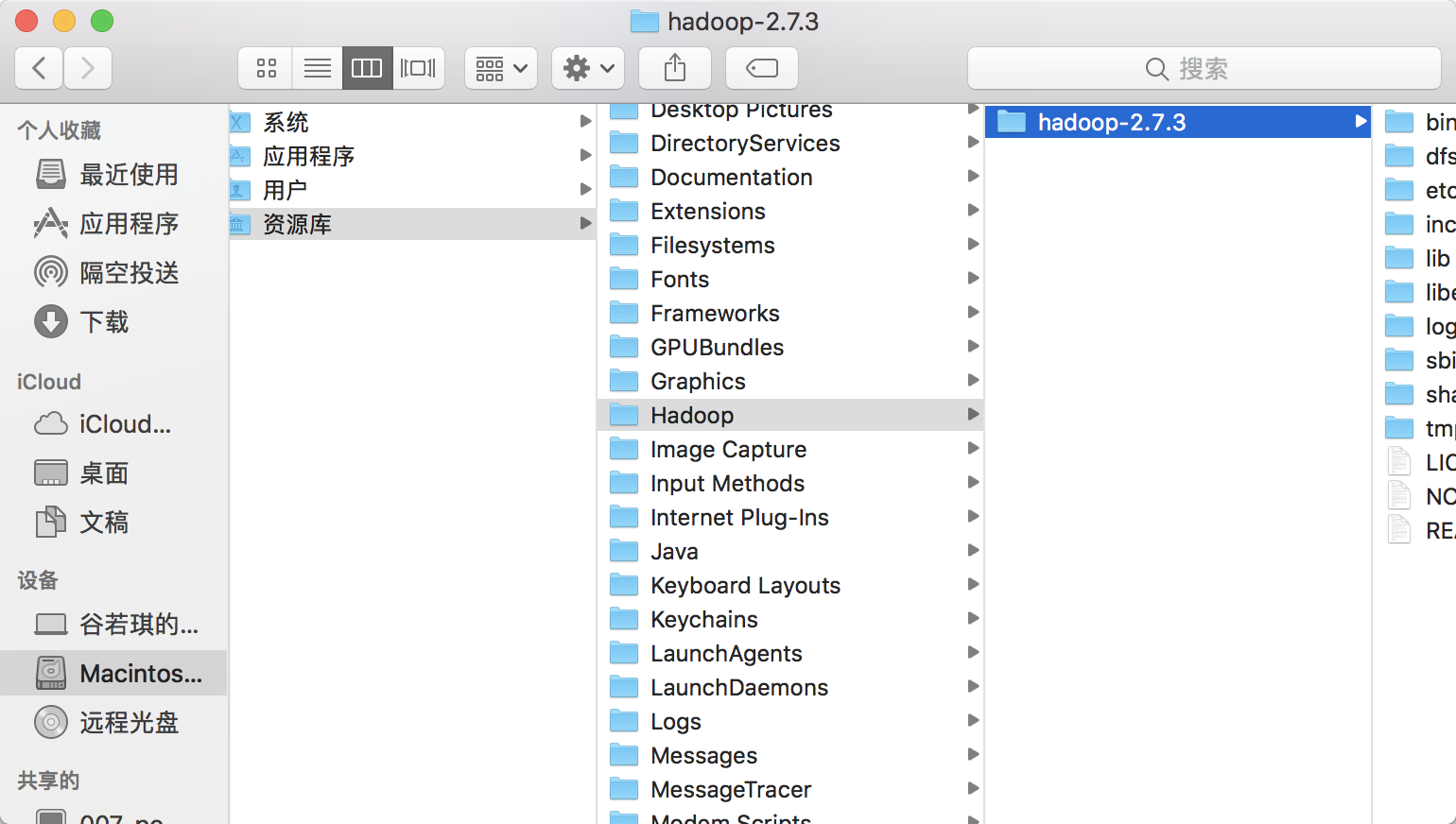
1.在你喜欢的位置建个文件夹并命名,我是所有安装的东西都放在 /Library/下 ,然后把第一步下载的Hadoop 2.7.3.tar.gz粘贴进来,双击提取到当前目录,如下图所示
2.打开终端,配置Hadoop的环境变量,输入以下代码,如果没有 /etc/profile 的话会新建,有的话会直接编辑(因为这个涉及系统环境变量编辑,可能会让你输入你的Mac的密码)
sudo vim /etc/profile
按 i 进入编辑模式
粘贴进如下代码:
export HADOOP_HOME=/Library/Hadoop/hadoop-2.7.3
export PATH=$PATH:$HADOOP_HOME/bin
这个时候打开你Hadoop的安装路径,定位到 /Library/Hadoop/hadoop-2.7.3 这个目录上,同时按下 option+command+c 复制文件路径 , 这样粘贴出来以后应该是这个样子:
/Library/Hadoop/hadoop-2.7.3
如果你的安装版本和路径和我不同,那么就把你复制的这个,替换掉上文环境变量里面的HADOOP_HOME里面的路径
替换完了以后按i退出编辑模式,按:wq!强制退出并保存,zai再输入下面的代码使改动立刻生效
source /etc/profile
3.找到你的Java的安装路径,定位到 Java/JavaVirtualMachines/jdk1.8.0_111.jdk/Contents/Home 这个目录上,同时按下 option+command+c 复制文件路径 , 这样粘贴出来以后应该是这个样子:
/Library/Java/JavaVirtualMachines/jdk1.8.0_144.jdk/Contents/Home
定位的文件夹如下图所示:

4.回到你Hadoop的安装路径下,开始编辑配置文件,这一步,以及下面所有的配置,全部都在 /Library/Hadoop/hadoop-2.7.3/etc/hadoop 这个路径下
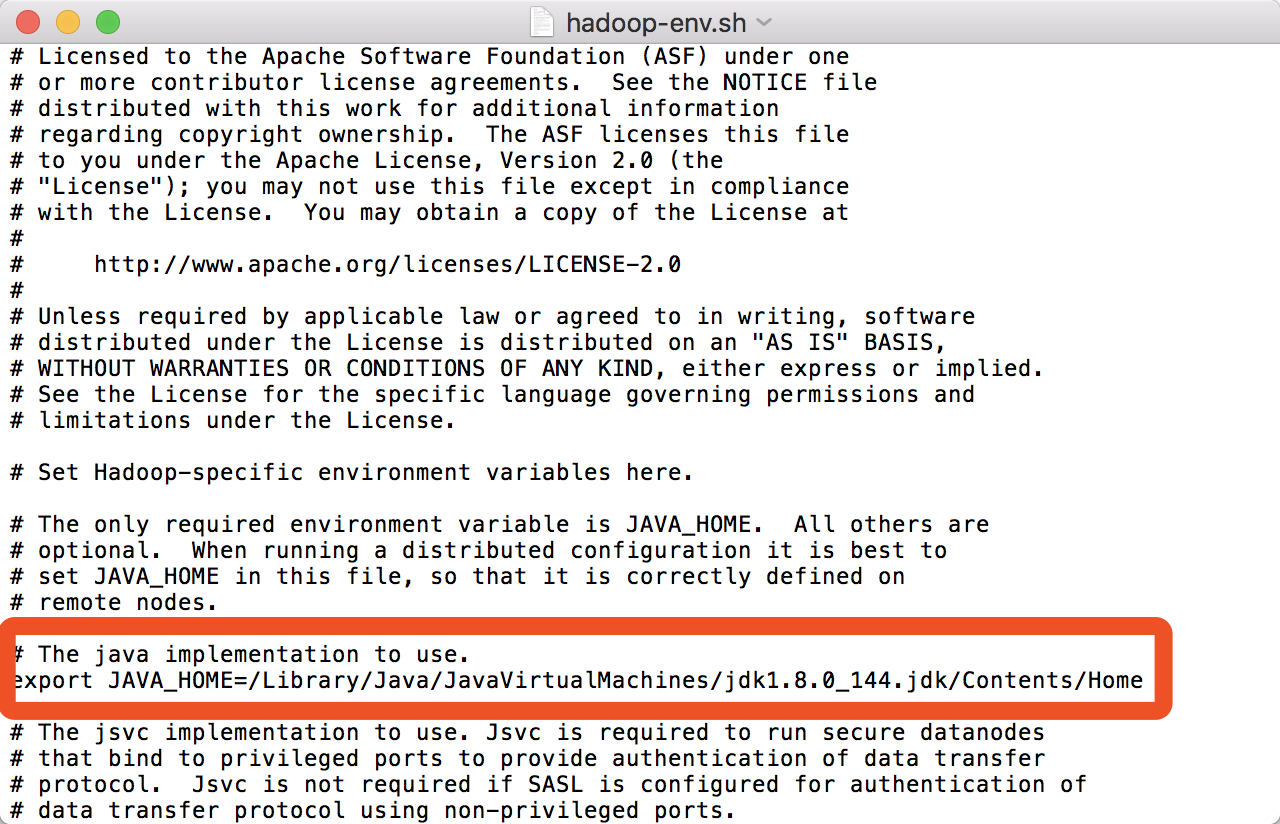
5.编辑 hadoop-env.sh 文件(右键-->打开方式-->文本编辑.app , 下同,不再赘述) , 把原本的JAVA_HOME换成你刚刚复制的Java路径:
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_144.jdk/Contents/Home
如图所示:
6.编辑 core-site.xml 文件 , 将 configuration 标签替换为(注意,安装Hadoop版本不一样,或者安装路径不一样的,记得替换掉加红加粗部分):
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://127.0.0.1:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/Library/Hadoop/hadoop-2.7.3/tmp</value>
<description>Abasefor other temporary directories.</description>
</property>
<property>
<name>hadoop.proxyuser.spark.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.spark.groups</name>
<value>*</value>
</property>
</configuration>
7.编辑 hdfs-site.xml 文件 , 将 configuration 标签替换为(注意红色部分):
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>127.0.0.1:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/Library/Hadoop/hadoop-2.7.3/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/Library/Hadoop/hadoop-2.7.3/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
8.复制并粘贴 mapred-site.xml.template 将 mapred-site.xml的副本.template 重命名为: mapred-site.xml , 然后编辑这个文件 , 将 configuration 标签替换为:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>127.0.0.1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>127.0.0.1:19888</value>
</property>
</configuration>
9.编辑 yarn-site.xml 文件 , 将 configuration 标签替换为:
<configuration> <!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>127.0.0.1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>127.0.0.1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>127.0.0.1:8035</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>127.0.0.1:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>127.0.0.1:8088</value>
</property>
</configuration>
10.编辑 slaves 文件,将里面的内容替换为(貌似默认就是这个,我改动了好多次了不记得了,确保是这个吧)
localhost
注意:
如果 hadoop 配置集群,可以将配置文件 etc/hadoop 下内容同步到其他机器上,并修改 slaves 文件
scp -r hadoop root@另一台机器名:/Library/hadoop/etc
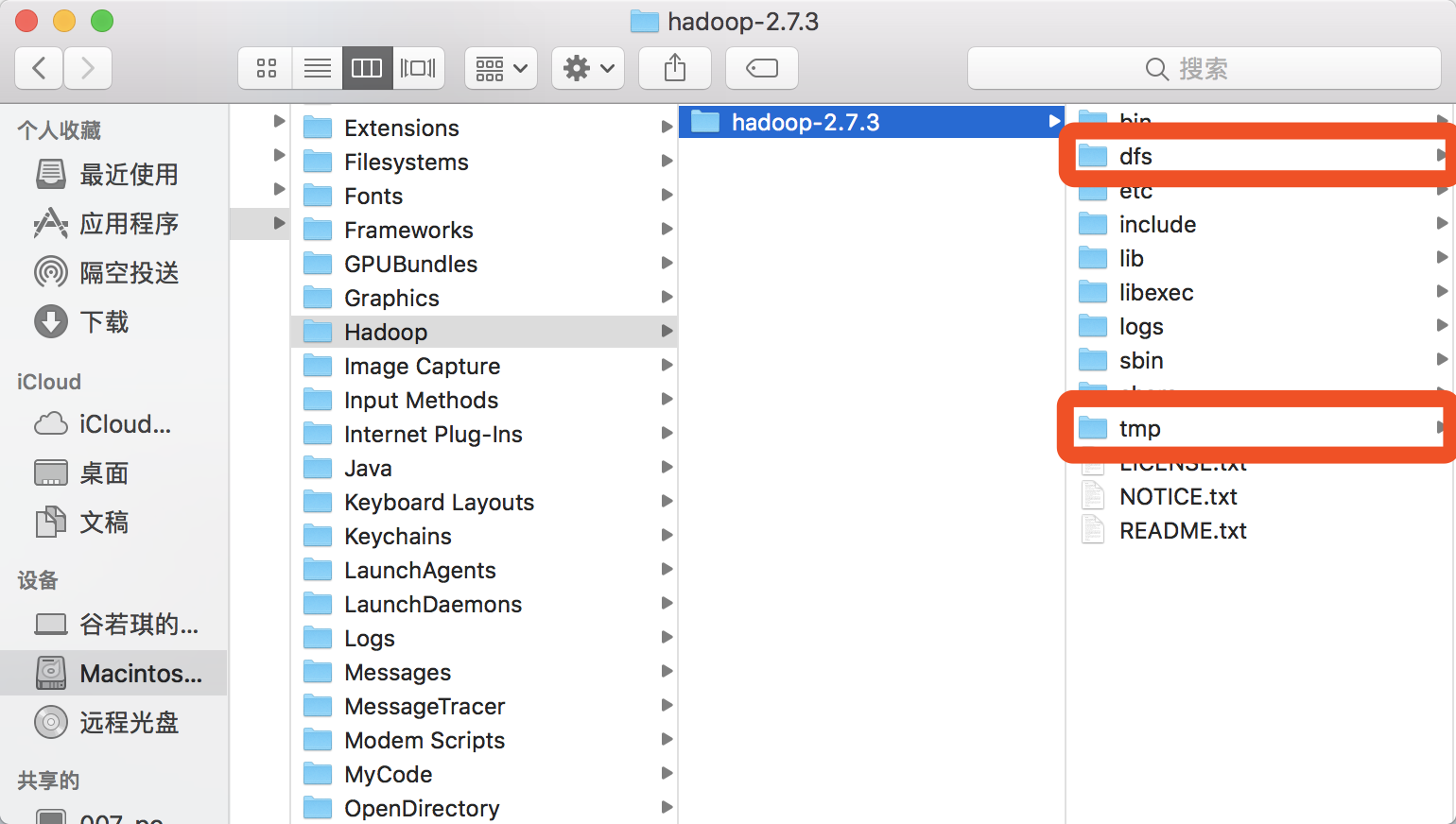
11.回到 /Library/Hadoop/hadoop-2.7.3 目录下,在该目录里面建立两个文件夹 tmp dfs ,如下图所示:
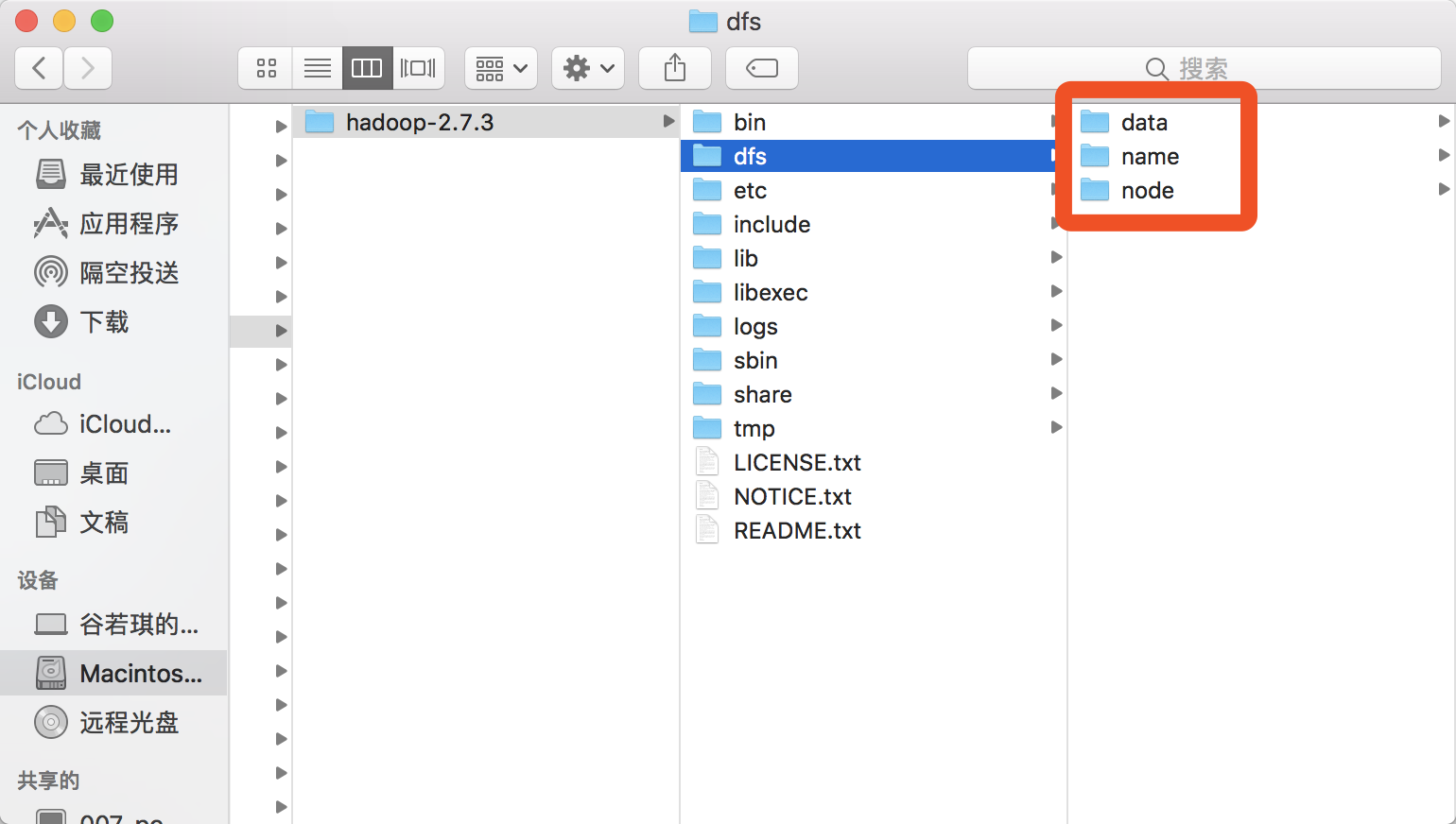
12.在dfs文件夹里面,建立三个文件夹 name node data , 如下图所示:
13.打开终端,定位到 /Library/Hadoop/hadoop-2.7.3/bin 这一级目录:
cd /Library/Hadoop/hadoop-2.7.3/bin
14.这一步是为了格式化一个新的hdfs系统,分配namenode,在终端里面输入:
./hadoop namenode –format
注意:
如果这一步不成功的话,比如出现以下提示(我特么在这里困了好久):
hadoop nodename nor servname provided, or not known
或者出现杂七杂八其他的错误提示,(不同的错误请根据提示,看你是namenode配置那里,即slaves里面配置的,还有各个配置文件里面的127.0.0.1这里的配置出错呢,还是别的什么地方出错,这里坑很多,加油...)
再或者你需要从新格式化一个新的hdfs系统,分配新的namenode的话,
请务必删除掉第10步创建的tmp和dfs文件夹,再从新创建,
因为hadoop 格式化只可进行一次,多次格式化会造成 namenode 结点和 datanode 结点配置文件中 ID 不统一,造成启动 hadoop 后 Namenode 等结点缺失,无法访问 hdfs 数据的问题
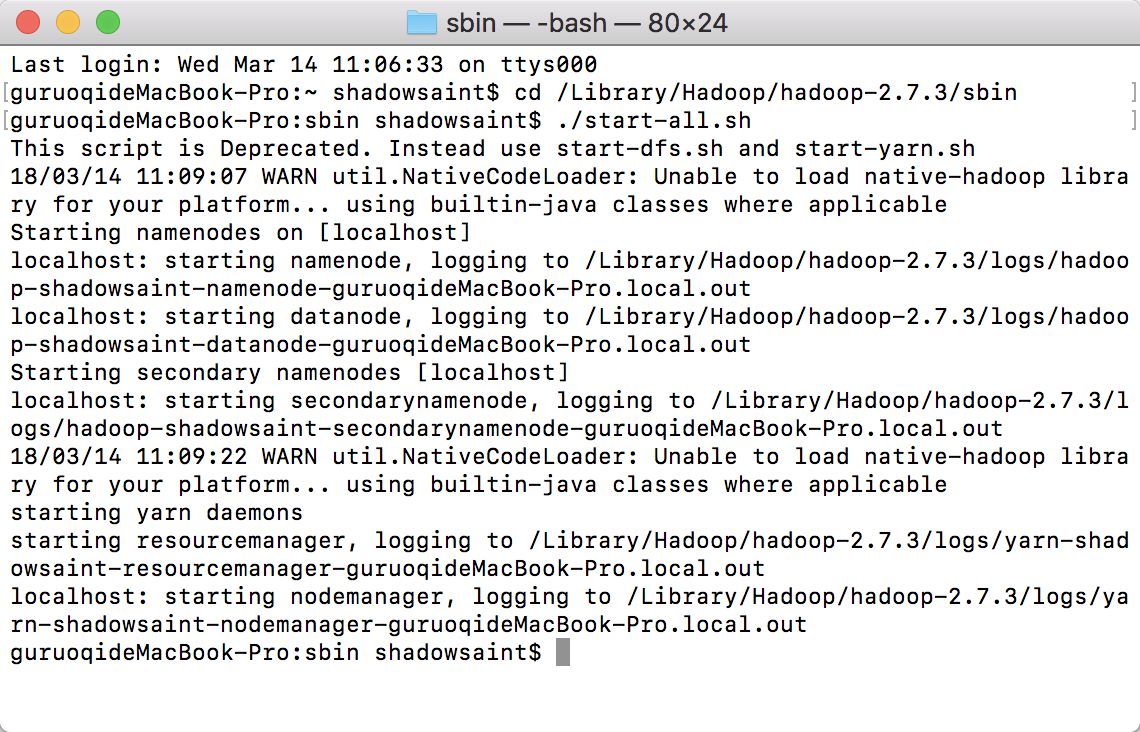
14,截止第13步,其实Hadoop配置已经完成了,接下来是启动,在终端定位到 /Library/Hadoop/hadoop-2.7.3/sbin 这个路径下:
cd /Library/Hadoop/hadoop-2.7.3/sbin
输入以下代码启动:
./start-all.sh
看到如下图所示的东西即为启动成功:
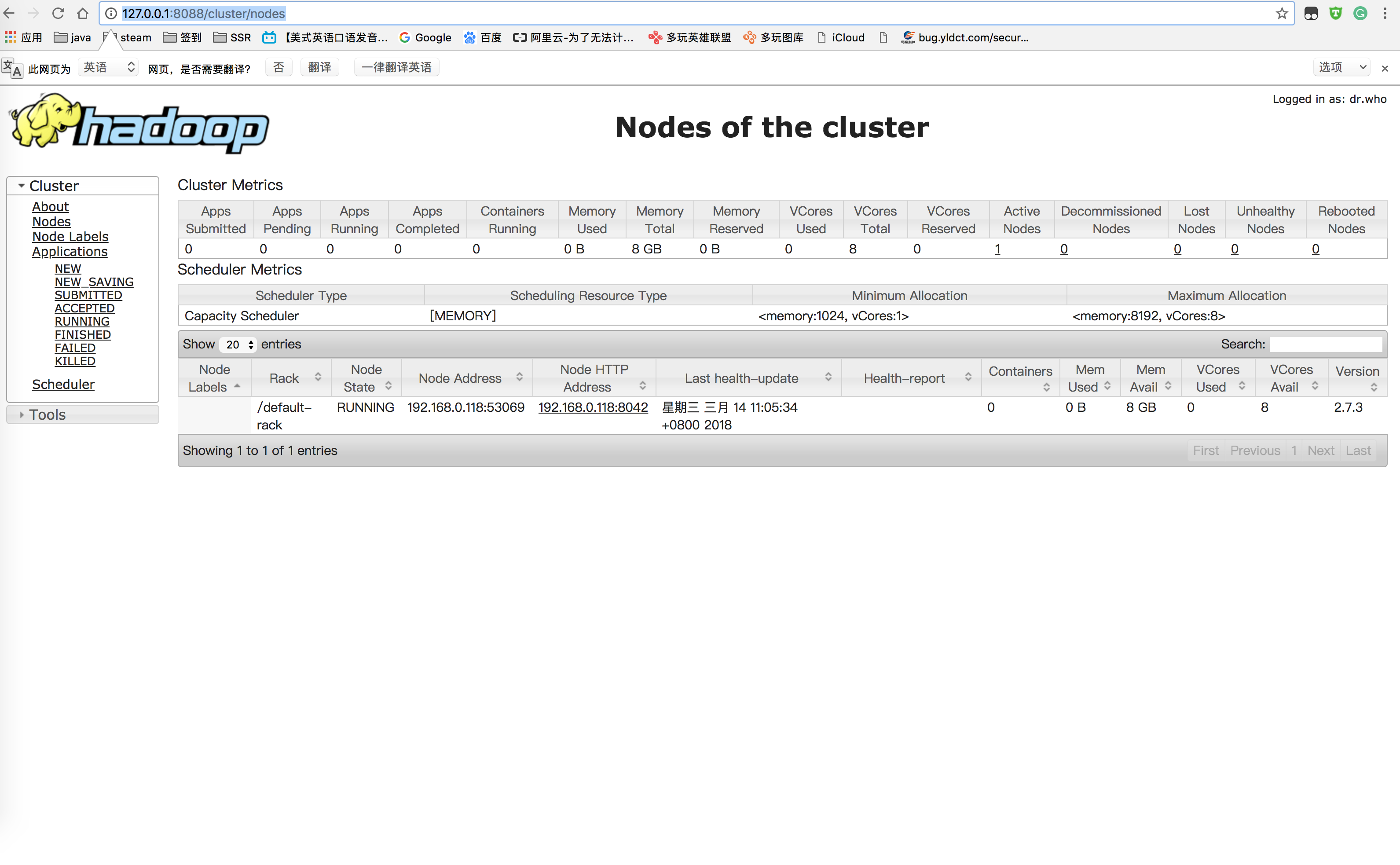
在浏览器输入:
http://127.0.0.1:8088/cluster/nodes
即可看到活动的node节点,如下图所示:
好啦,全部完成了,想要关闭Hadoop的话,就还是在sbin的目录下,输入:
./stop-all.sh
Mac配置Hadoop最详细过程的更多相关文章
- Webpack安装配置及打包详细过程
引言 前端经过漫长的发展,涌现出了很多实践方法来处理复杂的工作流程,让开发变得更加简便,其中,模块化可以使复杂的程序细化成为各个小的文件,而webpack并不强制你使用某种模块化方案,而是通过兼容所有 ...
- Linux云主机安装JDK,配置hadoop的详细方式
云主机我使用的是青云的,还有好多其他品牌,比如阿里云 unitedstack 等等. 注册完青云后,会有试用券发到账户,可以利用此券试用其服务. 1 首先创建好一个主机,按照提示选择好系统,创建好一个 ...
- mac 配置hadoop 2.6(单机和伪分布式)
一.准备工作: 安装jdk >= 1.7: http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133 ...
- Nginx下配置Https证书详细过程
一.Http与Https的区别HTTP:是互联网上应用最为广泛的一种网络协议,是一个客户端和服务器端请求和应答的标准(TCP),用于从WWW服务器传输超文本到本地浏览器的传输协议,它可以使浏览器更加高 ...
- 入侵本地Mac OS X的详细过程 转自https://yq.aliyun.com/articles/22459?spm=5176.100239.blogcont24250.10.CfBYE9
摘要: 本文从提升权限漏洞的一系列巧妙的方法来绕过受保护的Mac OS X.有些已经被处于底层控制,但由于它们存在着更多的认证和修补程序,我们不妨让这些提供出来,以便需要的人学习它们.虽然我不只是要利 ...
- 3、CentOS 6.5系统安装配置Tomcat 8详细过程
安装环境:CentOS-6.5 安装方式:源码安装 软件:apache-tomcat-8.0.0.RC3.tar.gz 安装前提 安装tomcat 将apache-tomcat-8.0.0.RC3.t ...
- Mac配置Scala和Spark最详细过程
Mac配置Scala和Spark最详细过程 原文链接: http://www.cnblogs.com/blog5277/p/8567337.html 原文作者: 博客园--曲高终和寡 一,准备工作 1 ...
- Redis主从配置详细过程
Redis的主从复制功能非常强大,一个master可以拥有多个slave,而一个slave又可以拥有多个slave,如此下去,形成了强大的多级服务器集群架构.下面楼主简单的进行一下配置. 1.上面安装 ...
- STM32F0xx_PWR低功耗配置详细过程
Ⅰ.概述 今天总结PWR部分知识,请看“STM32F0x128参考手册V8”第六章.提供的软件工程是关于电源管理中的停机模式,工程比较常见,但也是比较简单的一个实例,根据项目的不同还需要适当修改或者添 ...
随机推荐
- HTML经典模板总结(地址)
HTML经典模板总结 地址:http://download.csdn.net/tag/html%E6%A8%A1%E6%9D%BF?from=singlemessage
- ELK之安装searchguard后默认管理员用户admin修改
安装完elasticsearch之后会有一个默认的用户admin密码也为admin,该用户无法删除无法编辑修改密码,用于生产时安全性较差,需要修改默认密码或者删除该admin用户 使用工具生产加密密码 ...
- java线程和多线程同步
java的线程之间资源共享,所以会出现线程同步问题(即,线程安全) 一.线程创建: 方式①:extends java.lang.Thread,重写run(),run方法里是开启线程后要做的事..sta ...
- 实际体验Span<T> 的惊人表现
前言 最近做了一个过滤代码块功能的接口.就是获取一些博客文章做文本处理,然后这些博客文章的代码块太多了,很多重复的代码关键词如果被拿过来处理,那么会对文本的特征表示已经特征选择会有很大的影响.所以需要 ...
- asp.net mvc 简单实现一个账号只能在一个地方登录
原理: 假设用户在机器A登陆后, 这时用户再次在机器B登陆,会以当前会话的SessionID作为键,用户id作为值,插入dictionary集合中,集合再保存在application(保存在服务器 ...
- gitlab备份、恢复、升级
1.备份 gitlab的备份很简单,只要使用命令: gitlab-rake gitlab:backup:create 即可将当前的数据库.代码全部备份到/var/opt/gitlab/backups ...
- java框架之SpringBoot(16)-分布式及整合Dubbo
前言 分布式应用 在分布式系统中,国内常用 Zookeeper + Dubbo 组合,而 SpringBoot 推荐使用 Spring 提供的分布式一站式解决方案 Spring + SpringBoo ...
- Monte Carlo simulated annealing
蒙特·卡罗分子模拟计算 使用蒙特·卡罗方法进行分子模拟计算是按照以下步骤进行的: 1. 使用随机数发生器产生一个随机的分子构型. 2. 对此分子构型的其中粒子坐标做无规则的改变,产生一个新的分子构型. ...
- 关于12C中optimizer_adaptive_features参数介绍
optimizer_adaptive_features参数在OLAP数据仓库环境中可以获得较好的效果,实际在重上传轻查询的OLTP系统上,可以关闭这项新功能. 其主要功能是为了在语句执行过程中实时收集 ...
- git基本操作及上传代码到gitHub
1.基本配置: 配置用户名:git config --global user.name" "; 配置邮箱:git config --global user.email " ...