Mac配置Scala和Spark最详细过程
Mac配置Scala和Spark最详细过程
原文链接: http://www.cnblogs.com/blog5277/p/8567337.html
原文作者: 博客园--曲高终和寡
一,准备工作
1.下载Scala http://www.scala-lang.org/download/ 拖到最下面,下载for mac的版本

2.下载Spark http://spark.apache.org/downloads.html
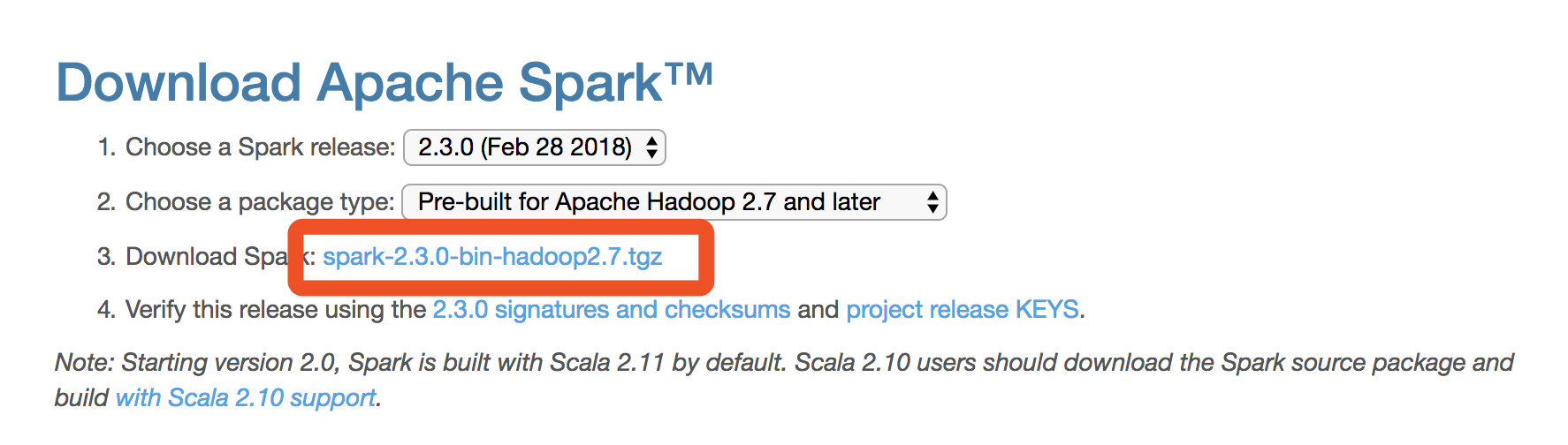
记得选版本啊,如果你是按照我之前的
Mac配置Hadoop最详细过程
配置的话就是最新的2.7版本以后的,就直接点3下载就可以了
二.安装Scala
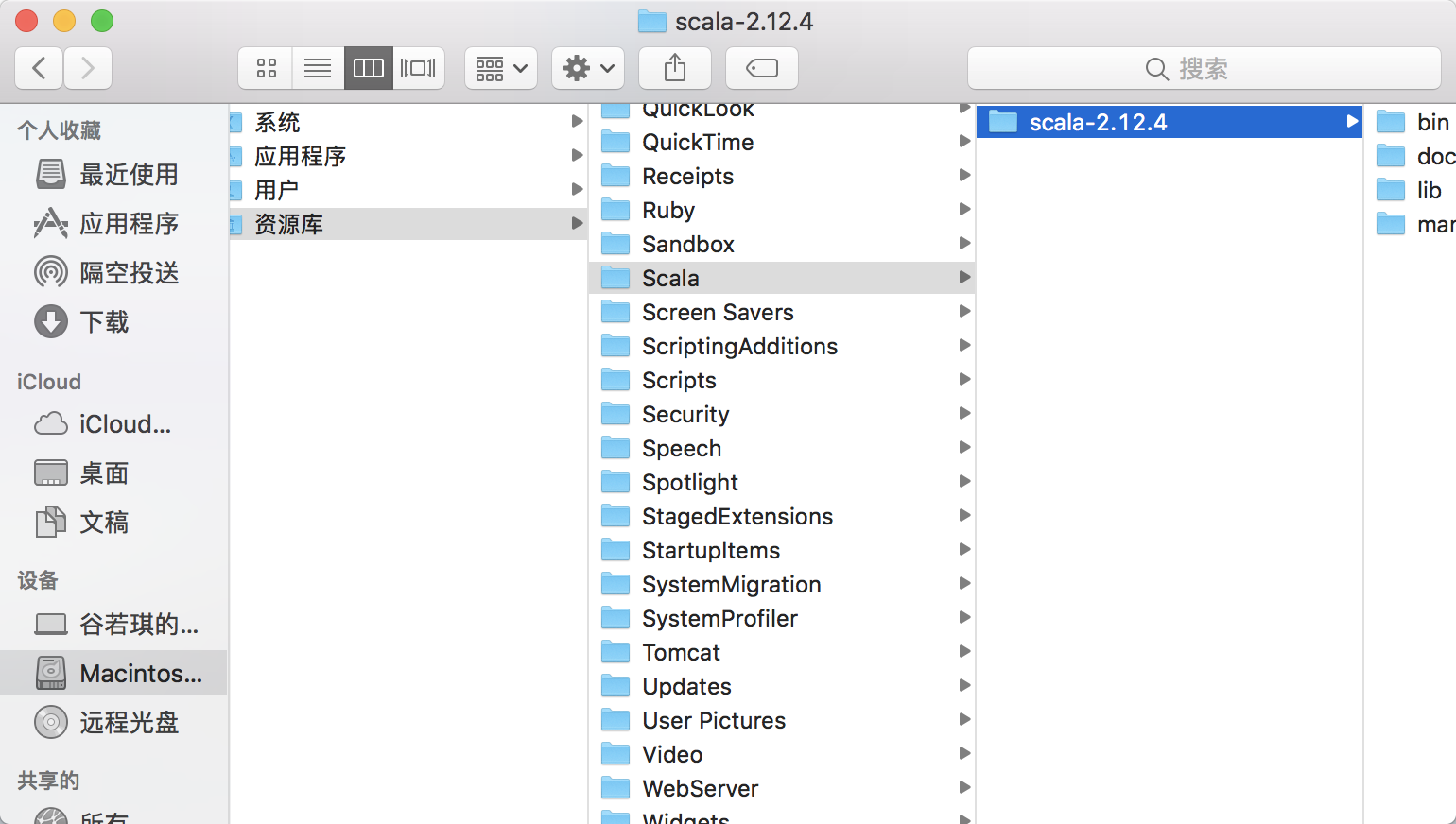
1.我个人喜欢把各个软件都放在/Library/目录下,所以这里我也在改目录下新建文件夹,提取后放进去,如下图所示:
2.配置Scala的环境变量,打开终端,输入以下代码(涉及系统环境变量修改,所以应该会让你输入Mac的密码):
sudo vim /etc/profile
在/Library/Scala/scala-2.12.4路径上,同时按下 option + command +c 复制你选中的文件的路径 , 粘贴出来如下:
/Library/Scala/scala-2.12.4
然后在刚刚你打开的终端里面,按 i 进入编辑模式 , 输入如下代码(如果路径/版本不一样,记得替换成你刚刚粘贴的那个)
export SCALA_HOME=/Library/Scala/scala-2.12.4
export PATH=$PATH:$SCALA_HOME/bin
按esc退出编辑模式,输入:wq!保存并退出,输入以下代码:
source /etc/profile
使得改动立刻生效,输入:
scala
即可看到你已经成功配置了Scala,如下图所示:
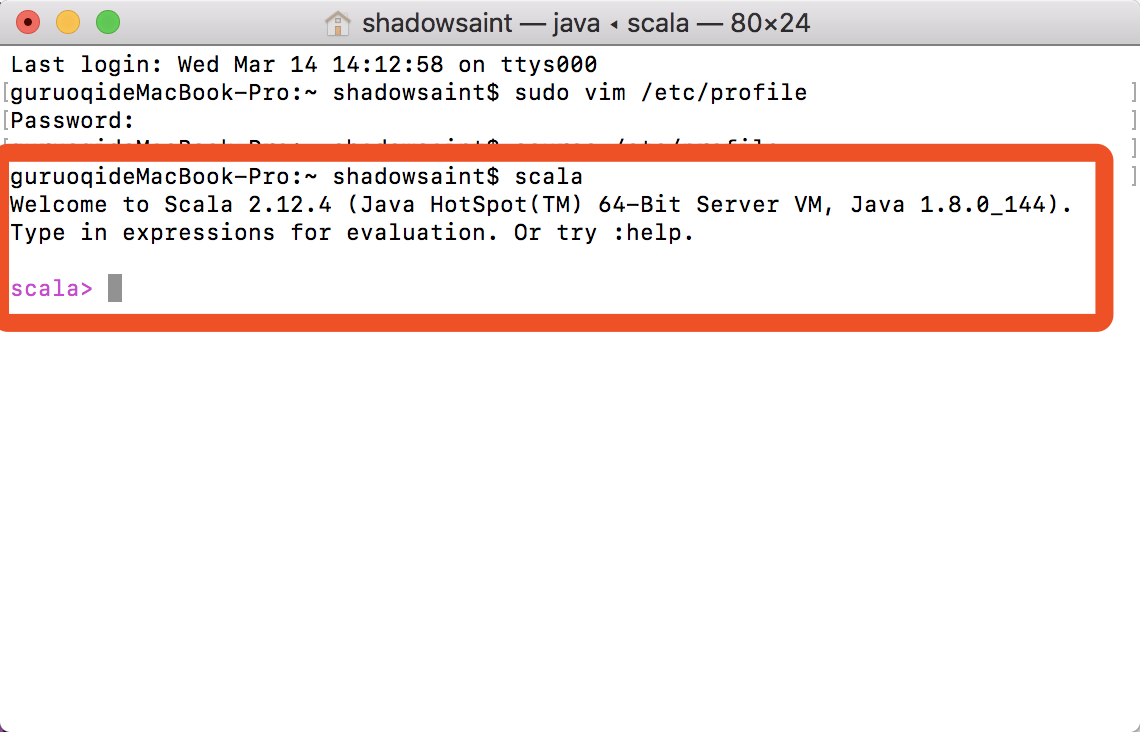
按下 control + c 或者输入 :quit 可以退出命令行Scala工具
三,安装Spark
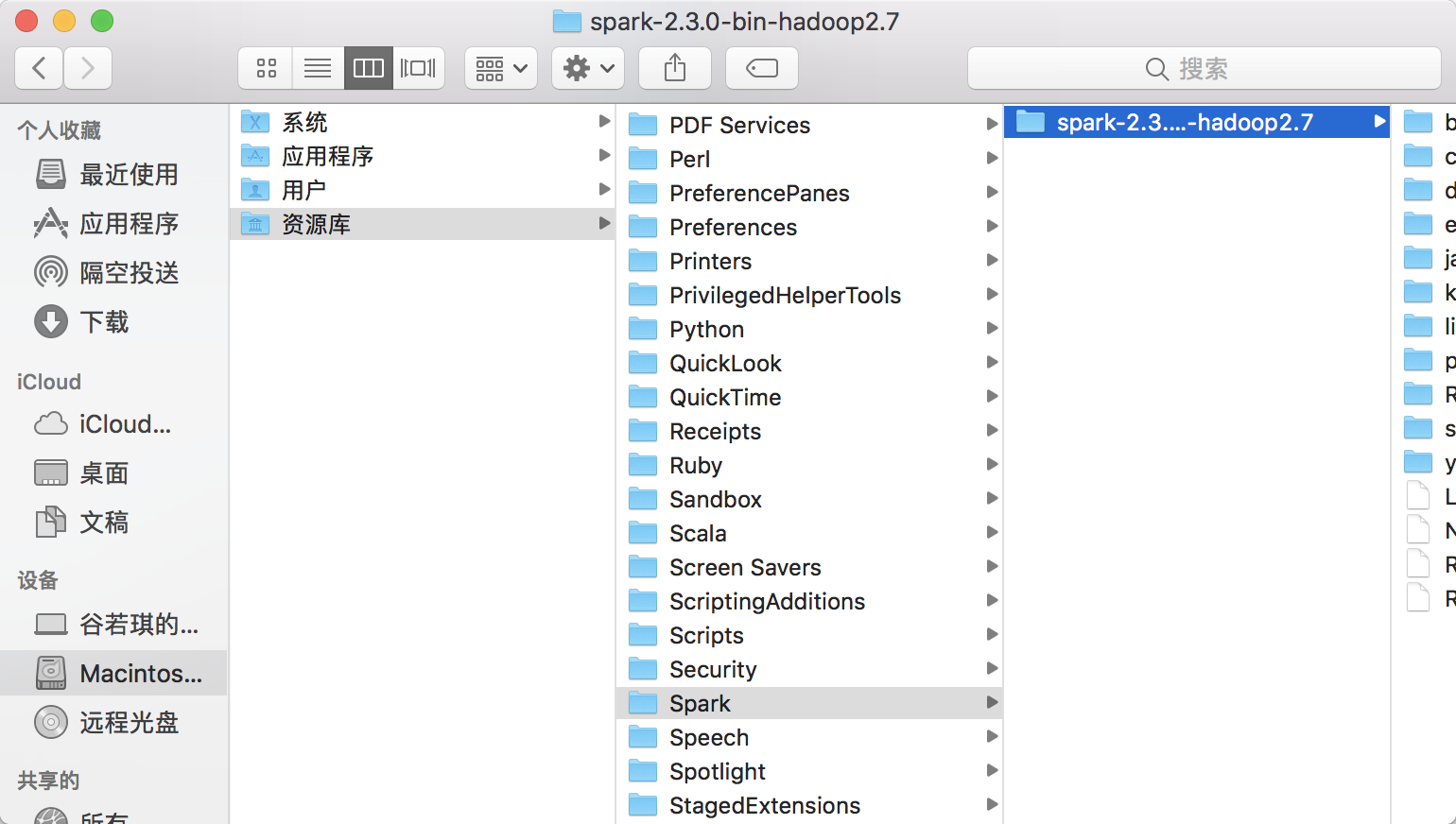
1.在/Library/下新建目录,把之前下载的东西提取并放进去,如下图所示:
2.配置Spark的环境变量,打开终端,输入以下代码(涉及系统环境变量修改,所以应该会让你输入Mac的密码):
sudo vim /etc/profile
在/Library/Spark/spark-2.3.0-bin-hadoop2.7路径上,同时按下 option + command +c 复制你选中的文件的路径 , 粘贴出来如下:
/Library/Spark/spark-2.3.0-bin-hadoop2.7
然后在刚刚你打开的终端里面,按 i 进入编辑模式 , 输入如下代码(如果路径/版本不一样,记得替换成你刚刚粘贴的那个)
export SPARK_HOME=/Library/Spark/spark-2.3.0-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin
按esc退出编辑模式,输入:wq!保存并退出,输入以下代码:
source /etc/profile
使得改动立刻生效
3.进入/Library/Spark/spark-2.3.0-bin-hadoop2.7/conf目录下,将 spark-env.sh.template 复制一份 , 把复制出来的 spark-env.sh的副本.template 重命名为 spark-env.sh 右键-->打开方式-->文本编辑.app
在末尾加入下面代码:
export SCALA_HOME=/Library/Spark/spark-2.3.0-bin-hadoop2.7 export SPARK_MASTER_IP=localhost export SPARK_WORKER_MEMORY=4g
4.截止上面,Spark已经配置完成了,下面测试一下,在终端中跳转至 /Library/Spark/spark-2.3.0-bin-hadoop2.7/sbin
cd /Library/Spark/spark-2.3.0-bin-hadoop2.7/sbin
输入
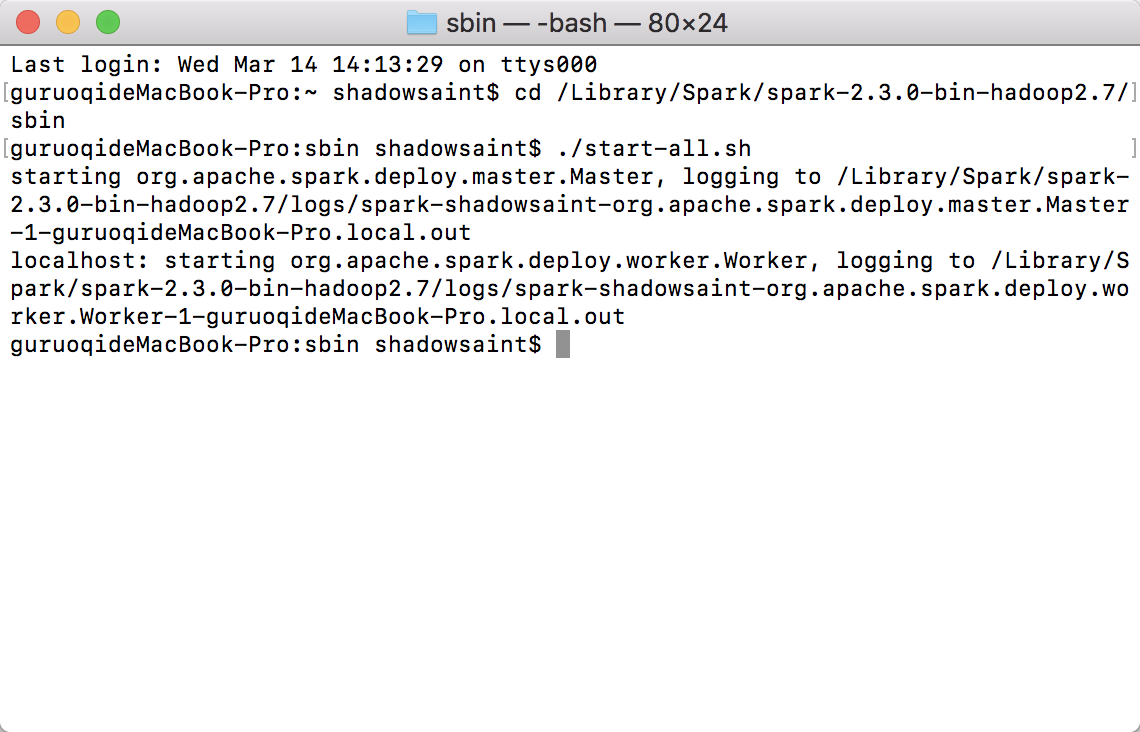
./start-all.sh
如下图所示,即为启动成功:
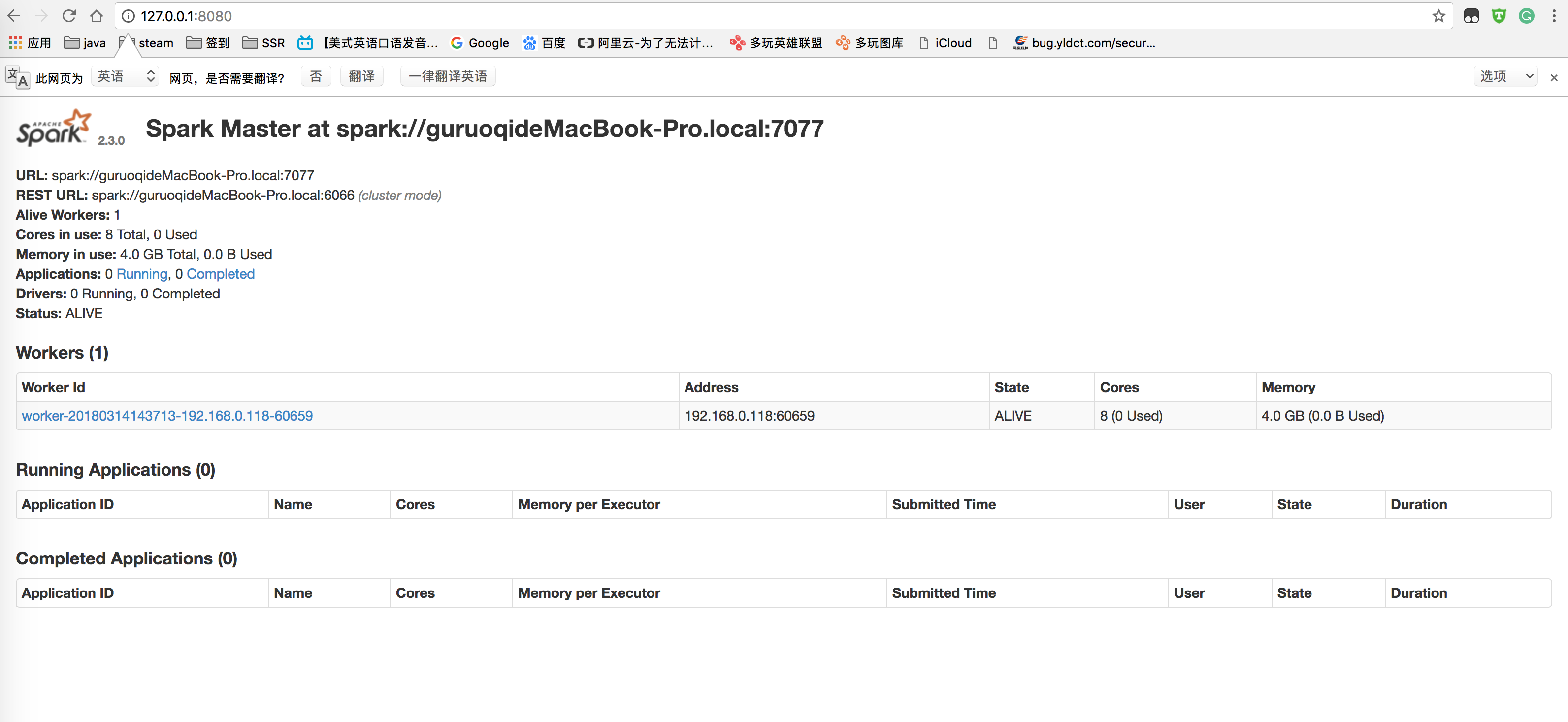
在浏览器输入以下网址即可看到打开的页面:
127.0.0.1:8080
关闭Spark的话还是在 /Library/Spark/spark-2.3.0-bin-hadoop2.7/sbin 目录下,输入
./stop-all.sh
Mac配置Scala和Spark最详细过程的更多相关文章
- idea配置scala编写spark wordcount程序
1.创建scala maven项目 选择骨架的时候为org.scala-tools.archetypes:scala-aechetype-simple 1.2 2.导入包,进入spark官网Docum ...
- Spark shuffle详细过程
有许多场景下,我们需要进行跨服务器的数据整合,比如两个表之间,通过Id进行join操作,你必须确保所有具有相同id的数据整合到相同的块文件中.那么我们先说一下mapreduce的shuffle过程. ...
- idea配置scala和spark
1 下载idea 路径https://www.jetbrains.com/idea/download/#section=windows 2安装spark spark-2.1.0-bin-hadoo ...
- 使用maven配置scala Hadoop spark开发环境
1. 新建maven project 2. Group id : org.scala-tools.archetypes Artifact id : scala-archetype-simple Ver ...
- Mac配置Hadoop最详细过程
Mac配置Hadoop最详细过程 原文链接: http://www.cnblogs.com/blog5277/p/8565575.html 原文作者: 博客园-曲高终和寡 https://www.cn ...
- <spark入门><Intellj环境配置><scala>rk入门><Intellj环境配置><scala>
# 写在前面: 准备开始学spark,于是准备在IDE配一个spark的开发环境. 嫌这篇格式不好的看这里链接 用markdown写的,懒得调格式了,么么哒 # 相关配置: ## 关于系统 * mac ...
- Mac下 如何配置虚拟机软件Parallel Desktop--超详细
Mac下 如何配置虚拟机软件Pparallel Desktop--超详细 Mac 的双系统解决方案有两种,一种是使用Boot Camp分区安装独立的Windows,一种是通过安装Parallels D ...
- Redis主从配置详细过程
Redis的主从复制功能非常强大,一个master可以拥有多个slave,而一个slave又可以拥有多个slave,如此下去,形成了强大的多级服务器集群架构.下面楼主简单的进行一下配置. 1.上面安装 ...
- STM32F0xx_PWR低功耗配置详细过程
Ⅰ.概述 今天总结PWR部分知识,请看“STM32F0x128参考手册V8”第六章.提供的软件工程是关于电源管理中的停机模式,工程比较常见,但也是比较简单的一个实例,根据项目的不同还需要适当修改或者添 ...
随机推荐
- juqery 回车事件 回车操作 回车搜索
html <form class="search_wrap" method="post" action=""> <div ...
- php(数组方法
什么是数组? 数组就是一组数据的集合 其表现形式就是内存中的一段连续的内存地址 数组名称其实就是连续内存地址的首地址 关于js中的数组特点 数组定义时无需指定数据类型 数组定义时可以无需指定数组长度 ...
- 内层DIV超出后,出现滚动条问题
使用:overflowy:'unset'属性,可以解决
- Django之中间件&信号&缓存&form上传
中间件 1.中间件是什么? 中间件顾名思义,是介于request与response处理之间的一道处理过程,相对比较轻量级,并且在全局上改变django的输入与输出.因为改变的是全局,所以需要谨慎实用, ...
- echart 判断数据是否为空
formatter 判断数据是否为空
- mysql报错Ignoring the redo log due to missing MLOG_CHECKPOINT between
mysql报错Ignoring the redo log due to missing MLOG_CHECKPOINT between mysql版本:5.7.19 系统版本:centos7.3 由于 ...
- Python中if __name__ == '__main__',__init__和self 的解析
1.2.1 一个.py文件被其他.py文件引用 假设我们有一个const.py文件,内容如下: 现在,我们写一个用于计算圆面积的area.py文件,area.py文件需要用到const.py文件中的P ...
- 【Spark-core学习之六】 Spark资源调度和任务调度
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk1.8 scala-2.10.4(依赖jdk1.8) spark ...
- 《CSS世界》读书笔记(八)
<!-- <CSS世界>张鑫旭著 --> 替换元素和非替换元素的距离有多远? 观点1:替换元素和非替换元素之间只隔了一个src属性! 在Firefox浏览器下,没有src属性的 ...
- HTTPS(SSL / TLS)免费证书申请及网站证书部署实战总结
服务器环境:windows server 2008 + tomcat7 废话不多说,先看部署效果: 一.免费证书申请 Let's Encrypt 简介:let's Encrypt 是一个免费的开 ...