Linux下的5种I/O模型(转)
| Linux下的五种I/O模型: |
l 阻塞I/O
l 非阻塞I/O
l I/O复用(select、poll、epoll)
l 信号驱动I/O(SIGIO)
l 异步I/O(Posix.1的aio_系列函数)
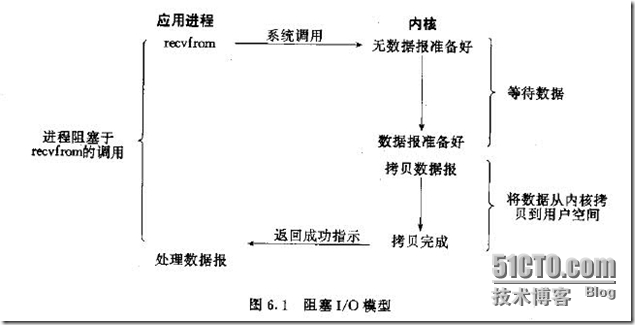
l 阻塞I/O模型
应用程序调用一个IO函数,导致应用程序阻塞,等待数据准备好。如果数据没有准备好,一直等待。。。。数据准备好了,从内核拷贝到用户空,IO函数返回成功指示。在这种模式下,基本上IO操作都会用一个Work Thread来进行(Java)。
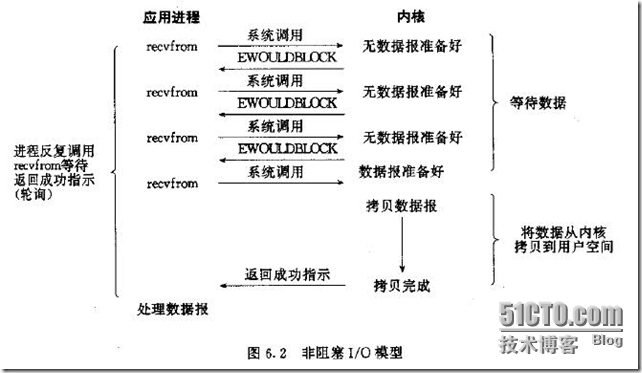
l 非阻塞I/O模型
我们把一个SOCKET接口设置为非阻塞就是告诉内核,当所请求的I/O操作无法完成时,不要将进程睡眠,而是返回一个错误。这样我们的I/O操作函数将不断的测试数据是否已经准备好,如果没有准备好,继续测试,直到数据准备好为止。在这个不断测试的过程中,会大量的占用CPU的时间。
把SOCKET设置为非阻塞模式,即通知系统内核:在调用Sockets API时,不要让线程睡眠,而应该让函数立即返回。在返回时,该函数返回一个错误代码。图所示,一个非阻塞模式套接字多次调用recv()函数的过程。前三次调用recv()函数时,内核数据还没有准备好。因此,该函数立即返回WSAEWOULDBLOCK错误代码。第四次调用recv()函数时,数据已经准备好,被复制到应用程序的缓冲区中,recv()函数返回成功指示,应用程序开始处理数据。
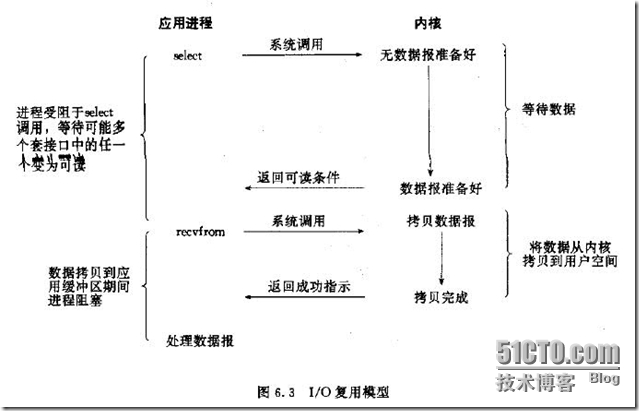
l I/O复用(select、poll、epoll)模型
I/O复用模型会用到select、poll、epoll函数,这几个函数也会使进程阻塞,但是和阻塞I/O所不同的是,这两个函数可以同时阻塞多个I/O操作。而且可以同时对多个读操作,多个写操作的I/O函数进行检测,直到有数据可读或可写时,才真正调用I/O操作函数。
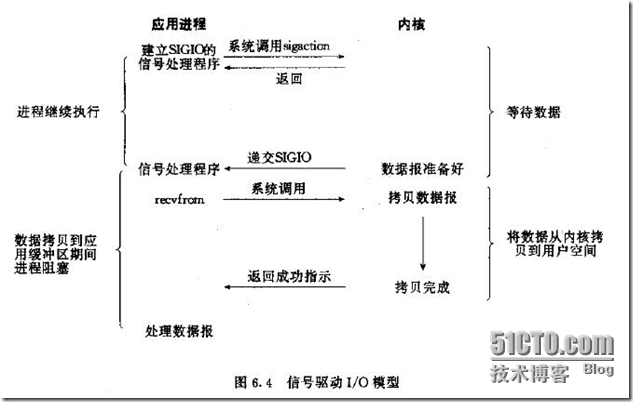
l 信号驱动I/O(SIGIO)模型
首先我们允许SOCKET接口进行信号驱动I/O,并安装一个信号处理函数,进程继续运行并不阻塞。当数据准备好时,进程会收到一个SIGIO信号,可以在信号处理函数中调用I/O操作函数处理数据。
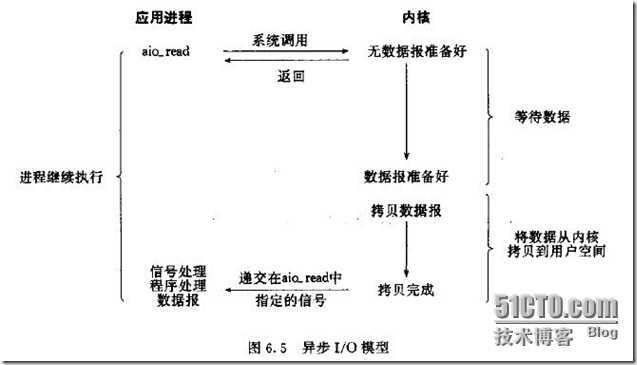
l 异步I/O(Posix.1的aio_系列函数)模型
调用aio_read函数,告诉内核描述字,缓冲区指针,缓冲区大小,文件偏移以及通知的方式,然后立即返回。当内核将数据拷贝到缓冲区后,再通知应用程序。
这个操作和信号驱动的区别就是:异步模式等操作完毕后才通知用户程序而信号驱动模式在数据到来时就通知用户程序。
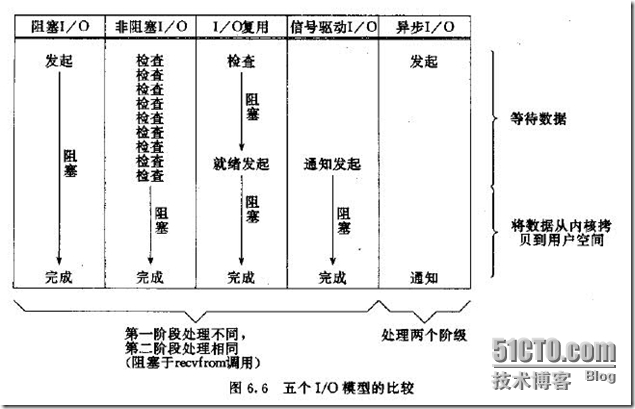
几种I/O模型的比较
前四种模型的区别是第一阶段,第二阶段基本相同,都是将数据从内核拷贝到调用者的缓冲区。而异步I/O的两个阶段都不同于前四个模型。
| Select、Poll、Epoll介绍 |
epoll跟select都能提供多路I/O复用的解决方案。在现在的Linux内核里有都能够支持,其中epoll是Linux所特有,而select则应该是POSIX所规定,一般操作系统均有实现
select:
select本质上是通过设置或者检查存放fd标志位的数据结构来进行下一步处理。这样所带来的缺点是:
1、 单个进程可监视的fd数量被限制,即能监听端口的大小有限。
一般来说这个数目和系统内存关系很大,具体数目可以cat /proc/sys/fs/file-max察看。32位机默认是102个。64位机默认是2048.
2、 对socket进行扫描时是线性扫描,即采用轮询的方法,效率较低:
当套接字比较多的时候,每次select()都要通过遍历FD_SETSIZE个Socket来完成调度,不管哪个Socket是活跃的,都遍历一遍。这会浪费很多CPU时间。如果能给套接字注册某个回调函数,当他们活跃时,自动完成相关操作,那就避免了轮询,这正是epoll与kqueue做的。
3、需要维护一个用来存放大量fd的数据结构,这样会使得用户空间和内核空间在传递该结构时复制开销大
poll:
poll本质上和select没有区别,它将用户传入的数组拷贝到内核空间,然后查询每个fd对应的设备状态,如果设备就绪则在设备等待队列中加入一项并继续遍历,如果遍历完所有fd后没有发现就绪设备,则挂起当前进程,直到设备就绪或者主动超时,被唤醒后它又要再次遍历fd。这个过程经历了多次无谓的遍历。
它没有最大连接数的限制,原因是它是基于链表来存储的,但是同样有一个缺点:
| 1、大量的fd的数组被整体复制于用户态和内核地址空间之间,而不管这样的复制是不是有意义。 2、poll还有一个特点是“水平触发”,如果报告了fd后,没有被处理,那么下次poll时会再次报告该fd。 |
epoll:
epoll支持水平触发和边缘触发,最大的特点在于边缘触发,它只告诉进程哪些fd刚刚变为就需态,并且只会通知一次。还有一个特点是,epoll使用“事件”的就绪通知方式,通过epoll_ctl注册fd,一旦该fd就绪,内核就会采用类似callback的回调机制来激活该fd,epoll_wait便可以收到通知
epoll的优点:
1、没有最大并发连接的限制,能打开的FD的上限远大于1024(1G的内存上能监听约10万个端口);
2、效率提升,不是轮询的方式,不会随着FD数目的增加效率下降。只有活跃可用的FD才会调用callback函数;
即Epoll最大的优点就在于它只管你“活跃”的连接,而跟连接总数无关,因此在实际的网络环境中,Epoll的效率就会远远高于select和poll。
3、 内存拷贝,利用mmap()文件映射内存加速与内核空间的消息传递;即epoll使用mmap减少复制开销。
select、poll、epoll 区别总结:
1、支持一个进程所能打开的最大连接数
| Select | 单个进程所能打开的最大连接数有FD_SETSIZE宏定义,其大小是32个整数的大小(在32位的机器上,大小就是32*32,同理64位机器上FD_SETSIZE为32*64),当然我们可以对进行修改,然后重新编译内核,但是性能可能会受到影响,这需要进一步的测试。 |
| Poll | poll本质上和select没有区别,但是它没有最大连接数的限制,原因是它是基于链表来存储的 |
| Epoll | 虽然连接数有上限,但是很大,1G内存的机器上可以打开10万左右的连接,2G内存的机器可以打开20万左右的连接 |
2、FD剧增后带来的IO效率问题
| Select | 因为每次调用时都会对连接进行线性遍历,所以随着FD的增加会造成遍历速度慢的“线性下降性能问题”。 |
| Poll | 同上 |
| Epoll | 因为epoll内核中实现是根据每个fd上的callback函数来实现的,只有活跃的socket才会主动调用callback,所以在活跃socket较少的情况下,使用epoll没有前面两者的线性下降的性能问题,但是所有socket都很活跃的情况下,可能会有性能问题。 |
3、 消息传递方式
| Select | 内核需要将消息传递到用户空间,都需要内核拷贝动作 |
| Poll | 同上 |
| Epoll | epoll通过内核和用户空间共享一块内存来实现的。 |
总结:
综上,在选择select,poll,epoll时要根据具体的使用场合以及这三种方式的自身特点。
1、表面上看epoll的性能最好,但是在连接数少并且连接都十分活跃的情况下,select和poll的性能可能比epoll好,毕竟epoll的通知机制需要很多函数回调。
2、select低效是因为每次它都需要轮询。但低效也是相对的,视情况而定,也可通过良好的设计改善。
Linux下的5种I/O模型(转)的更多相关文章
- []转帖] 浅谈Linux下的五种I/O模型
浅谈Linux下的五种I/O模型 https://www.cnblogs.com/chy2055/p/5220793.html 一.关于I/O模型的引出 我们都知道,为了OS的安全性等的考虑,进程是 ...
- Linux下的5种I/O模型与3组I/O复用
引言 上一篇文章中介绍了一些无缓冲文件I/O函数,但应该什么时机调用这些函数,调用这些I/O函数时进程和内核的行为如何,如何高效率地实现I/O?这篇文章就来谈一谈Linux下的5种I/O模型,以及高性 ...
- 浅谈Linux下的五种I/O模型 两篇别人的博客
http://blog.csdn.net/sinat_34990639/article/details/52778562 http://www.cnblogs.com/chy2055/p/5220 ...
- Linux下的五种I/O模型
堵塞I/O(blocking I/O) 非堵塞I/O (nonblocking I/O) I/O复用(select 和poll) (I/O multiplexing) 信号驱动I/O (signal ...
- 浅谈Linux下的五种I/O模型
一.关于I/O模型的引出 我们都知道,为了OS的安全性等的考虑,进程是无法直接操作I/O设备的,其必须通过系统调用请求内核来协助完成I/O动作,而内核会为每个I/O设备维护一个buffer.如下图所 ...
- Linux 下的五种 IO 模型
概念说明 用户空间与内核空间 现在操作系统都是采用虚拟存储器,那么对32位操作系统而言,它的寻址空间(虚拟存储空间)为4G(2的32次方).操作系统的核心是内核,独立于普通的应用程序,可以访问受保护的 ...
- (转)Linux下select, poll和epoll IO模型的详解
Linux下select, poll和epoll IO模型的详解 原文:http://blog.csdn.net/tianmohust/article/details/6677985 一).Epoll ...
- Linux 下的三种时间介绍
Linux 下的三种时间介绍: Access Time:简写为atime,表示文件访问的时间,当文件内容被访问时,更新atime时间 Modify Time:简写为mtime,表示文件内容修改的时间, ...
- [后渗透]Linux下的几种隐藏技术【转载】
原作者:Bypass 原文链接:转自Bypass微信公众号 0x00 前言 攻击者在获取服务器权限后,会通过一些技巧来隐藏自己的踪迹和后门文件,本文介绍Linux下的几种隐藏技术. 0x01 隐藏文件 ...
随机推荐
- vue.js中的computed和watch的区别
1.computed在调用时不需要加(),watch是不需要调用的2.computed如果属性没有发生改变时会从缓存中读取值,watch当属性发生改变时会接收到2个值:一个为新值,一个为旧值3.com ...
- Html Link 标签
Html Link 标签 Link 是 HTML Head 内部标签 <html> <head> <!-- link标签:rel="shortcut icon& ...
- elasticsearch 索引备份恢复
备份脚本 es_backup.sh : #!/bin/bash#备份昨天数据,删除30天前索引 host=`hostname`address="xxx@xxx.com" es_us ...
- 类自动调用to.string方法
所有对象都有toString()这个方法,因为它是Object里面已经有了的方法,而所有类都是继承Object,所以“所有对象都有这个方法” 它通常只是为了方便输出,比如System.out.prin ...
- Bootstrap3基础 page-header 标题下加分割线
内容 参数 OS Windows 10 x64 browser Firefox 65.0.2 framework Bootstrap 3.3.7 editor ...
- Mac OS X 清除DNS缓存
参考: Flushing your DNS cache in Mac OS X and Linux Mac OS X 清除DNS缓存 根据Mac OS X操作系统的版本选择以下命令: Mac OS X ...
- css基础参考文档
block inline-block inline区别 absolute定位详解:https://www.jianshu.com/p/a3da5e27d22b css浮动详解 float浮动 div变 ...
- java笔记 -- java变量与常量的声明
变量: 在Java中, 每一个变量属于一种类型. double salary int vacationDays; long earthPopulation; boolean done; 命名: 以字母 ...
- vue中插入Echarts示例(菜鸟记录)
- 第 8 章 容器网络 - 063 - 如何使用 Weave 网络?
如何使用 Weave 网络? weave 是 Weaveworks 开发的容器网络解决方案. weave 创建的虚拟网络可以将部署在多个主机上的容器连接起来. 对容器来说,weave 就像一个巨大的以 ...