scrapy系列(四)——CrawlSpider解析
CrawlSpider也继承自Spider,所以具备它的所有特性,这些特性上章已经讲过了,就再在赘述了,这章就讲点它本身所独有的。
参与过网站后台开发的应该会知道,网站的url都是有一定规则的。像django,在view中定义的urls规则就是正则表示的。那么是不是可以根据这个特性来设计爬虫,而不是每次都要用spider分析页面格式,拆解源码。回答是肯定的,scrapy提供了CrawlSpider处理此需求。
在CrawlSpider源码中最先定义的是类Rule:
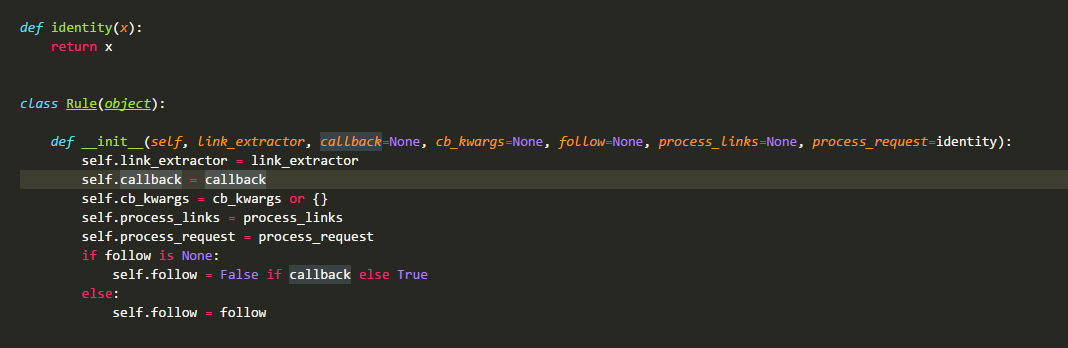
这个类非常的简单,也只在这里使用,相信大家都能看懂,具体的会在下面用法那边叙述,这边就先跳过。
再来看看今天的硬菜CrawlSpider类的源码:
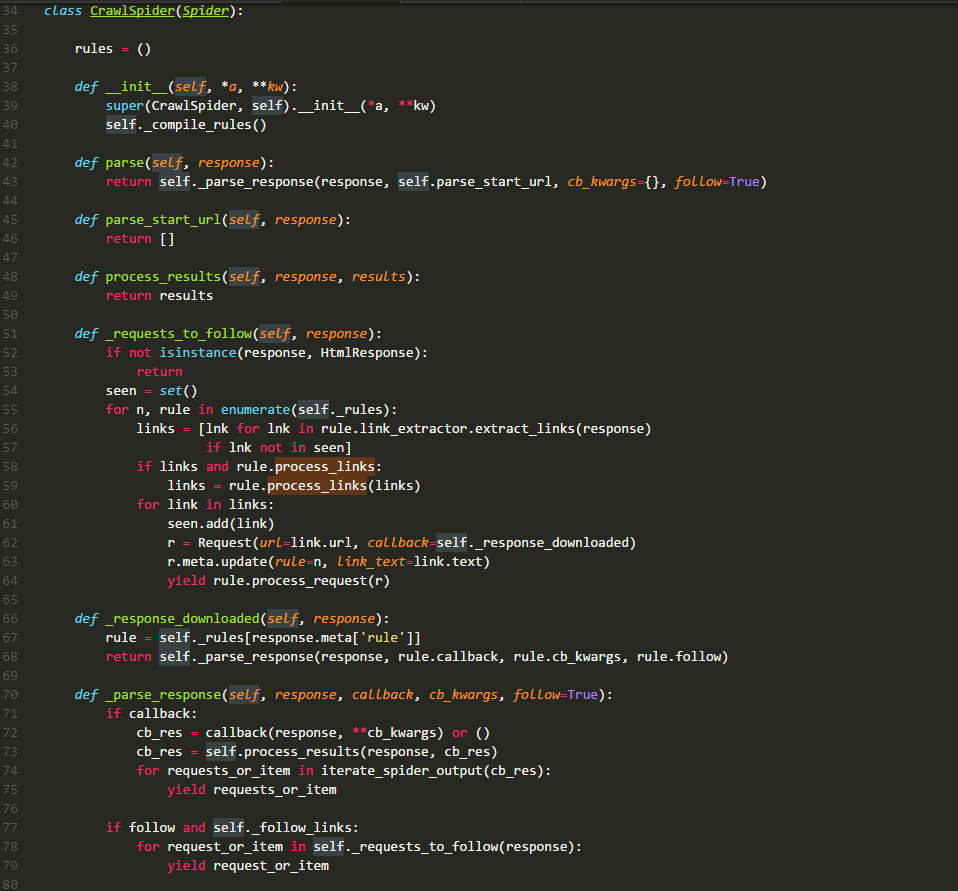

rules:
有经验的同学都知道它是一个列表,存储的元素时Rule类的实例,其中每一个实例都定义了一种采集站点的行为。如果有多个rule都匹配同一个链接,那么位置下标最小的一个rule将会被使用。
__init__:
在源码中可以看到,它主要就是执行了_compile_rules方法,这边暂时不讲。
parse:
默认回调方法,同上章一样。不过在这里进行了重写,这里直接调用方法_parse_response,并把parse_start_url方法作为处理response的方法。
parse_start_url:
这个方法在源码中只看其定义是没有什么发现的,需要查看其使用环境。它的主要作用就是处理parse返回的response,比如提取出需要的数据等,该方法也需要返回item、request或者他们的可迭代对象。它就是一个回调方法,和rule.callback用法一样。
_requests_to_follow:
阅读源码可以发现,它的作用就是从response中解析出目标url,并将其包装成request请求。该请求的回调方法是_response_downloaded,这里为request的meta值添加了rule参数,该参数的值是这个url对应rule在rules中的下标。
_response_downloaded:
该方法是方法_requests_to_follow的回调方法,作用就是调用_parse_response方法,处理下载器返回的response,设置response的处理方法为rule.callback方法。
_parse_response:
该方法将resposne交给参数callback代表的方法去处理,然后处理callback方法的requests_or_item。再根据rule.follow and spider._follow_links来判断是否继续采集,如果继续那么就将response交给_requests_to_follow方法,根据规则提取相关的链接。spider._follow_links的值是从settings的CRAWLSPIDER_FOLLOW_LINKS值获取到的。
_compile_rules:
这个方法的作用就是将rule中的字符串表示的方法改成实际的方法,方便以后使用。
from_crawler:
这个就不细说了,看看源码就好,两行代码。
整个数据的流向如下图所示:

关于CrawlSpider就先讲到这里,接下来会说说Rule类,该类的源码已经在文章的最上方贴出来了。
link_extractor:
该方法是一个Link Extractor实例,主要定义的就是链接的解析规则。
callback:
该值可以是一个方法,也可以是一个字符串(spider实例中一个方法的名称)。它就是一个回调方法,在上面的流程图中可以看到它所在的位置以及作用。这里要慎用parse做为回调方法,因为这边的parse已经不像spider类中的那样没有具体操作。
cb_kwargs:
这是一个字典,用于给callback方法传递参数,在CrawlSpider源码中可以看到其作用。
follow:
是一个布尔对象,表示是当前response否继续采集。如果callback是None,那么它就默认为True,否则为False。
process_links:
该方法在crawlspider中的_requests_to_follow方法中被调用,它接收一个元素为Link的列表作为参数,返回值也是一个元素为Link的列表。可以用该方法对采集的Link对象进行修改,比如修改Link.url。这里的如果你的目标url是相对的链接,那么scrapy会将其扩展成绝对的。源码就不带大家看了,了解就行。
process_request:
顾名思义,该方法就是处理request的,源码中也给出了一个样例(虽然没有任何作用),想修改request的小伙伴可以自己构造该方法。
Rule是不是很简单呢,可是他的属性link_extractor的花样就比较多了。默认的link解析器是LinkExtractor,也就是LxmlLinkExtractor。在之前的scrapy版本中还有其他的解析器,不过现在已经弃用了。对于该类的介绍官网文档已经有很详细的解释了,我就不再赘述了。
这章介绍的是scrapy中比较重要的一个类,希望本文会对小伙伴们有帮助,如果有疑问,欢迎在下面的评论区中提问。
scrapy系列(四)——CrawlSpider解析的更多相关文章
- java基础解析系列(四)---LinkedHashMap的原理及LRU算法的实现
java基础解析系列(四)---LinkedHashMap的原理及LRU算法的实现 java基础解析系列(一)---String.StringBuffer.StringBuilder java基础解析 ...
- scrapy CrawlSpider解析
CrawlSpider继承自Spider, CrawlSpider主要用于有规则的url进行爬取. 先来说说它们的设计区别: SpiderSpider 类的设计原则是只爬取 start_urls 中的 ...
- scrapy爬虫学习系列四:portia的学习入门
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- scrapy爬虫系列之五--CrawlSpider的使用
功能点:CrawlSpider的基本使用 爬取网站:保监会 主要代码: cf.py # -*- coding: utf-8 -*- import scrapy from scrapy.linkextr ...
- scrapy进阶(CrawlSpider爬虫__爬取整站小说)
# -*- coding: utf-8 -*- import scrapy,re from scrapy.linkextractors import LinkExtractor from scrapy ...
- sed修炼系列(四):sed中的疑难杂症
本文目录:1 sed中使用变量和变量替换的问题2 反向引用失效问题3 "-i"选项的文件保存问题4 贪婪匹配问题5 sed命令"a"和"N" ...
- RX系列四 | RxAndroid | 加载图片 | 提交表单
RX系列四 | RxAndroid | 加载图片 | 提交表单 说实话,学RxJava就是为了我们在Android中运用的更加顺手一点,也就是RxAndroid,我们还是先一步步来,学会怎么去用的比较 ...
- python爬虫入门(八)Scrapy框架之CrawlSpider类
CrawlSpider类 通过下面的命令可以快速创建 CrawlSpider模板 的代码: scrapy genspider -t crawl tencent tencent.com CrawSpid ...
- 爬虫框架之Scrapy(三 CrawlSpider)
如何爬取一个网站的全站数据? 可以使用Scrapy中基于Spider的递归方式进行爬取(Request模块回调parse方法) 还有一种更高效的方法,就是基于CrawlSpider的自动爬取实现 简介 ...
随机推荐
- git关于文件权限修改引起的冲突及忽略文件权限的办法
我们在使用git进行版本管理的时候,有时候只是修改了文件的权限,比如将pack.php修改为777,但其实文件内容并没有改变,但是git会认为此文件做了修改,原因是git把文件权限也算作文件差异的一部 ...
- 转载 Python 正则表达式入门(初级篇)
Python 正则表达式入门(初级篇) 本文主要为没有使用正则表达式经验的新手入门所写.转载请写明出处 引子 首先说 正则表达式是什么? 正则表达式,又称正规表示式.正规表示法.正规表达式.规则表达式 ...
- Java 单元测试顺序执行
坑死我了,原来@Before会执行多次. 通过函数名可以实现顺序执行,执行顺序和函数的位置无关. import org.junit.Before; import org.junit.BeforeCla ...
- app测试自动化之定位元素
app中元素定位是通过uiautomatorviewer来查看,这个是android sdk中自带的一个工具,可以在sdk家目录的tools下找到: 双击打开之后,点击第二个按钮即可把手机当前界面的元 ...
- Java中IO流中的装饰设计模式(BufferReader的原理)
本文粗略的介绍下JavaIO的整体框架,重在解释BufferReader/BufferWriter的演变过程和原理(对应的设计模式) 一.JavaIO的简介 流按操作数据分为两种:字节流与字符流. 流 ...
- .NET 线程池编程技术
摘要 深度探索 Microsoft .NET提供的线程池, 揭示什么情况下你需要用线程池以及 .NET框架下的线程池是如何实现的,并告诉你如何去使用线程池. 内容 介绍 .NET中的线程池 线程池中执 ...
- 使用shell脚本来自动化处理我们的工作,解放双手
Shell脚本介绍 1.Shell脚本,就是利用Shell的命令解释的功能,对一个纯文本的文件进行解析,然后执行这些功能,也可以说Shell脚本就是一系列命令的集合. 2.Shell可以直接使用在wi ...
- SpringBoot学习(一)—— web项目基础搭建
首先我们在浏览器打开这个网站 https://start.spring.io/ 打开后可以看到以下页面 在这里我们可以快速搭建一个SpringBoot基础项目,填写和选择完相应的信息后,我们点击那个绿 ...
- Maven教程(3)--Maven导入工程常见问题(编码、MavenArchiver、Lifecycle Mapping、maven install 没有反应)
常见错误: 常见错误一:These projects must be migrated to correctly function in this version of MyEclipse 需要修改编 ...
- shiro教程2(自定义Realm)
通过shiro教程1我们发现仅仅将数据源信息定义在ini文件中与我们实际开发环境有很大不兼容,所以我们希望能够自定义Realm. 自定义Realm的实现 创建自定义Realmjava类 创建一个jav ...