kafka笔记3(生产者)

创建Kafka生产者:
Kafka生产者有3个必选属性:
bootstrap.servers broker地址清单,格式为host:port ,清单中不必包含所有broker,但至少2个
key.serializer = org.apache.kafka.common.serialization.Serializer 接口类,生产者使用这个类把键对象序列化为字节数组
Kafka还提供了ByteArraySerializer,StringSerializer,IntegerSerializer 实现类
value.serializer 与key.serializer可以将值序列化
发送消息有3种方式:
发送并忘记(fire-and-forget) 发送消息给服务器,但是不关心是否正常到达
同步发送 使用send()发送信息,返回一个future对象,调用get()方法进行等待,了解信息是否正常发送
异步发送 调用send()函数,并指定一个回调函数,服务器在返回响应时调用该函数
生产者的可选属性:
acks 指定有多少个分区副本收到消息,生产者才会认为消息写入是成功的
ack=0 生产者在成功写入消息之前不会等待任何来自服务器的响应
ack=1 只要集群的首领节点收到信息,生产者就会收到一个来自服务器的成功响应
ack=all 所有参数与复制的节点全部收到消息,生产者才会收到一个来自服务器的响应,这种模式最安全
buffer.memory 设置生产者内存缓冲区大小,生产者使用它缓冲要发送到服务器的消息
compression.type 默认消息发送不使用压缩,该参数可以设置为snappy,gzip,lz4
retries 生产者可以重发消息的次数,默认 每次重试之间等待100ms,可以使用参数 retry.backoff.ms参数改变这个时间间隔
batch.size 指定一个批次可以使用的内存大小,按照字节数计算
linger.ms 指定生产者在发送批次之前等待更多消息加入批次的时间。Kafkaproducer 会在批次填满或linger.ms达到上限时把批次发送出去
client.id 该参数可以指定任意的字符串,服务器会用它识别信息的来源,还可以用在日志和配额指标里
max.in.flight.requests.per.connection 指定生产者在收到服务器响应之前可以发送多少个消息,值越高越占用内存;设为1可以保证消息是按照发送顺序写入服务器的
timeout.ms reuqest.timeout.ms metadata.fetch.timeout.ms
request.timeout.ms 指定生产者在发送数据时等待服务器返回响应的时间
metadata.timeout.ms 指定生产者在获取元数据时等待服务器返回响应时间
tiemout.ms指定broker等待同步副本返回消息确认的时间,与acks的配置相匹配
max.block.ms 指定调用send()或partitionsFor()方法获取元数据时生产者的阻塞时间,当阻塞时间到达max.block.ms时,生产者会抛出异常
max.request.size 控制生产者发送的请求大小,指能发送的单个消息的最大值或单个请求里所有消息的总和
broker对可接收的消息最大值也有自己的限制(message.max.bytes),两边配置最好匹配,避免生产者发送消息被拒绝
receive.buffer.bytes 和 send.buffer.bytes
这2个参数分别指定了TCP socket接收和发送数据包缓冲区大小,默认-1
max.in.flight.requests.per.connection=1 保证了消息的顺序,如果大于1,第一批次写入失败后,重试成功可能会改变消息的顺序
序列化器:
自定义序列化器
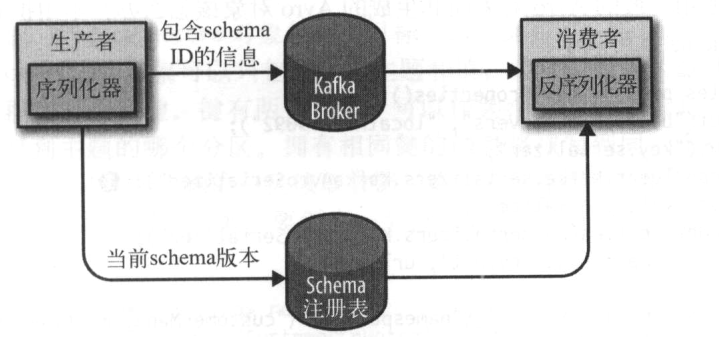
Avro序列化
Kafka使用Avro序列器是通过schema注册表来实现的,schema注册表不属于Kafka
kafka笔记3(生产者)的更多相关文章
- Kafka笔记整理(一)
Kafka简介 消息队列(Message Queue) 消息 Message 网络中的两台计算机或者两个通讯设备之间传递的数据.例如说:文本.音乐.视频等内容. 队列 Queue 一种特殊的线性表(数 ...
- Kafka笔记整理(三):消费形式验证与性能测试
Kafka消费形式验证 前面的<Kafka笔记整理(一)>中有提到消费者的消费形式,说明如下: .每个consumer属于一个consumer group,可以指定组id.group.id ...
- kafka笔记——入门介绍
中文文档 目录 kafka的优势 首先几个概念 kafka的四大核心API kafka的基本术语 主题和日志(Topic和Log) 每个分区都是一个顺序的,不可变的队列,并且可以持续的添加,分区中的每 ...
- 《Kafka笔记》3、Kafka高级API
目录 1 Kafka高级API特性 1.1 Offset的自动控制 1.1.1 消费者offset初始策略 1.1.2 消费者offset自动提交策略 1.2 Acks & Retries(应 ...
- kafka学习笔记2:生产者
这次的笔记主要记录一下kafka的生产者的使用和一些重要的参数. 文中主要截图均来自kafka权威指南 主要涉及到两个类KafkaProducer和ProducerRecord. 总览 生产者的主要架 ...
- Kafka笔记—可靠性、幂等性和事务
这几天很忙,但是我现在给我的要求是一周至少要出一篇文章,所以先拿这篇笔记来做开胃菜,源码分析估计明后两天应该能写一篇.给自己加油~,即使没什么人看. 可靠性 如何保证消息不丢失 Kafka只对&quo ...
- Kafka笔记--使用ubuntu为bocker(服务器)windows做producer和comsumer(客户端)
原文连接:http://www.cnblogs.com/davidwang456/p/4201875.html 程序仍然使用之前的一篇博文中的例子 :http://www.cnblogs.com/gn ...
- Kafka笔记--参数说明及Demo
参考资料:http://blog.csdn.net/honglei915/article/details/37563647参数说明:http://ju.outofmemory.cn/entry/119 ...
- kafka 幂等生产者及事务(kafka0.11之后版本新特性)
1. 幂等性设计1.1 引入目的生产者重复生产消息.生产者进行retry会产生重试时,会重复产生消息.有了幂等性之后,在进行retry重试时,只会生成一个消息. 1.2 幂等性实现1.2.1 PID ...
随机推荐
- hdoj:2051
#include <iostream> #include <string> #include <vector> #include <algorithm> ...
- Android WebRTC开发入门
在学习 WebRTC 的过程中,学习的一个基本步骤是先通过 JS 学习 WebRTC的整体流程,在熟悉了整体流程之后,再学习其它端如何使用 WebRTC 进行互联互通. 申请权限 Camera 权限 ...
- Android 8 蓝牙 扫描流程
记录android 8 蓝牙扫描设备的流程 src/com/android/settings/bluetooth/BluetoothSettings.java @Override protected ...
- ajax json struts JSP传递消息到action返回数据到JSP
ACTION package actions; import com.opensymphony.xwork2.ActionSupport; import net.sf.json.JSONObject; ...
- POI导出Excel发现不可读取的内容
环境说明:MyEclipse Tomcat7.0 通过后台查询数据,导出Excel在打开时会出现以下提示: 点击否,则不显示任何内容,点击是,弹出 查看修改记录为: 通过WPS打开不会出现任何提示,可 ...
- 三维计算机视觉 — 中层次视觉 — Point Pair Feature
机器人视觉中有一项重要人物就是从场景中提取物体的位置,姿态.图像处理算法借助Deep Learning 的东风已经在图像的物体标记领域耍的飞起了.而从三维场景中提取物体还有待研究.目前已有的思路是先提 ...
- geotrellis使用(四十二)将 Shp 文件转为 GeoJson
前言 一个多月没有写博客了,今天尝试着动笔写点. 原因很多,最重要的原因是我转行了.是的,我离开了开发岗位,走向了开发的天敌-产品经理.虽然名义上是产品经理,但是干的事情也很杂,除了不写代码,其他的都 ...
- mysql之表格的关联关系
1.’基本模式有多对一,多对多,一对一.关联的两个基本组建为外键列和参照列 典型的多对一模式,很普遍,如部门表和员工表,即一个部门可以有多个员工. 对于多对多的模式,就需要建立中间表,将其转换为多对一 ...
- hdu 1704 Rank (floyd闭包)
Rank Time Limit: 1000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total Submis ...
- Nestjs 链接mysql
文档 下插件 λ yarn add @nestjs/typeorm typeorm mysql 创建 cats模块, 控制器,service λ nest g mo cats λ nest g co ...