词向量编码 word2vec
word2vec
word2vec 是Mikolov 在Bengio Neural Network Language Model(NNLM)的基础上构建的一种高效的词向量训练方法。
词向量
词向量(word embedding ) 是词的一种表示,是为了让计算机能够处理的一种表示。 因为目前的计算机只能处理数值, 诸英文,汉字等等它是理解不了的, 最简单地让计算机处理自然语言的方式就是为每个词编号, 每个编号就代表其对应的词, 这就是one-hot编码(或称one-hot前身,因为one-hot 一般以向量形式呈现, 向量维度是词典的词数量, 每个词的one-hot词向量只在编号位置取1,其余维度只取0)。但很明显,one-hot编码是不能表示词与词之间的(隐含)关系的。 基于Markov 性质构建的n-gram模型,随着 n 的增大,词与词之间的关系的表达更清晰,但计算量却呈可怕的指数级增长。除了巨无霸企业,很少有公司或个人用得来。 所以需要一种可以表示词与词之间内在联系的并且获得还相对容易的词向量。
在此方向做出努力的人有很多, 但真正给人留下印象的首推NNLM。
NNLM
Bengio的NNLM如下图所示, 是这样的一种三层网络结构: 第一层是投影层, 即将每个词投影成一个具有固定维度的向量,一个序列的所有词向量都进入下一层, 所有的词向量首尾顺次相接构成一个大的向量, 最后经过一个全连接层再加上softmax 来预测下一个词的词向量(图上的虚线表示第一层的数据与第三层也是连通)。
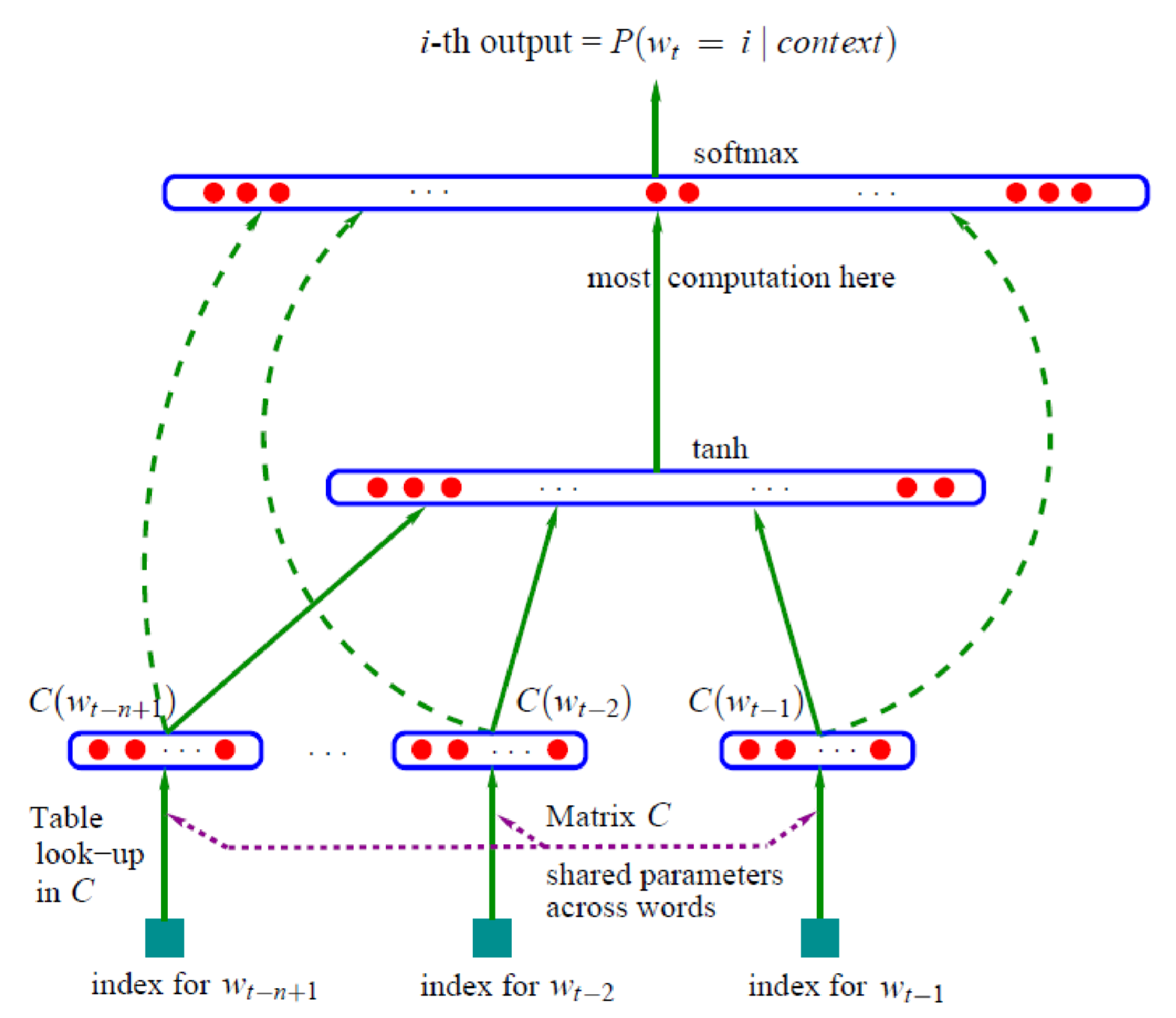
公平的说,这样的结构已经够简单,够高效了。但竟还有优化空间,而且还是更加高效的优化。这就是Mikolov的word2vec.
word2vec
word2vec 是在NNLM的基础上做的大量优化。word2vec的建模方式,有两个版本, 一个是Continuous bag of words (cbow), 另一个是 skip-gram. 实现方式也有两个方式: 一个是 Hierarchical softmax 另一个是Negative Sampling.
word2vec 结构
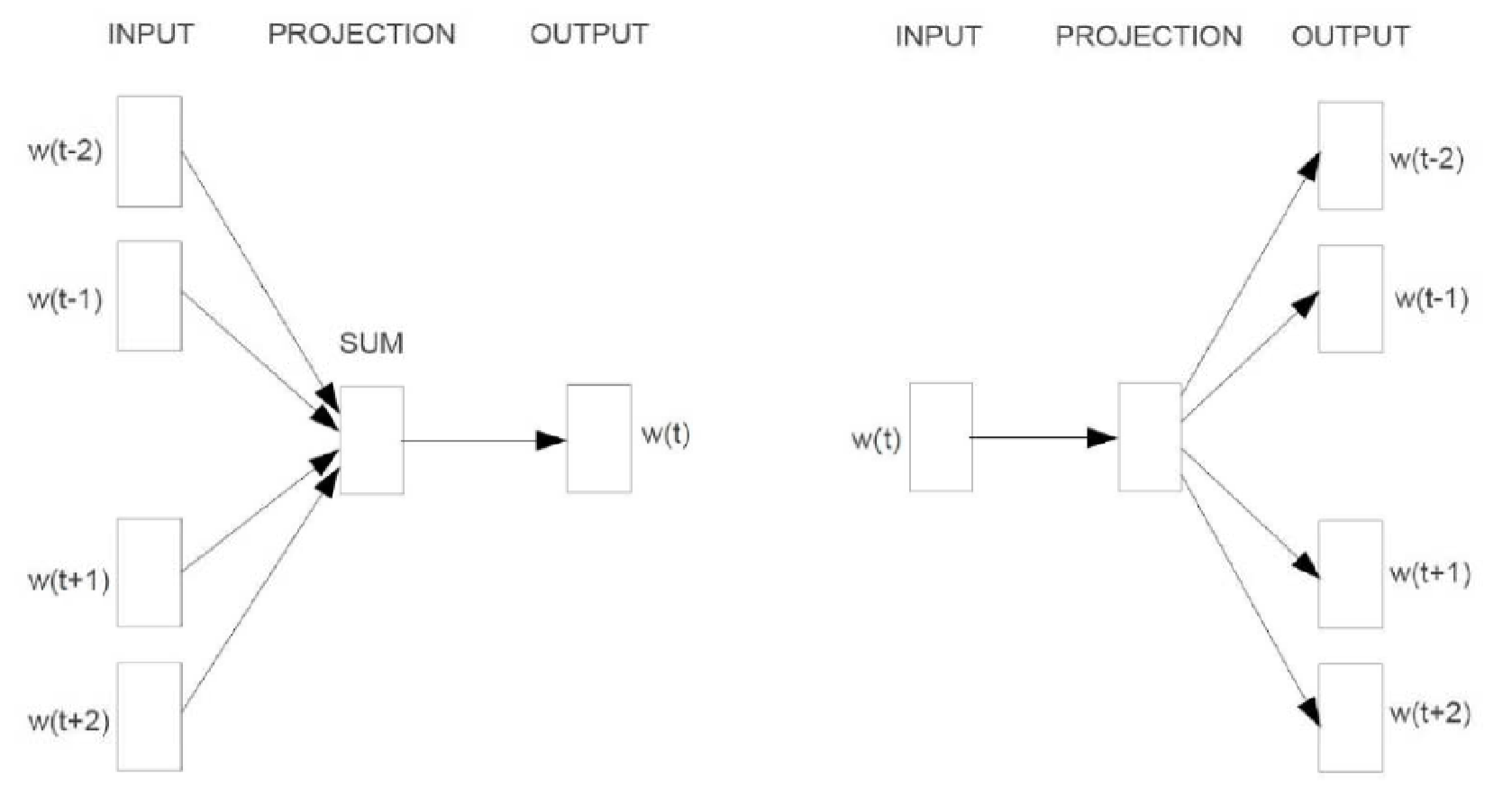
首先来看cbow, 对比NNLM, 可以发现, 其实结构是差不多的,也是三层结构, 只不过, 在第二层中, 序列中的所有词向量不再是首尾顺次相接构成一个大的向量, 而所有向量相加,结果还是一个与每个词向量相同维度的向量。另一个优化即是在预测的方法上, 这个具体在讲实现方式时再说。
然后再看skip-gram, 这个与cbow有点不同, cbow是用(几个)周围词来预测中心词, 而skip-gram则是用中心词来预测周围词。另外,skip-gram严格来说只是两层, 上图其实只为了与cbow的结构类比,skip-gram的第一层与第二层是一样的, 没做任何变化。
实现方式
word2vec的实现方式有两种, 一种是Hierarchical Softmax,另一种是Negative Sampling.
回想word2vec的目的,是找出一种可以表达词与词之间隐含的相互关联的信息的词表示。那如何捕捉这些信息呢? 记得有个人说过:词是没有意义的,除非它在语境之中。 也就是说,我们要找出想要的信息,需要从词及其语境信息中得到。从概率的角度,也就是说我们要建模,使:
\[
\max P(s(w,context(w_t))) \qquad if\quad w ==w_t
\]
或者:
\[
\max \prod_t P(s(w_t, context(w_t)))\qquad w_t \in Corpus
\]
其中\(s(a,b)\) 表示a,b的某各关系函数。
Hierarchical Softmax
这里用到了一个很重要的概念叫Huffman树,以及Huffman编码。
Huffman 树
在数据结构中, 树是一种很重要的非线性数据结构。二叉树又是其中很重要部分。 下面要介绍的Huffman树是所谓的最优二叉树。
这里带着问题,采用一种反向的方式来了解Huffman树。既然Huffman树是所谓的最优二叉树,那么最优体现在哪里呢? 最优的标准:二叉树的带权路径长度最小。 那什么是带权路径呢?
在树结构中, 从(根)节结点到其子孙结点所经过的分支数量称为路径长度;在树中, 为每个结点赋予某种意义的数值, 称为该结点的权重。带权路径长度为某结点的路径长度与其结点的乘积。对于整棵树来说, 带权路径长度为所有结点的带权路径之和。Huffman为在所有可能的建树方案中,带权路径长度最小的那棵树。
Huffman建树过程,首先是以某种标准为每个数据点分配权值,然后,选出两个权值最小的数据点, 权值相加,构成一个新的(虚拟的)数据点,放回到数据集合中, 重复此组合过程,直到最终数据集只剩下一个点,树即建成。
如果每个数据点是一个词, 并且以每个词出现的频率为权值建树,并且在二叉树中,在左分支标记为1,右分支标记为0,最终每个词都可由0,1 二进制数来编码表示,即为Huffman编码。
HS cbow
从cbow 的结构可知, cbow 是在已知语境的情况下来预测中心词, 则上述优化目标可进一步细化:
\[
max \prod_t P(w_t|context(w_t))
\]
在cbow中,\(context(w_t)\) 所有词的词向量加和:
\[
x_t = \sum_i w_i \qquad w_i \in context(w_t)
\]
然后用\(x_t\) 来预测 \(w_t\).
在最后一层,以Huffman编码的形式组织所有词。如下图所示:
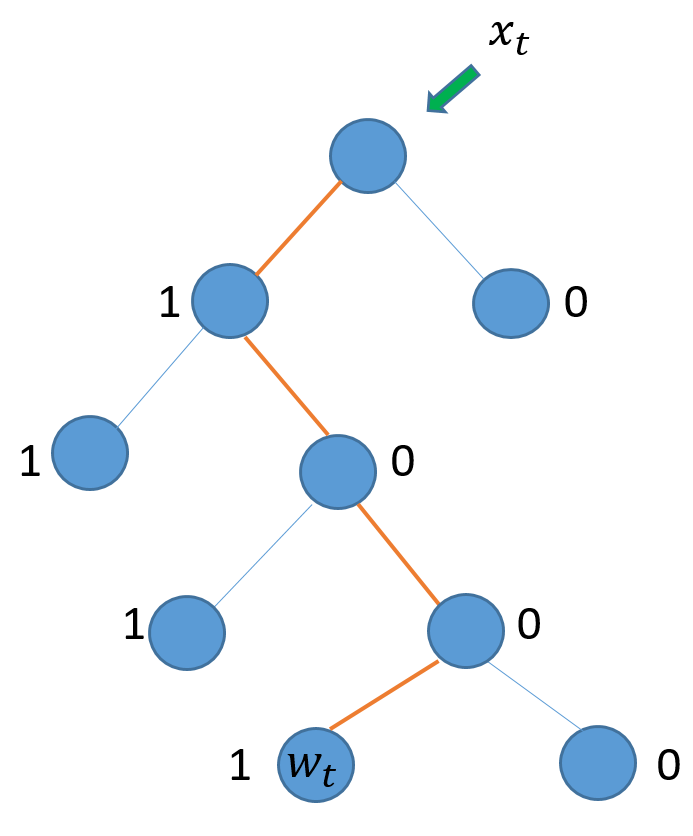
如上图所示, 用\(x_t\) 来预测\(w_t\), 要从根结点经过4个分支到达\(w_t\). 这里因为使用Huffman编码, 原问题的最大化条件概率,转化最大化到达\(w_t\) 路径的概率.
而且可以发现, 在每个结点向下选择分支时, 无非左右两种, 也即左分支(1), 右分支(0). 完全类似于0,1 分类. 二分类, 最常见, 最简单的,可以说是逻辑回归了.
\[
P(y = 1|x) = \sigma(x,\theta) = \frac{1}{1+e^{-wx+b}}
\]
其中, y表示类别, x是数据, w是权重, b是偏置. 也可知道: \(P(y=0|x) = 1 - \sigma(x,\theta)\).
为将上述两个公式合在一起,对于某个结点x:
\[
P(y|x) = \sigma(x,\theta)^{y}(1 - \sigma(x,\theta))^{1-y}
\]
因此, 最大化路径可考虑成一系列二分类的连续决策过程.如上图的\(w_t\) 可如下表示:
\[
P(w_t| context(w_t)) = p(w_t|x_t) = \prod_i^{l_{w_t}} p(y_i|x_t) = \prod_i^{l_{w_t}} \sigma(x_t,\theta_i)^{y_i}(1 - \sigma(x_t,\theta_i)^{1-y_i})
\]
其中\(l_{w_t}\)表示\(w_t\)的路径长度, i 表示到达\(w_t\)路径上面的第 i 个结点(不包括根结点, 但包括\(w_t\)所在结点).
显然上式是一个典型的最大似然函数. 优化方式就很常规了, 取对数,求偏导(对 \(w_t,\theta_i\)).
HS skip-gram
在最后一层的建树逻辑与cbow是一样的, 唯一的不同还是在于 skip-gram应用中心词来预测周围词(语境):
\[
\begin{array}\
P(context(w_t)|w_t) &=& \prod_{w_j \in context(w_t)}P(w_j|w_t)\\&=&\prod_{w_j \in context(x)} \prod_i^{l_{w_j}} p(y_i | w_t) \\&=&\prod_{w_j \in context(x)} \prod_i^{l_{w_j}} \sigma(w_t,\theta_i)^{y_i}(1 - \sigma(w_t,\theta_i)^{1-{y_i}})
\end{array}
\]
一样经典的似然函数.
Negative Sampling
另一种更加高效的方式是NCE(Noise Contrastive Estimation). NCE( GUtmann et al.) 被提出,原是为了估计非正则化的概率分布的. Mnih et al 随后把它应用到神经概率语言模型当中. Mikolov把他引入到word2vec之中. NCE 是以二分类的方式将真实分布与负样本分布区分开从而达到求解真实分布的目的, 逻辑其实是与Hierarchical softmax类似, 都是以二分类的形式替代预测问题. Mikolov 把其简化成Negative sampling的方式. Negative sampling即负采样, 负采样如何采呢? 我们知道词的出现频率一般是不一样的,有些几乎总会出现,而且些词在整个语料库内都不见得出现几次.因此,在考查某一个词(\(w_t\))与其语境之间的关系,其负样本应该是那种经常出现却不在\(w_t\)语境出现的词. 因此从这个逻辑出发, 负采样应该是一个带权采样. 实现方式有多种, Mikolov 选择的是这样的, 上面是基于cbow来介绍的,那么这次就是skip-gram来介绍。
假设对某一词语,负样本集 NEG(w), 可定义如下的示性函数:
\[
L^w(\tilde w) = \left\{\begin{array}\\
1,\quad \tilde w = w;\\
0, \quad \tilde w \ne w,
\end{array}
\right.
\]
其中 \(\tilde w\in NEG(w)\cup w\) , 可知当 \(\tilde w\)等于 w 时, 为1, 当 \(\tilde w\) 属于负样本集时, 为0. 因此,在给定(w, context(w))( context(w)表示w 的语境, 也即其附近词语的集合.) 优化目标为最大化如下:
\[
\arg \max_{V(\tilde w)} g(w) = \prod_{\tilde w\in Context(w)}\prod_{\mu \in \{w\}\cup Neg^{\tilde w}(w)} p(\mu|\tilde w)
\]
其中\(Neg^{\tilde w}(w)\)表示在处理\(\tilde w\)时 生成的负样本集, \(V(\tilde{w})\) 表示 w的向量表示. 另外:
\[
p(\mu|\tilde w) =
\left\{
\begin{array}\\
\sigma(V(\tilde w)^T \theta^\mu), \quad \quad L^w(\mu) = 1;\\
1- \sigma(V(\tilde w)^T \theta^\mu), \quad L^w(\mu) = 0,
\end{array}
\right.
\]
上式可改写为:
\[
p(\mu|\tilde w) =
[\sigma(V(\tilde w)^T \theta^\mu)]^{L^w(\mu)}\cdot [1- \sigma(V(\tilde w)^T \theta^\mu)]^{1 - L^w(\mu)}
\]
其中, \(\theta\) 为一在运算过程中的辅助变量, 我们真正想要的是 \(\tilde w\). 对于整个语料库C:
\[
G = \prod_{w\in C } g(w)
\]
对上式取对数, 并将\(g(w)\) 代入:
\[
\begin{array}\\
\mathscr{L} &=& \log G = \log \prod_{w\in C} = \sum_{w\in C}\log g(w)\\
&=& \sum_{w \in C} \log \prod_{\tilde w\in Context(w)}\prod_{\mu \in \{w\}\cup Neg^{\tilde w}(w)} [\sigma(V(\tilde w)^T \theta^\mu)]^{L^w(\mu)}\cdot \\
&& [1- \sigma(V(\tilde w)^T \theta^\mu)]^{1 - L^w(\mu)}\\
&=& \sum_{w \in C} \sum_{\tilde w\in Context(w)}\sum_{\mu \in \{w\}\cup Neg^{\tilde w}(w)}\\
&& \{L^w (\mu) \cdot \log [\sigma(V(\tilde w)^T \theta^\mu] + [1- L^w (\mu)] \cdot \log [1 - \sigma(V(\tilde w)^T \theta^\mu ]\}
\end{array}
\]
接下来即用其对 \(\tilde w ,\theta\)求偏导了.
\[
\frac{\partial \mathscr L}{\partial \theta^\mu} =\frac{\partial}{\theta^\mu} \{L^w (\mu) \cdot \log [\sigma(V(\tilde w)^T \theta^\mu] + [1- L^w (\mu)] \cdot \log [1 - \sigma(V(\tilde w)^T \theta^\mu ]\}
\]
化简, 于是:
\[
\frac{\partial \mathscr L}{\partial \theta^\mu} = [L^w(\mu) - \sigma(V(\tilde w)^T\theta^\mu)]V(\tilde w)
\]
\[
\theta^\mu = \theta^\mu +\eta [L^w(\mu) - \sigma(V(\tilde w)^T\theta^\mu)]V(\tilde w)
\]
也可知:
\[
V(\tilde w) = V(\tilde w) +\eta \sum_{\mu \in Neg^{\tilde w}(w)\cup \{w\}} [L^w(\mu) - \sigma(V(\tilde w)^T\theta^\mu)]\theta^\mu
\]
上面加和符号是因为\(\mu \in Neg^{\tilde w}(w)\cup \{w\}\).
有了上面的铺垫,cbow也会很容易:
\[
\arg \max_{V(\tilde w)} g(w) = \prod_{\mu \in \{w\}\cup Neg(w)} p(\tilde w|x_t)
\]
同理:
\[
p(\mu|\tilde w) =
[\sigma(x_t^T \theta^\mu)]^{L^w(\mu)}\cdot [1- \sigma(x_t^T \theta^\mu)]^{1 - L^w(\mu)}
\]
代入并写成全语料的形式:
\[
\begin{array}\\
\mathscr{L} &=& \log G =L^w(\mu)\cdot\log\sigma(x_t^T \cdot w) \sum_{\mu \in Neg(w)}(1-L^w(\mu)\log(1 - \sigma(x_t\cdot\mu))
\end{array}
\]
后面的过程如上.
词向量编码 word2vec的更多相关文章
- Google词向量word2vec的使用
""" 1.在自然语言处理中常常使用预训练的word2vec,这个预训练的词向量可以使用google的GoogleNews-vectors-negative300.bin ...
- 词向量word2vec(图学习参考资料)
介绍词向量word2evc概念,及CBOW和Skip-gram的算法实现. 项目链接: https://aistudio.baidu.com/aistudio/projectdetail/500940 ...
- 词向量 word2vec
看的这一篇的笔记 http://licstar.net/archives/328 看不太懂. 要学的话,看这里吧,这里把一些资料做了整合: http://www.cnblogs.com/wuzhitj ...
- 使用word2vec训练中文词向量
https://www.jianshu.com/p/87798bccee48 一.文本处理流程 通常我们文本处理流程如下: 1 对文本数据进行预处理:数据预处理,包括简繁体转换,去除xml符号,将单词 ...
- DL4NLP——词表示模型(二)基于神经网络的模型:NPLM;word2vec(CBOW/Skip-gram)
本文简述了以下内容: 神经概率语言模型NPLM,训练语言模型并同时得到词表示 word2vec:CBOW / Skip-gram,直接以得到词表示为目标的模型 (一)原始CBOW(Continuous ...
- 机器学习入门-文本特征-word2vec词向量模型 1.word2vec(进行word2vec映射编码)2.model.wv['sky']输出这个词的向量映射 3.model.wv.index2vec(输出经过映射的词名称)
函数说明: 1. from gensim.model import word2vec 构建模型 word2vec(corpus_token, size=feature_size, min_count ...
- 词表征 2:word2vec、CBoW、Skip-Gram、Negative Sampling、Hierarchical Softmax
原文地址:https://www.jianshu.com/p/5a896955abf0 2)基于迭代的方法直接学 相较于基于SVD的方法直接捕获所有共现值的做法,基于迭代的方法一次只捕获一个窗口内的词 ...
- word2vec 构建中文词向量
词向量作为文本的基本结构——词的模型,以其优越的性能,受到自然语言处理领域研究人员的青睐.良好的词向量可以达到语义相近的词在词向量空间里聚集在一起,这对后续的文本分类,文本聚类等等操作提供了便利,本文 ...
- 斯坦福NLP课程 | 第1讲 - NLP介绍与词向量初步
作者:韩信子@ShowMeAI,路遥@ShowMeAI,奇异果@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www. ...
随机推荐
- Cocoa 框架 For iOS(一) 框架的介绍,Objectivie-C运行时能力的解析等 (转载)
http://blog.csdn.net/totogo2010/article/details/8081253 Cocoa框架是iOS应用程序的基础,了解Cocoa框架,对开发iOS应用有很大的帮助. ...
- bugfree3.0.1-修改“优先级”“严重等级”为中文
1.进入目录C:\xampp\htdocs\bugfree\protected\models 2.打开文件 Info.php
- 第十二届GOPS全球运维大会2019深圳站即将开幕
第十二届 GOPS 全球运维大会深圳站 会议召开时间:2019年4月12日-13日 会议召开地点:深圳圣淘沙酒店(翡翠店) 会议主办单位:高效运维社区 票务合作伙伴:活动家 会议报名地址:https: ...
- iPhoneX快速适配,简单到你想哭。
研究了5个小时的iPhoneX适配. 从catalog,storyboard,safearea等一系列文章中发现.如果我们想完全撑满全屏.那直接建一个storyboard就好了.但撑满全屏后,流海就是 ...
- C#设计模式(7)——适配器模式(Adapter Pattern)(转)
一.引言 在实际的开发过程中,由于应用环境的变化(例如使用语言的变化),我们需要的实现在新的环境中没有现存对象可以满足,但是其他环境却存在这样现存的对象.那么如果将“将现存的对象”在新的环境中进行调用 ...
- 大数据Spark+Kafka实时数据分析案例
本案例利用Spark+Kafka实时分析男女生每秒购物人数,利用Spark Streaming实时处理用户购物日志,然后利用websocket将数据实时推送给浏览器,最后浏览器将接收到的数据实时展现, ...
- debug调试命令
- js页面路径拼接字符串进行参数传递
页面路径拼接字符串进行参数传递: 参数传递页面: <style> input,button{ border: 1px solid red; } body { font-size:24px; ...
- scrapy item pipeline
item pipeline process_item(self, item, spider) #这个是所有pipeline都必须要有的方法在这个方法下再继续编辑具体怎么处理 另可以添加别的方法 ope ...
- Restful API接口调用的方法总结
restful 接口调用的方法 https://www.cnblogs.com/taozhiye/p/6704659.html http://www.jb51.net/article/120589.h ...