机器学习入门-文本特征-word2vec词向量模型 1.word2vec(进行word2vec映射编码)2.model.wv['sky']输出这个词的向量映射 3.model.wv.index2vec(输出经过映射的词名称)
函数说明:
1. from gensim.model import word2vec 构建模型 word2vec(corpus_token, size=feature_size, min_count=min_count, window=window, sample=sample)
参数说明:corpus_token已经进行切分的列表数据,数据格式是list of list , size表示的是特征向量的维度,即映射的维度, min_count表示最小的计数词,如果小于这个数的词,将不进行统计, window表示滑动窗口,表示滑动窗口的大小,用于构造训练集和测试集, sample表示对出现次数频繁的词进行一个随机下采样
2. model.wv['sky'] 表示输出sky这个词的特征映射结果
3.model.wv.index2words 输出经过映射后的特征名,输出经过映射词的名字
这里简要的说明一下个人的理解
CBOW是word2vec的一种基础模型,他是通过选取一个词前后c个词进行训练
训练数据:一个词的前后2c个词做为训练
标签:当前这个词作为标签值
最后的输出结果是前一个隐含层的输出,即特征的个数,这个的特征是4即存在4个维度值
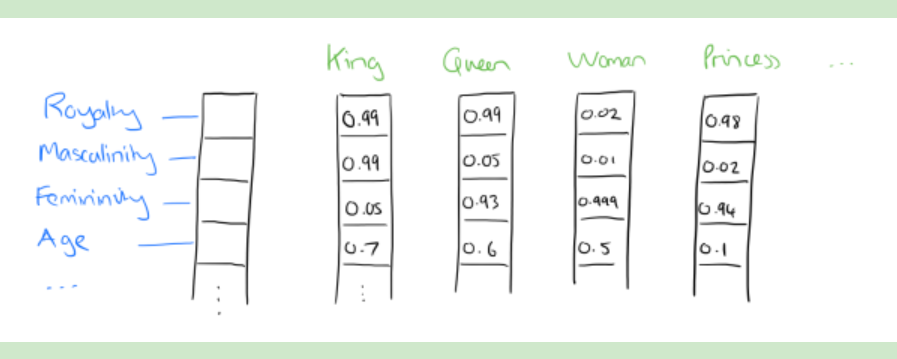
如果对4个特征做降维,降成2维,我们可以发现词义相似的词会被放在相近的位置上
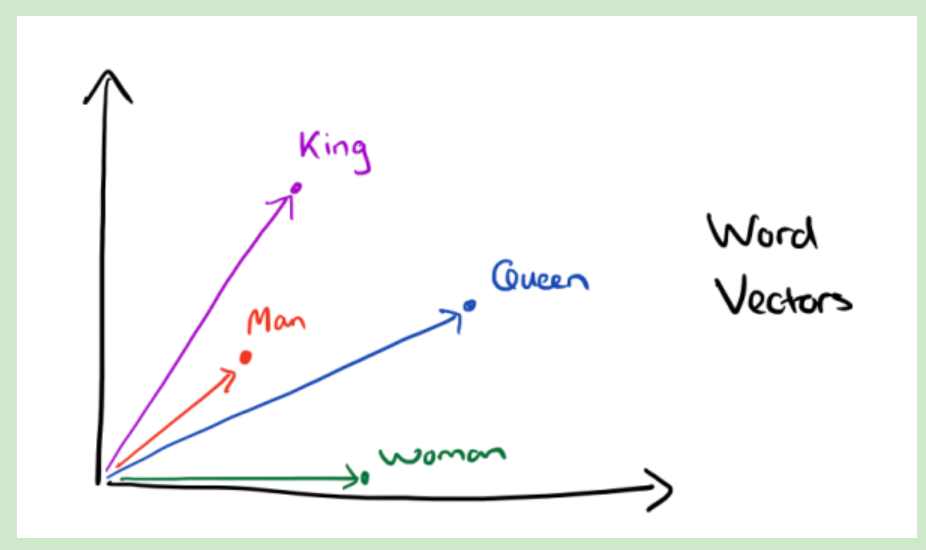
word2vec使用每一个特征向量词的平均用最为最终的特征表示
word2vec主要是构建了霍夫曼树用来取代softmax最后一个神经元的参数跟新
操作过程:
第一步:
首先使用最大似然估计 ∑p = yi*pi + (1-yi) * pi
然后对其根绝∑p/dtheta 进行求导操作, 获得梯度的方向。
第二步:
建立一颗霍夫曼树:每个叶子节点的个数是Xw = 1/2c∑xi 表示这个词左右两边c个词进行加和,xi表示初始值的one-hot编码
通过梯度上升法:来更新thetaj 和 Xw
thetaj = thetaj + a * g * Xw # a表示步长, g表示每个参数的梯度方向, Xw表示当前的值
Xw = 0 + g * thetaj # g表示每个参数的梯度方向, thetaj表示当前的梯度值
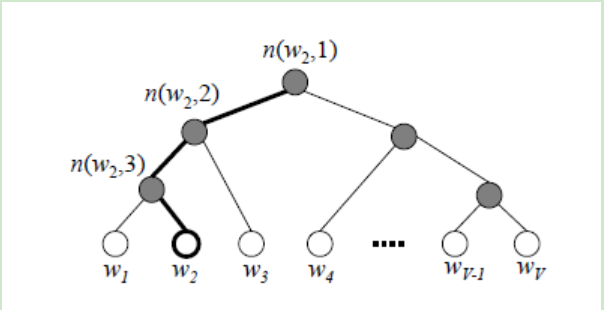
由于左子树的权重值大于右子树,左边的是sigmoid大于0.5的,右边是sigmoid小于0.5的
因此我们很容易找出sigmoid值最大的那个树(感觉有点点不是很理解,这么做的目的)
代码:
第一步:DataFrame化数据
第二步:进行分词和去除停用词,使用' '.join连接列表
第三步:np.vectorize 向量化函数和调用函数进行停用词的去除
第四步:构建gensim.models import word2vec 构造单个词的特征向量,使用model.wv['sky']
第五步:对第三步的字符串进行切分,将切分后的数据送入到word2vec建立模型,使用model.wv.index2word打印出当前的特征名,使用循环找出每个列表中词的特征向量,最后对每个列表中的词做一个特征向量的平均,作为列表的特征向量
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import re corpus = ['The sky is blue and beautiful.',
'Love this blue and beautiful sky!',
'The quick brown fox jumps over the lazy dog.',
'The brown fox is quick and the blue dog is lazy!',
'The sky is very blue and the sky is very beautiful today',
'The dog is lazy but the brown fox is quick!'
] labels = ['weather', 'weather', 'animals', 'animals', 'weather', 'animals'] # 第一步:进行DataFrame化操作 corpus = np.array(corpus)
corpus_df = pd.DataFrame({'Document': corpus, 'category': labels}) # 第二步:进行分词和停用词的去除
import nltk stopwords = nltk.corpus.stopwords.words('english')
wps = nltk.WordPunctTokenizer()
def Normalize_corpus(doc): tokens = re.findall(r'[a-zA-Z0-9]+', doc.lower())
doc = [token for token in tokens if token not in stopwords]
doc = ' '.join(doc)
return doc # 第三步:向量化函数,调用函数进行分词和停用词的去除
Normalize_corpus = np.vectorize(Normalize_corpus)
corpus_array = Normalize_corpus(corpus) # 第四步:对单个词计算word2vec特征向量
from gensim.models import word2vec
corpus_token = [wps.tokenize(corpus) for corpus in corpus_array]
print(corpus_token)
# 特征的维度
feature_size = 10
# 最小的统计个数,小于这个数就不进行统计
min_count = 1
# 滑动窗口
window = 10
# 对出现次数频繁的词进行随机下采样操作
sample = 1e-3
model = word2vec.Word2Vec(corpus_token, size=feature_size, min_count=min_count, window=window, sample=sample)
print(model.wv.index2word) # 第五步:对每一个corpus做平均的word2vec特征向量
def word2vec_corpus(corpuses, num_size=10): corpus_tokens = [wps.tokenize(corpus) for corpus in corpuses]
model = word2vec.Word2Vec(corpus_tokens, size=num_size, min_count=min_count, window=window, sample=sample)
vocabulary = model.wv.index2word
score_list = []
for corpus_token in corpus_tokens:
count_time = 0
score_array = np.zeros([10])
for word in corpus_token:
if word in vocabulary:
count_time += 1
score_array += model.wv[word]
score_array = score_array / count_time
score_list.append(list(score_array)) return score_list print(np.shape(word2vec_corpus(corpus_array, num_size=10)))

部分的特征数据:我们可以看出维度为(6, 10)上述的特征是6个,每个特征的维度为10
机器学习入门-文本特征-word2vec词向量模型 1.word2vec(进行word2vec映射编码)2.model.wv['sky']输出这个词的向量映射 3.model.wv.index2vec(输出经过映射的词名称)的更多相关文章
- 机器学习入门-文本特征-使用LDA主题模型构造标签 1.LatentDirichletAllocation(LDA用于构建主题模型) 2.LDA.components(输出各个词向量的权重值)
函数说明 1.LDA(n_topics, max_iters, random_state) 用于构建LDA主题模型,将文本分成不同的主题 参数说明:n_topics 表示分为多少个主题, max_i ...
- 机器学习入门-文本数据-构造词频词袋模型 1.re.sub(进行字符串的替换) 2.nltk.corpus.stopwords.words(获得停用词表) 3.nltk.WordPunctTokenizer(对字符串进行分词操作) 4.np.vectorize(对函数进行向量化) 5. CountVectorizer(构建词频的词袋模型)
函数说明: 1. re.sub(r'[^a-zA-Z0-9\s]', repl='', sting=string) 用于进行字符串的替换,这里我们用来去除标点符号 参数说明:r'[^a-zA-Z0- ...
- 机器学习入门-贝叶斯构造LDA主题模型,构造word2vec 1.gensim.corpora.Dictionary(构造映射字典) 2.dictionary.doc2vec(做映射) 3.gensim.model.ldamodel.LdaModel(构建主题模型)4lda.print_topics(打印主题).
1.dictionary = gensim.corpora.Dictionary(clean_content) 对输入的列表做一个数字映射字典, 2. corpus = [dictionary,do ...
- 机器学习入门-文本数据-构造Ngram词袋模型 1.CountVectorizer(ngram_range) 构建Ngram词袋模型
函数说明: 1 CountVectorizer(ngram_range=(2, 2)) 进行字符串的前后组合,构造出新的词袋标签 参数说明:ngram_range=(2, 2) 表示选用2个词进行前后 ...
- 机器学习入门-文本数据-构造Tf-idf词袋模型(词频和逆文档频率) 1.TfidfVectorizer(构造tf-idf词袋模型)
TF-idf模型:TF表示的是词频:即这个词在一篇文档中出现的频率 idf表示的是逆文档频率, 即log(文档的个数/1+出现该词的文档个数) 可以看出出现该词的文档个数越小,表示这个词越稀有,在这 ...
- 机器学习入门09 - 特征组合 (Feature Crosses)
原文链接:https://developers.google.com/machine-learning/crash-course/feature-crosses/ 特征组合是指两个或多个特征相乘形成的 ...
- 机器学习入门-数值特征-数字映射和one-hot编码 1.LabelEncoder(进行数据自编码) 2.map(进行字典的数字编码映射) 3.OnehotEncoder(进行one-hot编码) 4.pd.get_dummies(直接对特征进行one-hot编码)
1.LabelEncoder() # 用于构建数字编码 2 .map(dict_map) 根据dict_map字典进行数字编码的映射 3.OnehotEncoder() # 进行one-hot编码 ...
- DL4NLP——词表示模型(三)word2vec(CBOW/Skip-gram)的加速:Hierarchical Softmax与Negative Sampling
上篇博文提到,原始的CBOW / Skip-gram模型虽然去掉了NPLM中的隐藏层从而减少了耗时,但由于输出层仍然是softmax(),所以实际上依然“impractical”.所以接下来就介绍一下 ...
- 机器学习入门-数值特征-对数据进行log变化
对于一些标签和特征来说,分布不一定符合正态分布,而在实际的运算过程中则需要数据能够符合正态分布 因此我们需要对特征进行log变化,使得数据在一定程度上可以符合正态分布 进行log变化,就是对数据使用n ...
随机推荐
- Javascript中的对象(八)
一.如何编写可以计算的对象的属性名 我们都知道对象的属性访问分两种,键访问(["属性名"])和属性访问(.属性名,遵循标识符的命名规范) 对于动态属性名可以这样 var prefi ...
- java高并发编程(二)
马士兵java并发编程的代码,照抄过来,做个记录. 一.分析下面面试题 /** * 曾经的面试题:(淘宝?) * 实现一个容器,提供两个方法,add,size * 写两个线程,线程1添加10个元素到容 ...
- PAT 乙级 1031 查验身份证(15) C++版
1031. 查验身份证(15) 时间限制 200 ms 内存限制 65536 kB 代码长度限制 8000 B 判题程序 Standard 作者 CHEN, Yue 一个合法的身份证号码由17位地区. ...
- Service Mesh简介
1.1 Service Mesh 1.1.1 什么是Service Mesh Service Mesh是最近才兴起的一个名词,最早在2016年9月29日由开发Linkerd的Buoyant公司首次 ...
- [UE4]创建游戏、加入游戏
google搜: UE4 compile dedicated server,编译UE4专用服务器 UE4默认网络端口可以在引擎配置文件中修改: 一.创建文件.需要修改一下工程的配置文件DefaultE ...
- linux下软件安装知识整理
一.软件包安装分类源码包二进制包(RPM包,系统默认包)源码包优点1.开源 可以自由选择所需的功能 软件是编译安装,适合自己系统,更加稳定,效率更高 卸载方便 缺点 安装过程步骤较多,容易 ...
- vue todolist 封装localstorage
//封装操作localstorage本地存储的方法 模块化的文件 // nodejs 基础 var storage={ set(key,value){ localStorage.setItem(key ...
- vue todolist 1.0
<template> <div id="app"> <input type="text" v-model='todo' /> ...
- 2017湖湘杯复赛writeup
2017湖湘杯复赛writeup 队伍名:China H.L.B 队伍同时在打 X-NUCA 和 湖湘杯的比赛,再加上周末周末周末啊,陪女朋友逛街吃饭看电影啊.所以精力有点分散,做出来部分题目,现在 ...
- spring整合mybatis、hibernate、logback配置
Spring整合配置Mybatis 1.配置数据源(连接数据库最基本的属性配置,如数据库url,账号,密码,和数据库驱动等最基本参数配置) <!-- 导入properties配置文件 --> ...