《STL系列》之map原理及实现
上一篇文章《STL系列》之vector原理及实现,介绍了vector的原理及实现,这篇文章介绍map的原理及实现。STL实现源码下载。
STL中map的实现是基于RBTree的,我在实现的时候没有采用RBTree,觉得这东西有点复杂,我的map采用的是排序数组(CSortVector)。map中的Key存在排序数据中,通过二分查找判断某个Key是否在map中,时间复杂度为O(logN)。在用一个CVector存Key和Value,为了方便拿到Key和Value,这里有点冗余,Key被存了两次。
现在先介绍我的CSortVector,先贴出完整的代码,如下:
#ifndef _CSORTVECTOR_H_
#define _CSORTVECTOR_H_ namespace cth
{
template<typename T>
class csortvector:public NoCopy
{
public:
typedef const T* const_iterator;
typedef T* iterator;
csortvector()
{
initData();
} csortvector(int capa,const T& val=T())
{
initData(capa);
newCapacity(capacity_);
for (int i=;i<size_;i++)
buf[i]=val;
} ~csortvector()
{
if (buf)
{
delete[] buf;
buf=NULL;
}
size_=capacity_=;
} int add(const T& t )
{
int index=-;
if (size_==)
{
newCapacity(calculateCapacity());
buf[size_++]=t;
index=;
}else{
int start=;
int end=size_-;
while(start<=end)
{
index=(start+end)/;
if(buf[index]==t)
{
goto SORTVECTOR_INSERT;
}
else if(buf[index]>t)
{
end=index-;
}
else
{
start=index+;
}
} if(buf[index]<t)
{
index++;
}
SORTVECTOR_INSERT:
insert(index,t);
}
return index;
} void insert(int index,const T& t)
{
assert(index>= && index<=size_);
if (size_==capacity_)
{
newCapacity(calculateCapacity());
}
memmove(buf+index+,buf+index,(size_-index)*sizeof(T));
buf[index]=t;
size_++;
} int indexOf(const T& t)
{
int begin=;
int end=size_-;
int index=-;
while (begin<=end)
{
index=begin+(end-begin)/;
if (buf[index]==t)
{
return index;
}else if (buf[index]<t)
{
begin=index+;
}else{
end=index-;
}
}
return -;
} int remove(const T& t)
{
int index=indexOf(t);
if (index>=)
{
memmove(buf+index ,buf+index+,(size_-index)*sizeof(T));
buf[--size_]=T();
}
return index;
} void erase(const_iterator iter)
{
remove(*iter);
} const_iterator begin() const
{
return const_iterator(&buf[]);
}
const_iterator end() const
{
return const_iterator(&buf[size_]);
} const T& operator[](int index) const
{
assert(size_> && index>= && index<size_);
return buf[index];
} void clear()
{
if (buf)
{
for (int i=;i<size_;i++)
{
buf[i]=T();
}
}
size_=capacity_=;
} bool empty() const
{
return size_==;
} int size() const
{
return size_;
} int capacity() const
{
return capacity_;
}
private:
void newCapacity(int capa)
{
assert (capa>size_) ;
capacity_=capa;
T* newBuf=new T[capacity_];
if (buf)
{
memcpy(newBuf,buf,size_*sizeof(T) );
delete [] buf;
}
buf=newBuf;
} inline void initData(int capa)
{
buf=NULL;
size_=capacity_=capa>?capa:;
} inline int calculateCapacity()
{
return capacity_*/+;
}
int size_;
int capacity_ ;
T* buf;
}; } #endif
CSortVector和CVector有点类似,只不过CSortVector中的数据在插入的时候需要排序,其他的接口比较相识。CSortVector的关键实现就是二分查找。新增和删除的时候都是通过二分查找,定位到指定的位置,在进行相关操作。这里有必要特意列出二分查找的实现,如下:
int indexOf(const T& t)
{
int begin=;
int end=size_-;
int index=-;
while (begin<=end)
{
index=begin+(end-begin)/;
if (buf[index]==t)
{
return index;
}else if (buf[index]<t)
{
begin=index+;
}else{
end=index-;
}
}
return -;
}
CSortVector测试代码如下:
void csortvectorTest()
{
csortvector<int> l;
l.add();
l.add();
l.add();
l.add();
l.add();
l.add();
l.add();
l.add();
l.add();
l.add();
cout<<"任意插入一组数据后,自动排序:"<<endl;
for (int i=;i<l.size();i++)
{
cout<<l[i]<<" ";
}
cout<<endl<<endl; l.erase(l.begin());
l.erase(l.end()-);
cout<<"删除第一个和最后一个数:"<<endl;
for (int i=;i<l.size();i++)
{
cout<<l[i]<<" ";
}
cout<<endl<<endl; cout<<"5的下标:"<<l.indexOf()<<endl;
cout<<"下标为3的数:"<<l[]<<endl;
l.remove();
cout<<"删除5以后,5的下标是"<<l.indexOf()<<endl<<endl; cout<<"最后还剩:"<<endl;
for (int i=;i<l.size();i++)
{
cout<<l[i]<<" ";
}
}
运行结果如下:
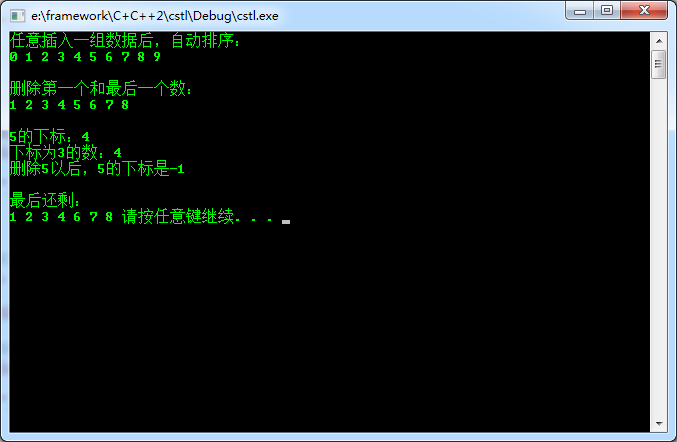
注意:由于CSortVector中的元素要排序,所以其中的元素要实现运算符”<”。
介绍完CSortVector,接下来说说CMap。其实CSortVector已经解决CMap的大部分功能了,后者只需要在前者的基础之上简单的封装即可完事。CMap源码如下:
#ifndef _CMAP_H_
#define _CMAP_H_
#include "csortvector.h"
namespace cth
{
template<typename Key,typename Value>
struct pair
{
typedef Key first_type;
typedef Value second_type;
pair(){}
pair(const Key& key,const Value& val):first(key),second(val){}
pair(const pair& other):first(other.first),second(other.second){}
Key first;
Value second;
}; class NoCopy
{
public:
inline NoCopy(){}
NoCopy(const NoCopy&);
NoCopy& operator=(const NoCopy&);
}; template<typename Key,typename Value>
class cmap:public NoCopy
{
public:
typedef pair<Key,Value>* iterator;
typedef const pair<Key,Value>* const_iterator;
cmap(){}
int insert(const pair<Key,Value>& item)
{
iterator iter=find(item.first);
if (iter!=end())
{
return iter-begin();
}
int index=Keys.add(item.first);
if (index>=)
{
index=Values.insert(Values.begin() + index,item);
}
return index;
} int insert(const Key& key,const Value& val)
{
pair<Key,Value> item;
item.first=key;
item.second=val;
return insert(item);
} Value& operator[](const Key& key)
{
int index=Keys.indexOf(key);
if (index<)
{
index=insert(key,Value());
}
return Values[index].second;
} iterator begin()
{
return iterator(&*Values.begin());
} iterator end()
{
return iterator(&*Values.end());
} iterator find(const Key& key)
{
int index=Keys.indexOf(key);
if (index<)
{
return end();
}else
{
return iterator(&Values[index]);
}
} void erase(const Key& key)
{
int index=Keys.remove(key) ;
if (index>=)
{
cvector<pair<Key,Value>>::iterator iter=Values.begin()+index;
Values.erase(iter);
}
} void erase(const_iterator iter)
{
int index=Keys.remove(iter->first) ;
if (index>=)
{
cvector<pair<Key,Value>>::iterator iter=Values.begin()+index;
Values.erase(iter);
}
} int size()
{
return Keys.size();
} bool empty()
{
return Keys.size()==;
} void clear()
{
Keys.clear();
Values.clear();
} private:
csortvector<Key> Keys;
cvector<pair<Key,Value>> Values;
}; }
#endif
插入操作,CMap的插入操作分两种,一种是通过insert方法;另一种是通过操作符[]。
Insert方法是先找到Key在Keys中的位置,如果已经存在就返回,CMap不允许重复,如果不存在就通过二分查找找到对应的位置,插入Key,并在Values中对应的地方插入Value。
通过操作符[]插入:如m[1]=1;刚开始我也不知道这个是怎么实现的,后来突然明白,操作符[]返回的是一个引用,其实就是给我m[1]的返回值赋值,调用的也是返回值的operator=,CMap只用实现operator[]就行。
其他的方法都是一些简单的封装,这里就不在累赘,最后概述一下CMap的实现:
CMap是基于一个排序数组CSortVector实现的,将Key存入排序数据中,Value和Key通过Pair<Key,Value>存在CVector中,通过二分查找确定某个Key是否存在,不存在就将这个Key插入排序数据中,返回Key在数组中的索引,并将Pair<Key,Value>存在CVector中对应的位置。删除还是通过二分查找寻找,找到就将两个数组中对应的元素删除。
CMap测试代码运行如下:

《STL系列》之map原理及实现的更多相关文章
- STL 中的map 与 hash_map的理解
可以参考侯捷编著的<STL源码剖析> STL 中的map 与 hash_map的理解 1.STL的map底层是用红黑树存储的,查找时间复杂度是log(n)级别: 2.STL的hash_ma ...
- Java 集合系列 15 Map总结
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
- java基础解析系列(七)---ThreadLocal原理分析
java基础解析系列(七)---ThreadLocal原理分析 目录 java基础解析系列(一)---String.StringBuffer.StringBuilder java基础解析系列(二)-- ...
- STL中的map、unordered_map、hash_map
转自https://blog.csdn.net/liumou111/article/details/49252645 在之前使用STL时,经常混淆的几个数据结构,特别是做Leetcode的题目时,对于 ...
- STL中的map和unordered_map
STL中的map和unordered_map map 头文件:#include 原理:std::map的内部实现了一颗红黑树,有对其键值进行排序的功能,所以map是一个有序的容器,map中的每一个元素 ...
- [STL] STL各容器实现原理
STL共有六大组件1.容器 2.算法 3.迭代器 4.仿函数 6.适配器 STL容器的实现原理 STL来管理数据十分方便,省去了我们自己构建数据结构的时间.其实,STL的实现也是基于我们常见的数据结构 ...
- UVa 11991:Easy Problem from Rujia Liu?(STL练习,map+vector)
Easy Problem from Rujia Liu? Though Rujia Liu usually sets hard problems for contests (for example, ...
- Java 集合系列 08 Map架构
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
- java基础解析系列(六)---注解原理及使用
java基础解析系列(六)---注解原理及使用 java基础解析系列(一)---String.StringBuffer.StringBuilder java基础解析系列(二)---Integer缓存及 ...
随机推荐
- 专题:Channel Bonding/bonding
EtherChannel最初是由cisco提出,通过聚合多条物理链路为单条逻辑链路,从而实现高可用及提高吞吐量等目的.AgP(Port Aggregation Protocol,Cisco专有协议). ...
- eclipse 快捷键保存在哪里
eclipse 快捷键文件地址:%Workspace%/.metadata/.plugins/org.eclipse.core.runtime /.settings/org.eclipse.ui.wo ...
- servers中添加server时,看不到运行环境的选择。
servers中添加server时,看不到运行环境的选择. 主要原因是tomcat目录中的配置文件格式不对.
- 字符串复制strncpy
#include "stdafx.h" #include "iostream" #include "assert.h" using name ...
- ubuntu12.04安装svn 1.7(转载)
ubuntu12.04安装svn 1.7 分类: ubuntu2013-10-22 16:03 239人阅读 评论(0) 收藏 举报 svnubuntu 目录(?)[+] 1.问题 在 ...
- 搜索结果高亮显示(不改变html标签)
分类: 代码2010-02-28 13:44 1574人阅读 评论(3) 收藏 举报 htmlinputstring 一.问题的产生 搜索结果高亮显示,在新闻标题,来源之类的地方好做,只需要用st ...
- Java 第二章 变量
第二章 变量 变量称为:是计算机语言中能储存计算机结果或能表示值抽象概念 .变量可以通过变量名访问 int money ; //变量 money=1000; //赋值 int money=1000: ...
- nodejs:使用多处理器
nodejs是单线程,这意味着Node只能利用一个处理器来工作.但多数服务器都有多个核.好在nodejs提供了cluster模块,可以把任务分配给子进程.每个子进程有些特殊能力,比如能与其他子进程共享 ...
- win7连接共享打印机 错误为
1. xp局域网共享打印机,本机运行 –> \\共享电脑ip –> 选择驱动目录 .INF 文件 –> 确认. 直接报错..... 2. 参考方法: 开始——设备和打印机——添 ...
- pictures of you
http://pan.baidu.com/s/1dEAiwnB 给某人的. I've been looking so long at these pictures of you 我已对着你的照片凝视太 ...