Hadoop2.x源码-编译剖析
1.概述
最近,有小伙伴涉及到源码编译。然而,在编译期间也是遇到各种坑,在求助于搜索引擎,技术博客,也是难以解决自身所遇到的问题。笔者在被询问多次的情况下,今天打算为大家来写一篇文章来剖析下编译的细节,以及遇到编译问题后,应该如何去解决这样类似的问题。因为,编译的问题,对于后期业务拓展,二次开发,编译打包是一个基本需要面临的问题。
2.编译准备
在编译源码之前,我们需要准备编译所需要的基本环境。下面给大家列举本次编译的基础环境,如下所示:
- 硬件环境
| 操作系统 | CentOS6.6 |
| CPU |
I7 |
| 内存 | 16G |
| 硬盘 | 闪存 |
| 核数 | 4核 |
- 软件环境
| JDK | 1.7 |
| Maven | 3.2.3 |
| ANT | 1.9.6 |
| Protobuf | 2.5.0 |
在准备好这些环境之后,我们需要去将这些环境安装到操作系统当中。步骤如下:
2.1 基础环境安装
关于JDK,Maven,ANT的安装较为简单,这里就不多做赘述了,将其对应的压缩包解压,然后在/etc/profile文件当中添加对应的路径到PATH中即可。下面笔者给大家介绍安装Protobuf,其安装需要对Protobuf进行编译,故我们需要编译的依赖环境gcc、gcc-c++、cmake、openssl-devel、ncurses-devel,安装命令如下所示:
yum -y install gcc
yum -y install gcc-c++
yum -y install cmake
yum -y install openssl-devel
yum -y install ncurses-devel
验证GCC是否安装成功,命令如下所示:

验证Make核CMake是否安装成功,命令如下所示:
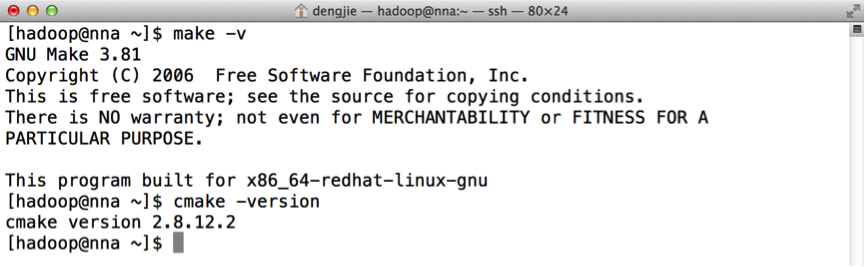
在准备完这些环境之后,开始去编译Protobuf,编译命令如下所示:
[hadoop@nna ~]$ cd protobuf-2.5./
[hadoop@nna protobuf-2.5.]$ ./configure --prefix=/usr/local/protoc
[hadoop@nna protobuf-2.5.]$ make
[hadoop@nna protobuf-2.5.]$ make install
PS:这里安装的时候有可能提示权限不足,若出现该类问题,使用sudo进行安装。
验证Protobuf安装是否成功,命令如下所示:

下面,我们开始进入编译环境,在编译的过程当中会遇到很多问题,大家遇到问题的时候,要认真的去分析这些问题产生的原因,这里先给大家列举一些可以避免的问题,在使用Maven进行编译的时候,若使用默认的JVM参数,在编译到hadoop-hdfs模块的时候,会出现溢出现象。异常信息如下所示:
java.lang.OutOfMemoryError: Java heap space
这里,我们在编译Hadoop源码之前,可以先去环境变量中设置其参数即可,内容修改如下:
export MAVEN_OPTS="-Xms256m -Xmx512m"
接下来,我们进入到Hadoop的源码,这里笔者使用的是Hadoop2.6的源码进行编译,更高版本的源码进行编译,估计会有些许差异,编译命令如下所示:
[hadoop@nna tar]$ cd hadoop-2.6.-src
[hadoop@nna tar]$ mvn package -DskipTests -Pdist,native
PS:这里笔者是直接将其编译为文件夹,若需要编译成tar包,可以在后面加上tar的参数,命令为 mvn package -DskipTests -Pdist,native -Dtar
笔者在编译过程当中,出现过在编译KMS模块时,下载tomcat不完全的问题,Hadoop采用的tomcat是apache-tomcat-6.0.41.tar.gz,若是在此模块下出现异常,可以使用一下命令查看tomcat的文件大小,该文件正常大小为6.9M左右。查看命令如下所示:
[hadoop@nna downloads]$ du -sh *
若出现只有几K的tomcat安装包,表示tomcat下载失败,我们将其手动下载到/home/hadoop/tar/hadoop-2.6.0-src/hadoop-common-project/hadoop-kms/downloads目录下即可。在编译成功后,会出现以下信息:
[INFO] ------------------------------------------------------------------------
[INFO] Reactor Summary:
[INFO]
[INFO] Apache Hadoop Main ................................. SUCCESS [ 1.162 s]
[INFO] Apache Hadoop Project POM .......................... SUCCESS [ 0.690 s]
[INFO] Apache Hadoop Annotations .......................... SUCCESS [ 1.589 s]
[INFO] Apache Hadoop Assemblies ........................... SUCCESS [ 0.164 s]
[INFO] Apache Hadoop Project Dist POM ..................... SUCCESS [ 1.064 s]
[INFO] Apache Hadoop Maven Plugins ........................ SUCCESS [ 2.260 s]
[INFO] Apache Hadoop MiniKDC .............................. SUCCESS [ 1.492 s]
[INFO] Apache Hadoop Auth ................................. SUCCESS [ 2.233 s]
[INFO] Apache Hadoop Auth Examples ........................ SUCCESS [ 2.102 s]
[INFO] Apache Hadoop Common ............................... SUCCESS [: min]
[INFO] Apache Hadoop NFS .................................. SUCCESS [ 3.891 s]
[INFO] Apache Hadoop KMS .................................. SUCCESS [ 5.872 s]
[INFO] Apache Hadoop Common Project ....................... SUCCESS [ 0.019 s]
[INFO] Apache Hadoop HDFS ................................. SUCCESS [: min]
[INFO] Apache Hadoop HttpFS ............................... SUCCESS [: min]
[INFO] Apache Hadoop HDFS BookKeeper Journal .............. SUCCESS [: min]
[INFO] Apache Hadoop HDFS-NFS ............................. SUCCESS [ 2.492 s]
[INFO] Apache Hadoop HDFS Project ......................... SUCCESS [ 0.020 s]
[INFO] hadoop-yarn ........................................ SUCCESS [ 0.018 s]
[INFO] hadoop-yarn-api .................................... SUCCESS [: min]
[INFO] hadoop-yarn-common ................................. SUCCESS [: min]
[INFO] hadoop-yarn-server ................................. SUCCESS [ 0.029 s]
[INFO] hadoop-yarn-server-common .......................... SUCCESS [: min]
[INFO] hadoop-yarn-server-nodemanager ..................... SUCCESS [: min]
[INFO] hadoop-yarn-server-web-proxy ....................... SUCCESS [ 1.810 s]
[INFO] hadoop-yarn-server-applicationhistoryservice ....... SUCCESS [ 4.041 s]
[INFO] hadoop-yarn-server-resourcemanager ................. SUCCESS [ 11.739 s]
[INFO] hadoop-yarn-server-tests ........................... SUCCESS [ 3.332 s]
[INFO] hadoop-yarn-client ................................. SUCCESS [ 4.762 s]
[INFO] hadoop-yarn-applications ........................... SUCCESS [ 0.017 s]
[INFO] hadoop-yarn-applications-distributedshell .......... SUCCESS [ 1.586 s]
[INFO] hadoop-yarn-applications-unmanaged-am-launcher ..... SUCCESS [ 1.233 s]
[INFO] hadoop-yarn-site ................................... SUCCESS [ 0.018 s]
[INFO] hadoop-yarn-registry ............................... SUCCESS [ 3.270 s]
[INFO] hadoop-yarn-project ................................ SUCCESS [ 2.164 s]
[INFO] hadoop-mapreduce-client ............................ SUCCESS [ 0.032 s]
[INFO] hadoop-mapreduce-client-core ....................... SUCCESS [ 13.047 s]
[INFO] hadoop-mapreduce-client-common ..................... SUCCESS [ 10.890 s]
[INFO] hadoop-mapreduce-client-shuffle .................... SUCCESS [ 2.534 s]
[INFO] hadoop-mapreduce-client-app ........................ SUCCESS [ 6.429 s]
[INFO] hadoop-mapreduce-client-hs ......................... SUCCESS [ 4.866 s]
[INFO] hadoop-mapreduce-client-jobclient .................. SUCCESS [: min]
[INFO] hadoop-mapreduce-client-hs-plugins ................. SUCCESS [ 1.183 s]
[INFO] Apache Hadoop MapReduce Examples ................... SUCCESS [ 3.655 s]
[INFO] hadoop-mapreduce ................................... SUCCESS [ 1.775 s]
[INFO] Apache Hadoop MapReduce Streaming .................. SUCCESS [ 11.478 s]
[INFO] Apache Hadoop Distributed Copy ..................... SUCCESS [ 15.399 s]
[INFO] Apache Hadoop Archives ............................. SUCCESS [ 1.359 s]
[INFO] Apache Hadoop Rumen ................................ SUCCESS [ 3.736 s]
[INFO] Apache Hadoop Gridmix .............................. SUCCESS [ 2.822 s]
[INFO] Apache Hadoop Data Join ............................ SUCCESS [ 1.791 s]
[INFO] Apache Hadoop Ant Tasks ............................ SUCCESS [ 1.350 s]
[INFO] Apache Hadoop Extras ............................... SUCCESS [ 1.858 s]
[INFO] Apache Hadoop Pipes ................................ SUCCESS [ 5.805 s]
[INFO] Apache Hadoop OpenStack support .................... SUCCESS [ 3.061 s]
[INFO] Apache Hadoop Amazon Web Services support .......... SUCCESS [: min]
[INFO] Apache Hadoop Client ............................... SUCCESS [ 2.986 s]
[INFO] Apache Hadoop Mini-Cluster ......................... SUCCESS [ 0.053 s]
[INFO] Apache Hadoop Scheduler Load Simulator ............. SUCCESS [ 2.917 s]
[INFO] Apache Hadoop Tools Dist ........................... SUCCESS [ 5.702 s]
[INFO] Apache Hadoop Tools ................................ SUCCESS [ 0.015 s]
[INFO] Apache Hadoop Distribution ......................... SUCCESS [ 8.587 s]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: : min
[INFO] Finished at: --22T15::+:
[INFO] Final Memory: 89M/451M
[INFO] ------------------------------------------------------------------------
在编译完成之后,会在Hadoop源码的dist目录下生成编译好的文件,如下图所示:
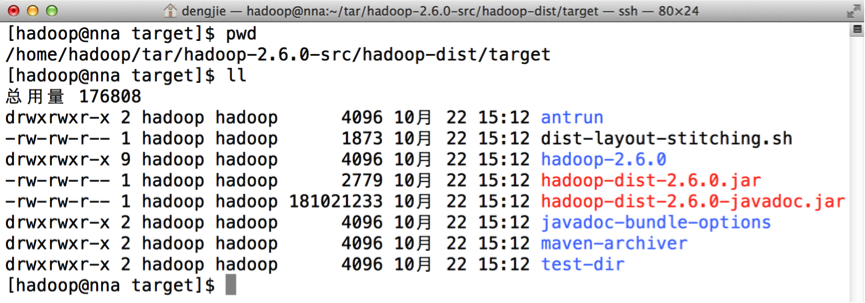
图中hadoop-2.6.0即表示编译好的文件。
3.总结
在编译的过程当中,会出现各种各样的问题,有些问题可以借助搜索引擎去帮助我们解决,有些问题搜索引擎却难以直接的给出解决方案,这时,我们需要冷静的分析编译错误信息,大胆的去猜测,然后去求证我们的想法。简而言之,解决问题的方法是有很多的。当然,大家也可以在把遇到的编译问题,贴在评论下方,供后来者参考或借鉴。
4.结束语
这篇文章就和大家分享到这里,如果大家在研究和学习的过程中有什么疑问,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
Hadoop2.x源码-编译剖析的更多相关文章
- hadoop2.x源码编译
转载请标明出处: http://blog.csdn.net/zwto1/article/details/50733753: 介绍 本篇主要会涉及以下内容: 学会编译hadoop2.x源码 编译hado ...
- Hadoop源码编译过程
一. 为什么要编译Hadoop源码 Hadoop是使用Java语言开发的,但是有一些需求和操作并不适合使用java,所以就引入了本地库(Native Libraries)的概念,通 ...
- hadoop-2.0.0-mr1-cdh4.2.0源码编译总结
准备编译hadoop-2.0.0-mr1-cdh4.2.0的同学们要谨慎了.首先看一下这篇文章: Hadoop作业提交多种方案 http://www.blogjava.net/dragonHadoop ...
- hadoop-2.0.0-cdh4.2.1源码编译总结
经过一个星期多的努力,这两个包的编译工作总算告一段落. 首先看一下这一篇文章: 在eclipse下编译hadoop2.0源码 http://www.cnblogs.com/meibenjin/arch ...
- hadoop2.0 eclipse 源码编译
在eclipse下编译hadoop2.0源码 http://www.cnblogs.com/meibenjin/archive/2013/07/05/3172889.html hadoop cdh4编 ...
- hadoop-2.6.0源码编译问题汇总
在上一篇文章中,介绍了hadoop-2.6.0源码编译的一般流程,因个人计算机环境的不同, 编译过程中难免会出现一些错误,下面是我编译过程中遇到的错误. 列举出来并附上我解决此错误的方法,希望对大家有 ...
- 解决Tomcat10.0.12源码编译问题进而剖析其优秀分层设计架构
概述 Tomcat.Jetty.Undertow这几个都是非常有名实现Servlet规范的应用服务器,Tomcat本身也是业界上非常优秀的中间件,简单可将Tomcat看成是一个Http服务器+Serv ...
- Hadoop2.7.2源码编译过程
目录 准备工作 jar包安装 源码编译 准备工作 CentOS可以联网,验证:ping www.baidu.com 是畅通的 jar 包准备(hadoop 源码.JDK8.maven.ant .pro ...
- 从零教你如何获取hadoop2.4源码并使用eclipse关联hadoop2.4源码
从零教你如何获取hadoop2.4源码并使用eclipse关联hadoop2.4源码http://www.aboutyun.com/thread-8211-1-1.html(出处: about云开发) ...
随机推荐
- Android--Notification
1.通知(Notification)是应用程序没有运行在前台时可以向用户发出一些提示消息的功能,发出通知后,手机状态栏会显示通知,用户可以通过下拉状态栏来查看和操作通知: 2.Notification ...
- ORGANIZATION
Leader: Ming Xiang Ph.D students: Bo Yang Yupei Zhang M.Eng. students: Cheng Feng Jinquan Du Youli ...
- 《Linux内核设计与实现》读书笔记(二十)- 补丁, 开发和社区
linux最吸引我的地方之一就是它拥有一个高手云集的社区, 还有就是如果能=为linux内核中贡献代码, 一定是一件令人自豪的事情. 下面主要总结一些和贡献代码相关的主要内容. 加入社区 编码风格 提 ...
- signalR制作微信墙 开源
微信墙 上一篇文章中已经用PHP搭建了一个微信墙获取信息的服务器,我这里使用微软的signalr搭建一个客户端,signalr是一个为开发者开发实时应用的 一个库文件,支持windows server ...
- TypeScript开发手册
返回TS学习总目录 基本类型(Basic Types) 接口(Interfaces) 类(Classes) 模块(Modules) 函数(Functions) 泛型(Generics) 常见错误(Co ...
- Kindle 转换器
一款比较好用的Kindle转换器,支持txt, opf, htm, html, epub 到 mobi 的转换,支持拖放操作,支持批量操作.只需要选中多个待转换的文件,拖放到程序窗口即可. 曾经用过一 ...
- jQuery的XX如何实现?——1.框架
源码链接:内附实例代码 jQuery使用许久了,但是有一些API的实现实在想不通.于是抽空看了jQuery源码,现在把学习过程中发现的一些彩蛋介绍给大家(⊙0⊙). 下面将使用简化的代码来介绍,主要关 ...
- ubuntu安装redis
1.下载安装root@21ebdf03a086:/# apt-cache search redisroot@21ebdf03a086:/# apt-get install redis-server a ...
- ie下不显示图片
IE支持的图片是必须为RGB三原色的,保存图片时,必须“另存为web可用的格式...”
- [jQuery学习系列一]1-选择器与DOM对象
前言: 好久没有更新博客了, 最近想复习下 之前学过的JS的相关内容, 也算是自己的一种总结. 知识长时间不用就会忘记, 多学多记多用!! 下面的程序都可以在下面的网站进行在线调试: http://w ...