大数据入门第二十一天——scala入门(一)并发编程Actor
注:我们现在学的Scala Actor是scala 2.10.x版本及以前版本的Actor。
Scala在2.11.x版本中将Akka加入其中,作为其默认的Actor,老版本的Actor已经废弃
一、概述
1.什么是actor
Scala的Actor类似于Java中的多线程编程。但是不同的是,Scala的Actor提供的模型与多线程有所不同。Scala的Actor尽可能地避免锁和共享状态,从而避免多线程并发时出现资源争用的情况,进而提升多线程编程的性能。此外,Scala Actor的这种模型还可以避免死锁等一系列传统多线程编程的问题。 Spark中使用的分布式多线程框架,是Akka。Akka也实现了类似Scala Actor的模型,其核心概念同样也是Actor
2.scala与传统Java多线程编程
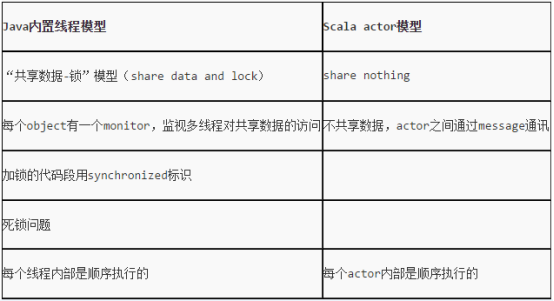
对于Java,我们都知道它的多线程实现需要对共享资源(变量、对象等)使用synchronized 关键字进行代码块同步、对象锁互斥等等。而且,常常一大块的try…catch语句块中加上wait方法、notify方法、notifyAll方法是让人很头疼的。原因就在于Java中多数使用的是可变状态的对象资源,对这些资源进行共享来实现多线程编程的话,控制好资源竞争与防止对象状态被意外修改是非常重要的,而对象状态的不变性也是较难以保证的。
而在Scala中,我们可以通过复制不可变状态的资源(即对象,Scala中一切都是对象,连函数、方法也是)的一个副本,再基于Actor的消息发送、接收机制进行并行编程。
3.actor方法执行顺序
1.首先调用start()方法启动Actor
2.调用start()方法后其act()方法会被执行
3.向Actor发送消息
4.发送消息的方法
|
! |
发送异步消息,没有返回值。 |
|
!? |
发送同步消息,等待返回值。 |
|
!! |
发送异步消息,返回值是 Future[Any]。 |
二、Actor实战
1.快速入门示例
Scala提供了Actor trait来让我们更方便地进行actor多线程编程,就Actor trait就类似于Java中的Thread和Runnable一样,
是基础的多线程基类和接口。我们只要重写Actor trait的act方法,即可实现自己的线程执行体,与Java中重写run方法类似。
此外,使用start()方法启动actor;使用!符号,向actor发送消息;actor内部使用receive和模式匹配接收消息
package com.jiangbei
// 注意这里是2.10版本的Actor所在的包,后续新版本已经废弃,转为Akka
import scala.actors.Actor object ActorTest {
def main(args: Array[String]): Unit = {
println("线程 启动!")
MyActor1.start()
MyActor2.start()
}
} object MyActor1 extends Actor {
override def act(): Unit = {
for (i <- 11 to 19) {
println("actor01---" + i)
Thread.sleep(500)
}
}
} object MyActor2 extends Actor {
override def act(): Unit = {
for (i <- 21 to 29) {
println("actor02---" + i)
Thread.sleep(500)
}
}
}
说明:上面分别调用了两个单例对象的start()方法,他们的act()方法会被执行,相同与在java中开启了两个线程,线程的run()方法会被执行
注意:这两个Actor是并行执行的,act()方法中的for循环执行完成后actor程序就退出了
2.可以不断地接收消息
package com.jiangbei
import scala.actors.Actor
object ActorTest {
def main(args: Array[String]): Unit = {
println("线程 启动!")
val actor1 = new MyActor1
actor1.start()
// 以下为异步消息,不等待返回
actor1 ! "start"
actor1 ! "stop"
println("消息发送完毕!")
}
}
class MyActor1 extends Actor {
override def act(): Unit = {
while (true) { //以下就是偏函数
receive {
case "start" => {
println("启动中...")
Thread.sleep(500)
println("启动完成!")
}
case "stop" => {
println("停止中...")
Thread.sleep(500)
println("停止完成!")
}
}
}
}
}
结果:
线程 启动!
消息发送完毕!
启动中...
启动完成!
停止中...
停止完成!
3.react方式会复用线程,比receive更高效
package com.jiangbei
import scala.actors.Actor
object ActorTest {
def main(args: Array[String]): Unit = {
println("线程 启动!")
val actor1 = new MyActor1
actor1.start()
// 以下为异步消息,不等待返回
actor1 ! "start"
actor1 ! "stop"
println("消息发送完毕!")
}
}
class MyActor1 extends Actor {
override def act(): Unit = {
loop {
react {
case "start" => {
println("starting ...")
Thread.sleep(1000)
println("started")
}
case "stop" => {
println("stopping ...")
Thread.sleep(1000)
println("stopped ...")
}
}
}
}
}
4.结合case class发送消息
package cn.itcast.actor
import scala.actors.Actor class AppleActor extends Actor { def act(): Unit = {
while (true) {
receive {
case "start" => println("starting ...")
case SyncMsg(id, msg) => {
println(id + ",sync " + msg)
Thread.sleep(5000)
sender ! ReplyMsg(3,"finished")
}
case AsyncMsg(id, msg) => {
println(id + ",async " + msg)
Thread.sleep(5000)
}
}
}
}
} object AppleActor {
def main(args: Array[String]) {
val a = new AppleActor
a.start()
//异步消息
a ! AsyncMsg(1, "hello actor")
println("异步消息发送完成")
//同步消息
//val content = a.!?(1000, SyncMsg(2, "hello actor"))
//println(content)
val reply = a !! SyncMsg(2, "hello actor")
println(reply.isSet)
//println("123")
val c = reply.apply()
println(reply.isSet)
println(c)
}
}
case class SyncMsg(id : Int, msg: String)
case class AsyncMsg(id : Int, msg: String)
case class ReplyMsg(id : Int, msg: String)
5.练习:actor版wordCount
package cn.itcast.actor
import java.io.File
import scala.actors.{Actor, Future}
import scala.collection.mutable
import scala.io.Source
/**
* Created by ZX on 2016/4/4.
*/
class Task extends Actor {
override def act(): Unit = {
loop {
react {
case SubmitTask(fileName) => {
val contents = Source.fromFile(new File(fileName)).mkString
val arr = contents.split("\r\n")
val result = arr.flatMap(_.split(" ")).map((_, 1)).groupBy(_._1).mapValues(_.length)
//val result = arr.flatMap(_.split(" ")).map((_, 1)).groupBy(_._1).mapValues(_.foldLeft(0)(_ + _._2))
sender ! ResultTask(result)
}
case StopTask => {
exit()
}
}
}
}
}
object WorkCount {
def main(args: Array[String]) {
val files = Array("c://words.txt", "c://words.log")
val replaySet = new mutable.HashSet[Future[Any]]
val resultList = new mutable.ListBuffer[ResultTask]
for(f <- files) {
val t = new Task
val replay = t.start() !! SubmitTask(f)
replaySet += replay
}
while(replaySet.size > 0){
val toCumpute = replaySet.filter(_.isSet)
for(r <- toCumpute){
val result = r.apply()
resultList += result.asInstanceOf[ResultTask]
replaySet.remove(r)
}
Thread.sleep(100)
}
val finalResult = resultList.map(_.result).flatten.groupBy(_._1).mapValues(x => x.foldLeft(0)(_ + _._2))
println(finalResult)
}
}
case class SubmitTask(fileName: String)
case object StopTask
case class ResultTask(result: Map[String, Int])
大数据入门第二十一天——scala入门(一)并发编程Actor的更多相关文章
- 大数据入门第二十一天——scala入门(二)并发编程Akka
一.概述 1.什么是akka Akka基于Actor模型,提供了一个用于构建可扩展的(Scalable).弹性的(Resilient).快速响应的(Responsive)应用程序的平台. 更多入门的基 ...
- 大数据入门第二十天——scala入门(一)入门与配置
一.概述 1.什么是scala Scala是一种多范式的编程语言,其设计的初衷是要集成面向对象编程和函数式编程的各种特性.Scala运行于Java平台(Java虚拟机),并兼容现有的Java程序. ...
- 大数据入门第二十天——scala入门(二)scala基础01
一.基础语法 1.变量类型 // 上表中列出的数据类型都是对象,也就是说scala没有java中的原生类型.在scala是可以对数字等基础类型调用方法的. 2.变量声明——能用val的尽量使用val! ...
- 大数据入门第二十天——scala入门(二)scala基础02
一. 类.对象.继承.特质 1.类 Scala的类与Java.C++的类比起来更简洁 定义: package com.jiangbei //在Scala中,类并不用声明为public. //Scala ...
- 大数据入门第十二天——sqoop入门
一.概述 1.sqoop是什么 从其官网:http://sqoop.apache.org/ Apache Sqoop(TM) is a tool designed for efficiently tr ...
- 大数据入门第十二天——azkaban入门
一.概述 1.azkaban是什么 通过官方文档:https://azkaban.github.io/ Azkaban is a batch workflow job scheduler create ...
- 大数据入门第十二天——flume入门
一.概述 1.什么是flume 官网的介绍:http://flume.apache.org/ Flume is a distributed, reliable, and available servi ...
- 大数据入门第十九天——推荐系统与mahout(一)入门与概述
一.推荐系统概述 为了解决信息过载和用户无明确需求的问题,找到用户感兴趣的物品,才有了个性化推荐系统.其实,解决信息过载的问题,代表性的解决方案是分类目录和搜索引擎,如hao123,电商首页的分类目录 ...
- 大数据入门第十七天——storm上游数据源 之kafka详解(一)入门与集群安装
一.概述 1.kafka是什么 根据标题可以有个概念:kafka是storm的上游数据源之一,也是一对经典的组合,就像郭德纲和于谦 根据官网:http://kafka.apache.org/intro ...
随机推荐
- 纯小白入手 vue3.0 CLI - 2.5 - 了解组件的三维
vue3.0 CLI 真小白一步一步入手全教程系列:https://www.cnblogs.com/ndos/category/1295752.html 我的 github 地址 - vue3.0St ...
- error C2998:不能是模板定义的错误解决
作者:朱金灿 来源:http://blog.csdn.net/clever101 在一个非模板类中定义了一个模板函数,如下: template<typename T> bool HDF5_ ...
- Python 基于Python实现邮件发送
基于Python实现邮件发送 by:授客 QQ:1033553122 测试环境: Python版本:Python 2.7 注:需要修改mimetypes.py文件(该文件可通过文章底部的网盘分 ...
- phar 反序列化学习
前言 phar 是 php 支持的一种伪协议, 在一些文件处理函数的路径参数中使用的话就会触发反序列操作. 利用条件 phar 文件要能够上传到服务器端. 要有可用的魔术方法作为"跳板&qu ...
- Expo大作战(二十五)--expo sdk api之Admob
简要:本系列文章讲会对expo进行全面的介绍,本人从2017年6月份接触expo以来,对expo的研究断断续续,一路走来将近10个月,废话不多说,接下来你看到内容,讲全部来与官网 我猜去全部机翻+个人 ...
- MySQL——索引实现原理
在MySQL中,索引属于存储引擎级别的概念,不同存储引擎对索引的实现方式是不同的,本文主要讨论MyISAM和InnoDB两个存储引擎的索引实现方式. MyISAM索引实现 MyISAM引擎使用B+Tr ...
- 学习vue.js的正确姿势(转载)
最近饶有兴致的又把最新版 Vue.js 的源码学习了一下,觉得真心不错,个人觉得 Vue.js 的代码非常之优雅而且精辟,作者本身可能无 (bu) 意 (xie) 提及这些.那么,就让我来吧:) 程序 ...
- LeetCode题解之N-ary Tree Postorder Traversal
1.题目描述 2.问题分析 递归. 3.代码 vector<int> postorder(Node* root) { vector<int> v; postNorder(roo ...
- LeetCode题解之Insertion Sort List
1.题目描述 2.题目分析 利用插入排序的算法即可.注意操作指针. 3.代码 ListNode* insertionSortList(ListNode* head) { if (head == NUL ...
- JAVA JComboBox的监听事件(ActionListener、ItemListener)
版权声明:本文为博主原创文章,未经博主允许不得转载. 目录(?)[+] 参考资料: http://263229365.iteye.com/blog/1040329 https://www.ja ...