爬虫--Scrapy-CrawlSpider&基于CrawlSpide的分布式爬虫
CrawlSpider
提问:如果想要通过爬虫程序去爬取”糗百“全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬取进行实现(Request模块递归回调parse方法)。 方法二:基于CrawlSpider的自动爬取进行实现(更加简洁和高效)。 全栈120页数据

---------------------------------------------------------------------------
CrawlSpider:
问题:如果我们想要对某一个网站的全站数据进行爬取?
解决方案:
1. 手动请求的发送
2. CrawlSpider(推荐)

之前的事基于Spider类
CrawlSpider概念:CrawlSpider其实就是Spider的一个子类。CrawlSpider功能更加强大(链接提取器,规则解析器)。 代码:
1. 创建一个基于CrawlSpider的爬虫文件
a) scrapy genspider –t crawl 爬虫名称 起始url
-------
创建工程scrapy startproject crawlSpiderPro
cd crawlSpiderPro
创建爬虫文件 scrapy genspider -t crawl chouti dig.chouti.com
基于scrapySpider爬虫文件的和基于spider的不同之处
爬虫文件chouti.py
区别:
class ChoutiSpider(CrawlSpider):
name = 'chouti'
#allowed_domains = ['dig.chouti.com']
start_urls = ['https://dig.chouti.com/'] #实例化了一个链接提取器对象
#链接提取器:用来提取指定的链接(url)
#allow参数:赋值一个正则表达式
#链接提取器就可以根据正则表达式在页面中提取指定的链接
#提取到的链接会全部交给规则解析器
link = LinkExtractor(allow=r'/all/hot/recent/\d+')
rules = (
#实例化了一个规则解析器对象
#规则解析器接受了链接提取器发送的链接后,就会对这些链接发起请求,获取链接对应的页面内容,就会根据指定的规则对页面内容中指定的数据值进行解析
#callback:指定一个解析规则(方法/函数)
#follow:是否将链接提取器继续作用到连接提取器提取出的链接所表示的页面数据中
Rule(link, callback='parse_item', follow=),
) def parse_item(self, response):
print(response) # 对应的编写response.xpath()---存到items ----将items传给管道---在管道进行持久化存储
# follow=True 所有的页面数据



link = LinkExtractor(allow=r'/all/hot/recent/\d+')
---------------------------------------------
Rule(link, callback='parse_item', follow=True),

分布式爬虫
分布式爬虫:
1. 概念:多台机器上可以执行同一个爬虫程序,实现网站数据的分布爬取。
2. 原生的scrapy是不可以实现分布式爬虫?
a) 调度器无法共享
b) 管道无法共享
3. scrapy-redis组件:专门为scrapy开发的一套组件。该组件可以让scrapy实现分布式。
a) 下载:pip install scrapy-redis
4. 分布式爬取的流程:
a) redis配置文件的配置:
i. bind 127.0.0.1 进行注释
ii. protected-mode no 关闭保护模式
b) redis服务器的开启:基于配置配置文件
c) 创建scrapy工程后,创建基于crawlSpider的爬虫文件 d) 导入RedisCrawlSpider类,然后将爬虫文件修改成基于该类的源文件
e) 将start_url修改成redis_key = ‘XXX’
f) 在配置文件中进行相应配置:将管道配置成scrapy-redis集成的管道
g) 在配置文件中将调度器切换成scrapy-redis集成好的调度器
h) 执行爬虫程序:scrapy runspider xxx.py
i) redis客户端:lpush 调度器队列的名称 “起始url”
-------------------------
分布式爬虫:
1. 概念:多台机器上可以执行同一个爬虫程序,实现网站数据的分布爬取。
2. 原生的scrapy是不可以实现分布式爬虫?
a) 调度器无法共享
b) 管道无法共享
3. scrapy-redis组件:专门为scrapy开发的一套组件。该组件可以让scrapy实现分布式。
a) 下载:pip install scrapy-redis
4. 分布式爬取的流程: 下载redis----我用的是windows版本的
在redis数据库所在文件进行配置
a) redis配置文件的配置:
i. bind 127.0.0.1 进行注释
ii. protected-mode no 关闭保护模式

b) redis服务器的开启:基于配置配置文件----


c) 创建scrapy工程后,创建基于crawlSpider的爬虫文件

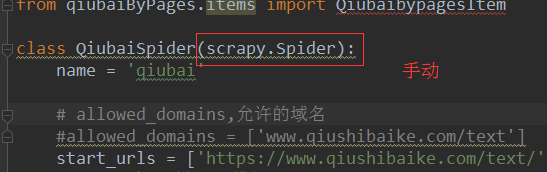
d) 导入RedisCrawlSpider类,然后将爬虫文件修改成基于该类的源文件
from scrapy_redis.spiders import RedisCrawlSpider
class QiubaiSpider(RedisCrawlSpider):
e) 将start_url修改成redis_key = ‘XXX’
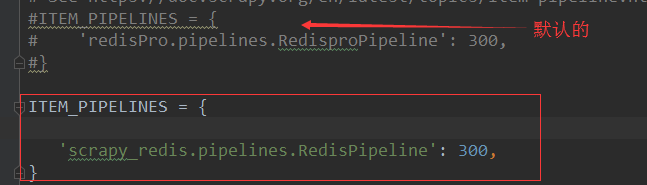
f) 在配置文件中进行相应配置:将管道配置成scrapy-redis集成的管道
默认的为:
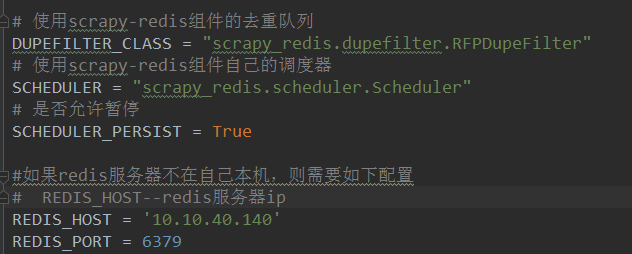
g) 在配置文件中将调度器切换成scrapy-redis集成好的调度器
在settings.py粘贴如下配置
调度器:、
h) 执行爬虫程序:scrapy runspider xxx.py
不同之处是要cd 到爬虫文件

i)
起始url:
https://www.qiushibaike.com/pic/

【补充】
#如果redis服务器不在自己本机,则需要在setting中进行如下配置
REDIS_HOST = 'redis服务的ip地址'
REDIS_PORT = 6379 【注意】近期糗事百科更新了糗图板块的反爬机制,更新后该板块的页码链接/pic/page/2/s=5135066,末尾的数字每次页面刷新都会变化,
因此爬虫文件中链接提取器的正则不可写为/pic/page/\d+/s=5135066而应该修改成/pic/page/\d+
分布式爬虫代码:

qiubai.py
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from redisPro.items import RedisproItem
from scrapy_redis.spiders import RedisCrawlSpider
class QiubaiSpider(RedisCrawlSpider):#继承的类不同,功能也就不一样
name = 'qiubai'
#allowed_domains = ['www.qiushibaike.com/pic']
#start_urls = ['http://www.qiushibaike.com/pic/']
# 调度器队列的名称
redis_key = 'qiubaispider' # 表示跟start_urls含义是一样 rules = (
Rule(LinkExtractor(allow=r'/pic/page/\d+'), callback='parse_item', follow=True),
)
# img src //pic.qiushibaike.com/system/pictures/12133/121333058/medium/8ULD8612VVF6T0NR.jpg
def parse_item(self, response):
div_list = response.xpath('//*[@id="content-left"]/div')
for div in div_list:
# 相对于div_list .// img_url
img_url = div.xpath('./div[@class="thumb"]/a/img/@src').extract_first() # 在items.py中声明 ---导入items
# 实例化items对象
item = RedisproItem()
item['img_url'] = img_url
yield item
-------------------
1、打开redis服务器:
2、再执行:
h) 执行爬虫程序:scrapy runspider xxx.py
不同之处是要cd 到爬虫文件
3、打开客户端:
redis客户端:lpush 调度器队列的名称 “起始url”

---------------------------
keys *
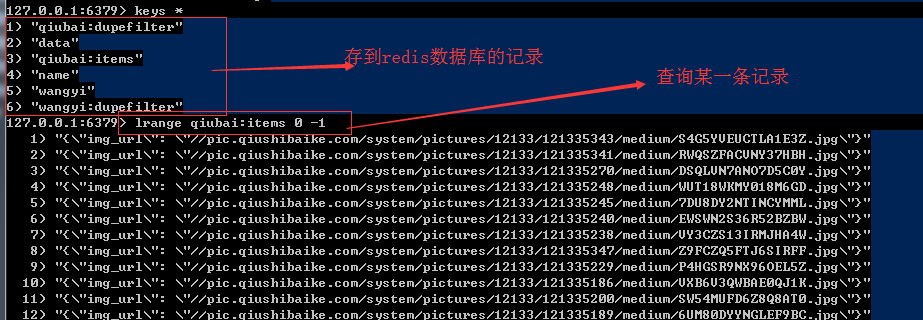
测试成功
爬虫--Scrapy-CrawlSpider&基于CrawlSpide的分布式爬虫的更多相关文章
- python 全栈开发,Day140(RabbitMQ,基于scrapy-redis实现分布式爬虫)
一.RabbitMQ 队列 在生产者消费模型中,比如去餐馆吃饭的例子.生产者相当于厨师,队列相当于服务员,消费者就是你. 我们必须通过服务员,才能吃饭! 如果队列满了,队列会一直hold住.必须让消费 ...
- 基于 Scrapy-redis 的分布式爬虫详细设计
基于 Scrapy-redis 的分布式爬虫设计 目录 前言 安装 环境 Debian / Ubuntu / Deepin 下安装 Windows 下安装 基本使用 初始化项目 创建爬虫 运行爬虫 ...
- 基于scrapy-redis的分布式爬虫
一.介绍 1.原生的scrapy框架 原生的scrapy框架是实现不了分布式的,其原因有: 1. 因为多台机器上部署的scrapy会各自拥有各自的调度器,这样就使得多台机器无法分配start_urls ...
- 阿里云Centos7.6上面部署基于redis的分布式爬虫scrapy-redis将任务队列push进redis
Scrapy是一个比较好用的Python爬虫框架,你只需要编写几个组件就可以实现网页数据的爬取.但是当我们要爬取的页面非常多的时候,单个服务器的处理能力就不能满足我们的需求了(无论是处理速度还是网络请 ...
- 在阿里云Centos7.6上面部署基于Redis的分布式爬虫Scrapy-Redis
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_83 Scrapy是一个比较好用的Python爬虫框架,你只需要编写几个组件就可以实现网页数据的爬取.但是当我们要爬取的页面非常多的 ...
- 基于java的分布式爬虫
分类 分布式网络爬虫包含多个爬虫,每个爬虫需要完成的任务和单个的爬行器类似,它们从互联网上下载网页,并把网页保存在本地的磁盘,从中抽取URL并沿着这些URL的指向继续爬行.由于并行爬行器需要分割下载任 ...
- 爬虫--Scrapy-基于RedisSpider实现的分布式爬虫
爬取网易新闻 需求:爬取的是基于文字的新闻数据(国内,国际,军事,航空) 先编写基于scrapycrawl 先创建工程 scrapy startproject 58Pro cd 58Pro 新建一个爬 ...
- 小白进阶之Scrapy(基于Scrapy-Redis的分布式以及cookies池)
首先我们更新一下scrapy版本.最新版为1.3 再说一遍Windows的小伙伴儿 pip是装不上Scrapy的.推荐使用anaconda .不然还是老老实实用Linux吧. conda instal ...
- 爬虫--Scrapy框架课程介绍
Scrapy框架课程介绍: 框架的简介和基础使用 持久化存储 代理和cookie 日志等级和请求传参 CrawlSpider 基于redis的分布式爬虫 一scrapy框架的简介和基础使用 a) ...
随机推荐
- hive命令的3种调用方式
方式1:hive –f /root/shell/hive-script.sql(适合多语句) hive-script.sql类似于script一样,直接写查询命令就行 例如: [root@cloud ...
- 廖雪峰Java4反射与泛型-2注解-2定义注解
1.定义注解 使用@interface定义注解Annotation 注解的参数类似无参数方法 可以设定一个默认值(推荐) 把最常用的参数命名为value(推荐) 2.元注解 2.1Target使用方式 ...
- keystone认证服务
实验操作平台:OpenStack单节点操作 一.相关概念 1.认证(authentication) 认证是确认允许一个用户访问的进程 2.证书(credentials) 用于确认用户身份的数据 3.令 ...
- [UE4]小地图UI设计
一.新建一个名为TestMiniMap的UserWidget用来使用小地图StaticMiniMap. 二.在左侧“User Created”面板中可以看到除自身以外的其他所有用户创建的UserWid ...
- [UE4]世界坐标和相对坐标
一.世界坐标:相对于整个世界的坐标 二.相对坐标是相对于组件父级的坐标.如下图: 1.Mesh组件和CameraPositionArrow组件的相对坐标是相对于Root组件的坐标 2.Cube组件的相 ...
- 在线学习和在线凸优化(online learning and online convex optimization)—基础介绍1
开启一个在线学习和在线凸优化框架专题学习: 1.首先介绍在线学习的相关概念 在线学习是在一系列连续的回合(rounds)中进行的: 在回合,学习机(learner)被给一个question:(一个向量 ...
- (转)C# WebApi 异常处理解决方案
原文地址:http://www.cnblogs.com/landeanfen/p/5363846.html 一.使用异常筛选器捕获所有异常 我们知道,一般情况下,WebApi作为服务使用,每次客户端发 ...
- Linux下Mysql的odbc配置
在安装配置之前,需要先大概了解一下MyODBC的架构. MyODBC体系结构建立在5个组件上,如下图所示: Driver Manager: 负责管理应用程序和驱动程序间的通信,主要功能包括:解析DSN ...
- Python ————反射机制
python中的反射功能是由以下四个内置函数提供:hasattr.getattr.setattr.delattr,改四个函数分别用于对对象内部执行:检查是否含有某成员.获取成员.设置成员.删除成员. ...
- MySQL关于sql_mode的修改(timestamp的默认值不正确)
timestamp的默认值不正确原因: MySQL5.7版本中有了一个STRICT mode(严格模式),而在此模式下默认是不允许设置日期的值为全0值的,所以想要解决这个问题,就需要修改sql_mod ...