deeplearning.ai学习seq2seq模型
一、seq2seq架构图
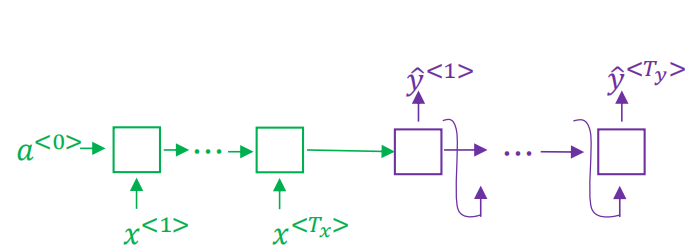
seq2seq模型左边绿色的部分我们称之为encoder,左边的循环输入最终生成一个固定向量作为右侧的输入,右边紫色的部分我们称之为decoder。单看右侧这个结构跟我们之前学习的语言模型非常相似,如下:
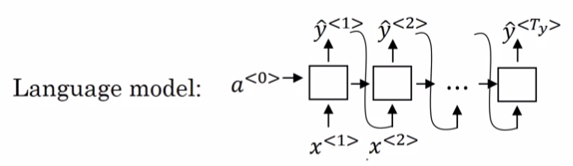
唯一不同的是,语言模型的输入a<0>是一个零向量,而seq2seq模型decoder部分的输入是由encoder编码得到的一个固定向量。所以可以称seq2seq模型为条件语言模型p(y|x)。
语言模型生成的序列y是可以随机生成的,而seq2seq模型用于到机器翻译中,我们是要找到概率最大的序列y,即最可能或者说最好的翻译结果,max p(y|x)。
seq2seq模型如何寻找到最可能的序列y呢?
是不是可以采用贪心算法呢?如果采用贪心算法找的结果不一定是最优的,只能说是其中一个结果。因为贪心算法的思路是先找到第一个最好的y<1>,第一个输出结果y<1>再找到第二个最好的y<2>,以此类推。这种方式的最终结果是每一个元素可能是最优的,但是整个句子却未必是最好的。例如下面的句子:

采用贪心算法,最可能的结果就是第二句,因为如果前两个是Jane is ,第三个最可能的是going,而不是visiting,这是因为is going在英语中大量存在。但是最好的结果却是第一个句子。
二、beam search(集束搜索)
还是以上述机器翻译的例子来解释集束搜索算法流程,第一步如下:

第一步就是先根据左侧的输入,生成第一个输出y<1>,y<1>是softmax转换后的概率输出。集束搜索需要设置集束宽度,本次设置B(beam width)=3,也就是每次仅保留概率最大的top3个。所以,第一步就是选择y<1>中概率最大的前三个词,假设本例子中是in,jane,september,就保留这三个词在内存中。
第二步:
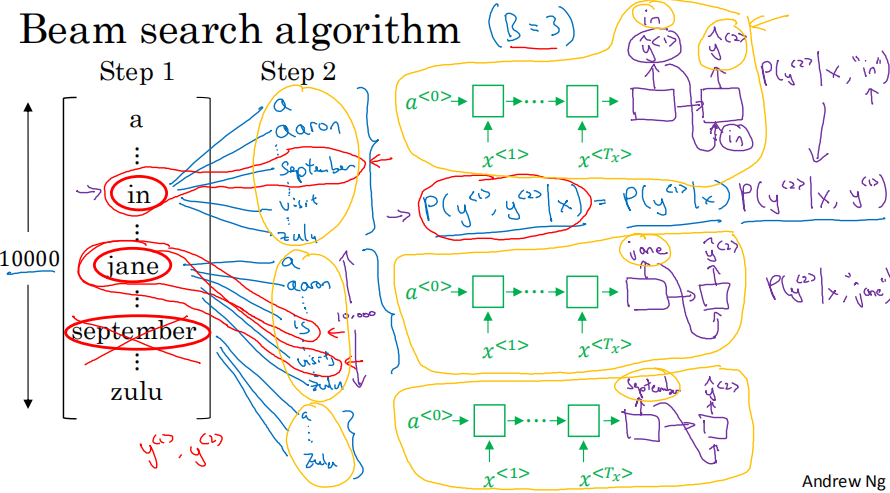
第二步就是在y<1>为in,jane,September的情况下,分别计算第二个词的概率,如上图所示套入三个seq2seq模型中去各自寻找。因为词典维度|v|=10000,所以三个词最终会计算出30000个后面衔接第二个词的概率,最终从这30000个里面选出概率最大的top3个即可,因为集束宽度依然为3。假设第二步筛选出来的结果是in september, jane is,jane visits;September开头的因为连接后面的词后概率偏低,已经被去掉了。
第三步:
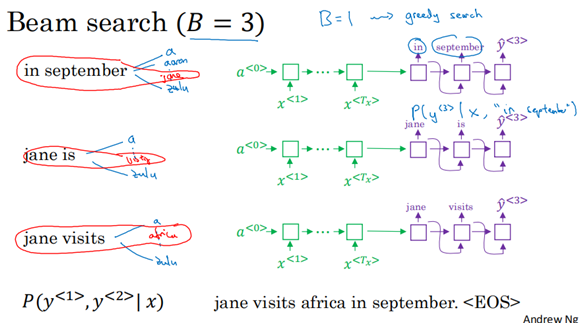
第三步其实是跟第二步一样,直到最后选出EOS结束。
三、beam search的优化
优化一:
将概率的乘积转化成为概率的对数求和。
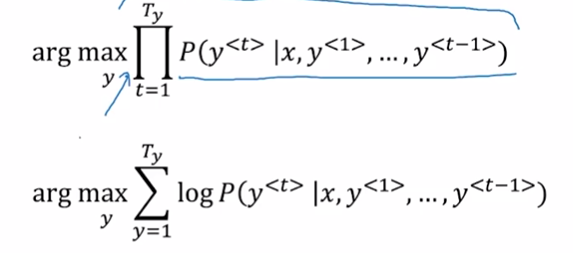
因为乘积的话,会越乘越小,甚至会导致数值的下溢问题。取对数后就变成了连加,就基本解决了这个问题,而且对数后的目标函数与原目标函数解是一致的。
优化二:
归一化目标函数,除以翻译结果的单词数量,减少了对长的结果的惩罚。因为从上述目标函数可以看出,无论原目标函数还是对数目标函数,都不利于长的结果的输出,因为结果越长,连乘或者连加(每个元素取对数后都是负数)都使得概率越来越小。
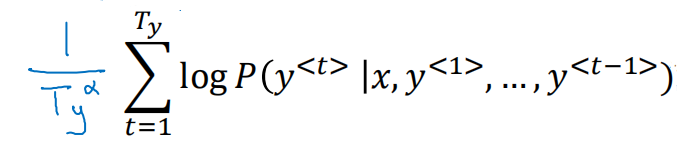
这里的Ty就是翻译结果的单词数量,α是一个超参数,可以设置0(相当于不做归一化),0.7,1,需要根据实际情况调整得到一个最优的结果。
集束宽度B的选择:
large B:效果好,计算代价大,运行慢。
small B:效果差,计算代价小,运行快。
工业中,B=10,往往是一个不错的选择;科研中,为了充分实验,可以尝试100,1000,3000.
B从1~10,性能提升比较明显,但是B从1000~3000,提升就没有那么明显了。
总结,相比于BFS(广度优先搜索)、DFS,beam search不能保证一定能找到arg max 的准确最大值,是一个近似的最大值。
deeplearning.ai学习seq2seq模型的更多相关文章
- DeepLearning.ai学习笔记(三)结构化机器学习项目--week2机器学习策略(2)
一.进行误差分析 很多时候我们发现训练出来的模型有误差后,就会一股脑的想着法子去减少误差.想法固然好,但是有点headlong~ 这节视频中吴大大介绍了一个比较科学的方法,具体的看下面的例子 还是以猫 ...
- DeepLearning.ai学习笔记汇总
第一章 神经网络与深度学习(Neural Network & Deeplearning) DeepLearning.ai学习笔记(一)神经网络和深度学习--Week3浅层神经网络 DeepLe ...
- deeplearning.ai学习RNN
一.RNN基本结构 普通神经网络不能处理时间序列的信息,只能割裂的单个处理,同时普通神经网络如果用来处理文本信息的话,参数数目将是非常庞大,因为如果采用one-hot表示词的话,维度非常大. RNN可 ...
- DeepLearning.ai学习笔记(五)序列模型 -- week1 循环序列模型
一.为什么选择序列模型 序列模型可以用于很多领域,如语音识别,撰写文章等等.总之很多优点... 二.数学符号 为了后面方便说明,先将会用到的数学符号进行介绍. 以下图为例,假如我们需要定位一句话中人名 ...
- DeepLearning.ai学习笔记(五)序列模型 -- week2 自然语言处理与词嵌入
一.词汇表征 首先回顾一下之前介绍的单词表示方法,即one hot表示法. 如下图示,"Man"这个单词可以用 \(O_{5391}\) 表示,其中O表示One_hot.其他单词同 ...
- DeepLearning.ai学习笔记(五)序列模型 -- week2 序列模型和注意力机制
一.基础模型 假设要翻译下面这句话: "简将要在9月访问中国" 正确的翻译结果应该是: "Jane is visiting China in September" ...
- DeepLearning.ai学习笔记(一)神经网络和深度学习--Week3浅层神经网络
介绍 DeepLearning课程总共五大章节,该系列笔记将按照课程安排进行记录. 另外第一章的前两周的课程在之前的Andrew Ng机器学习课程笔记(博客园)&Andrew Ng机器学习课程 ...
- DeepLearning.ai学习笔记(四)卷积神经网络 -- week2深度卷积神经网络 实例探究
一.为什么要进行实例探究? 通过他人的实例可以更好的理解如何构建卷积神经网络,本周课程主要会介绍如下网络 LeNet-5 AlexNet VGG ResNet (有152层) Inception 二. ...
- DeepLearning.ai学习笔记(四)卷积神经网络 -- week4 特殊应用:人力脸识别和神经风格转换
一.什么是人脸识别 老实说这一节中的人脸识别技术的演示的确很牛bi,但是演技好尴尬,233333 啥是人脸识别就不用介绍了,下面笔记会介绍如何实现人脸识别. 二.One-shot(一次)学习 假设我们 ...
随机推荐
- Alpha版阶段项目总结
一,设想和目标 1. 我们的软件要解决什么问题?是否定义得很清楚?是否对典型用户和典型场景有清晰的描述? 针对铁道大学大学生,增加他们的社交范围.我们的软件定义很清楚.对典型用户和典型场景有清晰的描述 ...
- 每日scrum(4)
今天是冲刺第4天,大家都忙着找大二的学弟学妹来点评来支持我们的软件. 遇到的问题主要是如何劝说学弟学妹选择我们的软件然后继续往下做. 任务看板: 燃尽图:
- svn 创建主干 分支版本
转载 https://www.cnblogs.com/dongzhiquan/p/5222018.html SVN分支与合并 一. 分支与合并的概念 二. SVN分支的意义 三. 如何创建分支与合并 ...
- 对比网络模拟器软件——Cisco Packet Tracer、华为eNSP、H3C Cloud Lab
1.软件介绍 1.1 Cisco Packet Tracer Cisco Packet Tracer(以下简称PT)是一款由思科公司开发的,为网络课程的初学者提供辅助教学的实验模拟器.使用者可以在该模 ...
- 对于beta发布的评论
第一组:新蜂小组 题目:俄罗斯方块 评论:主体功能已经完成,可以流畅的进行游戏,看项目的完成度是最高的.他们不但把核心功能做出来了,界面也已基本完成. 第二组:Nice团队 题目:约跑APP(约吧) ...
- BeanFactory 简介以及它 和FactoryBean的区别(阿里面试)
BeanFacotry是spring中比较原始的Factory.如XMLBeanFactory就是一种典型的BeanFactory.原始的BeanFactory无法支持spring的许多插件,如AOP ...
- 一本通1639Biorhythms
1639:Biorhythms 时间限制: 1000 ms 内存限制: 524288 KB [题目描述] 原题来自:POJ 1006 人生来就有三个生理周期,分别为体力.感情和智力周期 ...
- ubuntu修改用户名并修改home对应的目录名
1.新建一个新的用户user2 sudo adduser temporary sudo adduser temporary sudo 2.从user1 logout.进入新建用户user2,修改use ...
- 【刷题】BZOJ 2125 最短路
Description 给一个N个点M条边的连通无向图,满足每条边最多属于一个环,有Q组询问,每次询问两点之间的最短路径. Input 输入的第一行包含三个整数,分别表示N和M和Q 下接M行,每行三个 ...
- 【刷题】LOJ 6011 「网络流 24 题」运输问题
题目描述 W 公司有 \(m\) 个仓库和 \(n\) 个零售商店.第 \(i\) 个仓库有 \(a_i\) 个单位的货物:第 \(j\) 个零售商店需要 \(b_j\) 个单位的货物.货物供需平衡, ...