Parallel Gradient Boosting Decision Trees
本文转载自:链接
Highlights
- Three different methods for parallel gradient boosting decision trees.
- My algorithm and implementation is competitve with (and in many cases better than) the implementation in OpenCV and XGBoost (A parallel GBDT library with 750+ stars on GitHub).
Introduction
Gradient boosting is a machine learning technique for regression problems, which produces a prediction model in the form of an ensemble of weak prediction models. Gradient Boosting Decision Trees use decision tree as the weak prediction model in gradient boosting, and it is one of the most widely used learning algorithms in machine learning today. Its high accuracy makes that almost half of the machine learning contests are won by GBDT models. Below shows an example of the model.
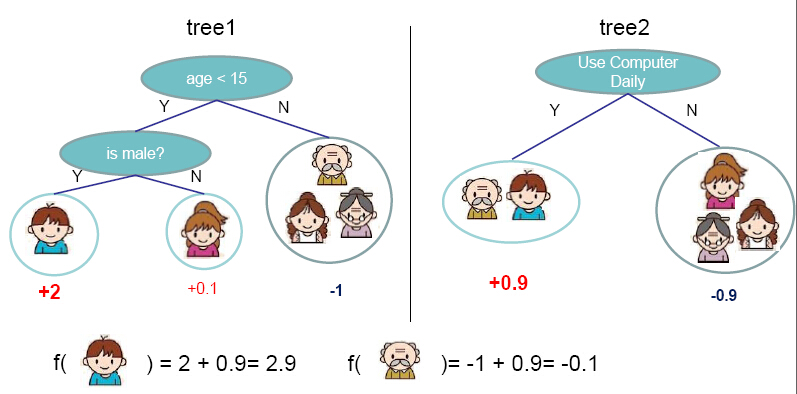
Figure from http://homes.cs.washington.edu/~tqchen/pdf/BoostedTree.pdf
The general idea of the method is additive training. At each iteration, a new tree learns the gradients of the residuals between the target values and the current predicted values, and then the algorithm conducts gradient descent based on the learned gradients. The algorithm description from Wikipedia is showed as followed:

We can see that this is a sequential algorithm. Therefore, we can't parallelize the algorithm like Random Forest. We can only parallelize the algorithm in the tree building step. Therefore, the problem reduces to parallel decision tree building.
Experiment Setting
Since some experimental results will be showed when introducing the algorithm, we first introduce the dataset and the setting of the experiments. The data we use is from a competition of IJCAI'15. We extracted one small dataset and one large datset from the data. The statistics of the small dataset and the large dataset are showed as follows:
- Small dataset: 130K instances, each with 42 attributes.
- Large dataset: 1M instances, each with 42 attributes, generated by duplicating the small dataset for eight times.
Without specification, the experimental results below are obtained from the small dataset. All the running time below are measured by growing 100 trees with maximum depth of a tree as 8 and minimum weight per node as 10. All the experiments are performed on a Debian machine with eight Intel E5-2650 2.0GHz cores and 64GB memory.
Sequential Decision Tree Building
We first define the input and output of the decision tree building problem:
- Input: N instances each with m attributes and one target values.
- Output: A fitted decision tree for the input.
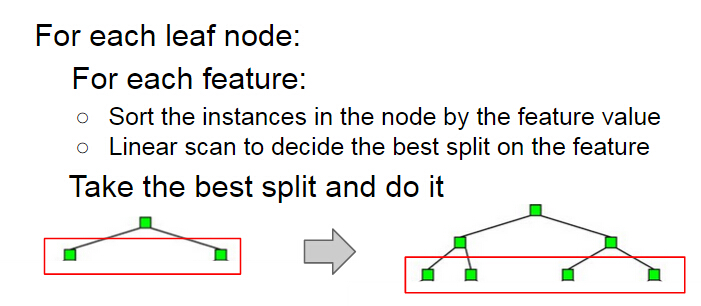
We also recap the algorithm for sequential decision tree building below. The building process grows a decision tree by levels. At each level, the algorithm first enumerates each leaf node at the level, and then conducts a split finding process on the node. During the split finding process for a node, the algorithm enumerates each features, then sorts the instances in the node by the feature values, and finds the best split of that feature in the node by linear scan. Finally the algorithm chooses the best split among those of all the features to split the node.
Method 1: Parallelize Node Building at Each Level
A simple idea of parallel decision tree bulding is to parallelize node building at each level. However, this method has a serious workload imbalanced problem. The reason is that a decsion tree tends to purify its nodes to obtain high prediction accuracy, and therefore many of the nodes will only contain a small group of training instances that have purified results, while some other nodes contain large group of trianing instances. The figure below shows an example of the imbalanced workload problem. Suppose we are going to build the nodes in the red box in parallel. We can see that the first and the third nodes contain much less training instances than the second and the fourth node, which causes the workload imbalanced.
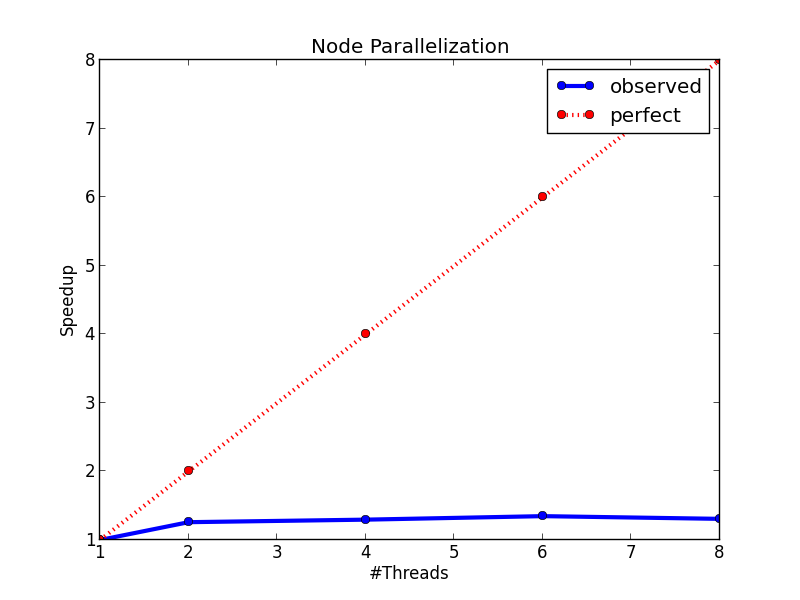
The figure below shows the speedup of the node parallelization method. We can see that we only gain a very small speedup from node parallelization due to the workload imbalanced problem.
Method 2: Parallelize Split Finding on Each Node
Recall that in the split finding process on a node (the process is showed below), we need to enumerate each feature to find the split. The idea of this method is to parallelize the split finding process, so that in each node, the algorithm find split for different features in parallel.

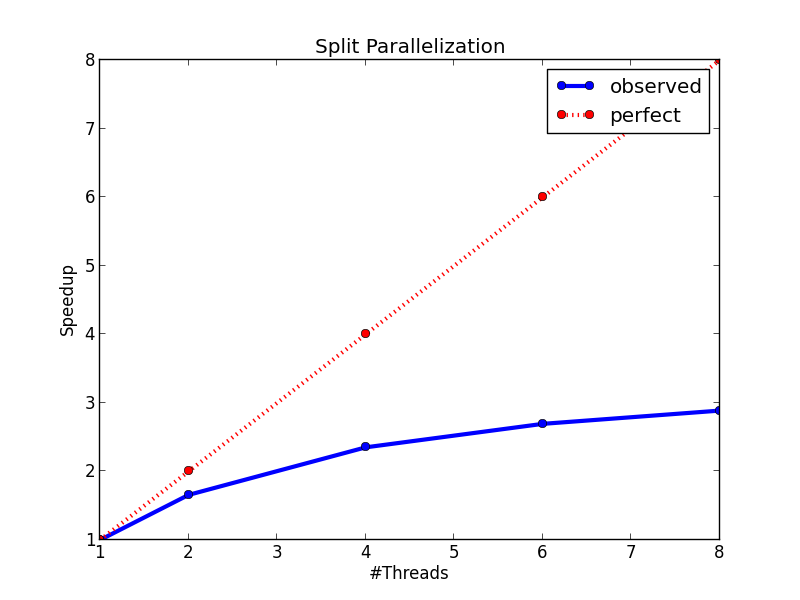
The speedup figure below shows that this method performs better than node parallelization. However, it still fails to achieve half of the peek speedup. The main problem of this method is that it will has too much overhead for small nodes. When a decision tree grows deeper, most of the nodes will only contain a small number of training instances. In this case, the computation cost for each node is very small, and the benefit brought by parallel computing can not cover the overhead brought by context switching, thread joining, and etc., which makes the method fails to achieve a good speedup. However, this method indeed points us to a correct direction, and our final method is based on parallel split finding by features.
Method 3: Parallelize Split Finding at Each Level by Features
It is showed above that at each level, the sequential building process of decision tree has two loops, the first one is an outer loop for enumerating the leaf nodes, and the second one is an inner loop that enumerates the features. The idea of this method is to swap the order of these two loops, so that we can parallelize the split finding for different features at the same level. A pseudocode of the algorithm is showed below. We can see that by changing the order of the loop, we also avoid sorting the instances in each node. We can sort the instances at the start of the whole building process, and then use the same sorting result at each level. On the other hand, note that to keep the correctness of the algorithm, each thread needs to carefully maintain their scaning status of each leaf node during the linear scan process, which significantly increases the coding complexity of the algorithm.

The advantages of the method are:
- Workload are totally balanced. Since the number of instances for each feature is the same, the workload for different jobs is the same. Thus, we do not have the workload imbalanced problem in method 1.
- Overhead for parallelization is small. Since we parallelize split finding at the whole level rather than a single node, the benefit from parallel computing is totally enough to cover the overhead from parallel computing.
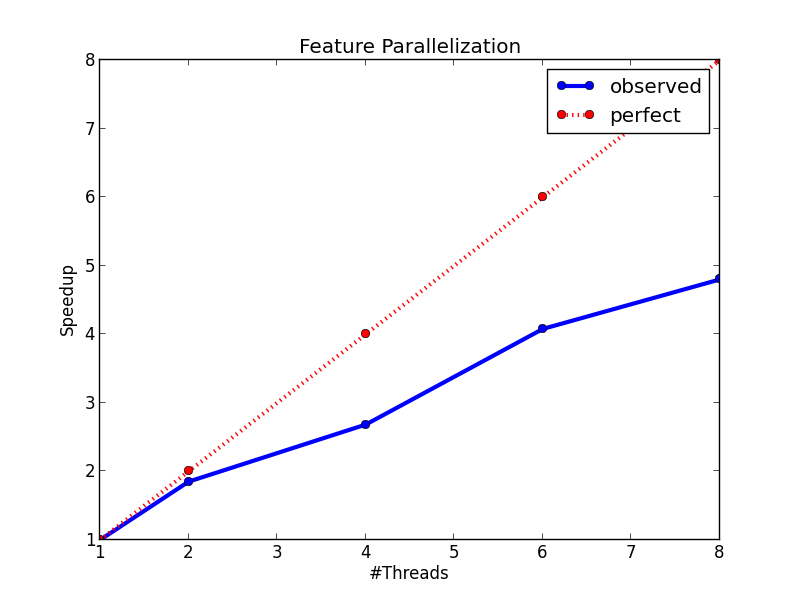
The figures below show the speedup of the method and the running time comparison between this method and method 2. On the left figure, we can see that the method has an almost perfect speedup with two threads, and a 4.8x speedup with eight threads. On the right figure, we can see that the method is much faster than method 2, and it is because of the lower time complexity of the algorithm and the smaller overhead from multi-threading.
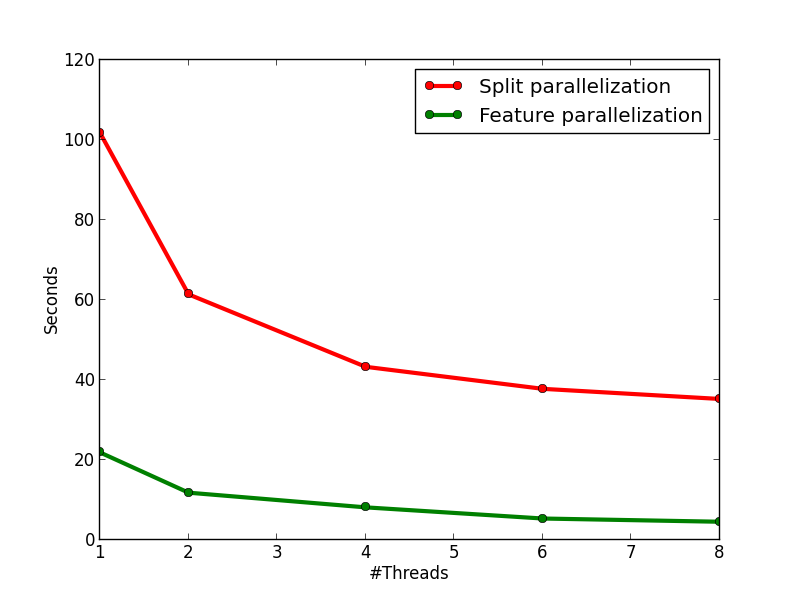
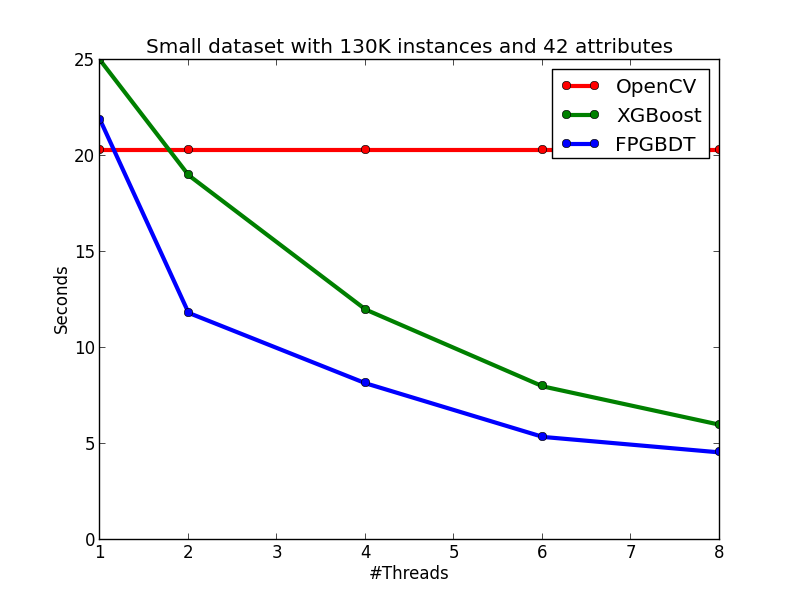
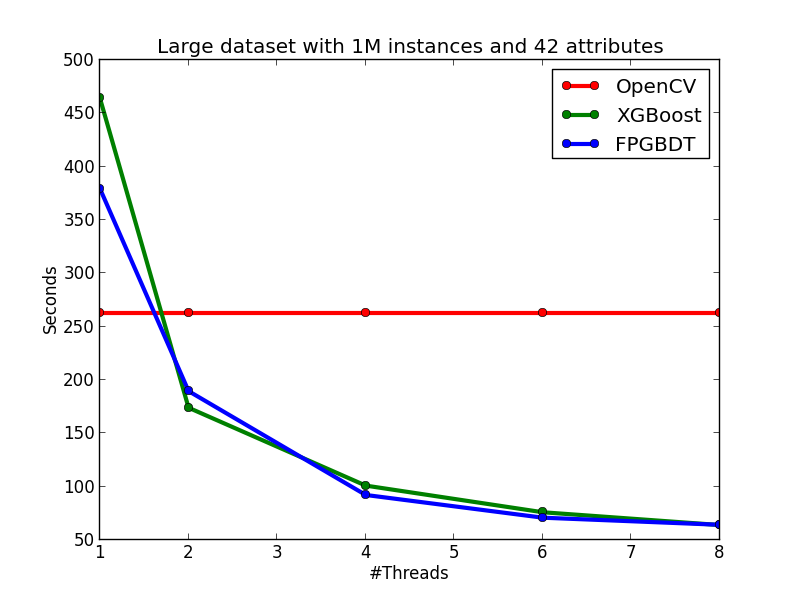
Compare with OpenCV and XGBoost
In this section, I show the effectiveness of my method and implementation by comparing with two strong baselines: OpenCV and XGBoost. The introduction of the two baselines are showed as follows:
- OpenCV: a sequential GBDT implementation in the OpenCV library. The algorithm will do early-stop pruning while growing a tree to reduce the computation.
- XGBoost: a parallel GBDT library with 750+ stars on GitHub.
My algorithm and implementation is competitve with (and in many cases better than) the implementation in OpenCV and XGBoost. The figures below show the running time of the three implementations on the two datasets. We can see that on the small dataset, my implementation is slightly slower than the OpenCV implementation on the single-thread case, but becomes faster than OpenCV when the number of threads is more than one since OpenCV does not have multi-thread implementation. When comparing with XGBoost on the small dataset, my implementation is faster than XGBoost on each tested thread configuration. On the large dataset, we can see that OpenCV performs significatly better in the single-thread case due to the early pruning technique, but worse than my method in the multi-thread cases. When comparing with XGBoost, in general, my implementation performs slightly better than XGBoost, but the performance difference between the two methods are not obvious.
Last updated by Zhanpeng Fang, May. 11th 2015.
Parallel Gradient Boosting Decision Trees的更多相关文章
- Gradient Boosting, Decision Trees and XGBoost with CUDA ——GPU加速5-6倍
xgboost的可以参考:https://xgboost.readthedocs.io/en/latest/gpu/index.html 整体看加速5-6倍的样子. Gradient Boosting ...
- Facebook Gradient boosting 梯度提升 separate the positive and negative labeled points using a single line 梯度提升决策树 Gradient Boosted Decision Trees (GBDT)
https://www.quora.com/Why-do-people-use-gradient-boosted-decision-trees-to-do-feature-transform Why ...
- Gradient Boosting Decision Tree学习
Gradient Boosting Decision Tree,即梯度提升树,简称GBDT,也叫GBRT(Gradient Boosting Regression Tree),也称为Multiple ...
- GBDT(Gradient Boosting Decision Tree)算法&协同过滤算法
GBDT(Gradient Boosting Decision Tree)算法参考:http://blog.csdn.net/dark_scope/article/details/24863289 理 ...
- GBDT(Gradient Boosting Decision Tree) 没有实现仅仅有原理
阿弥陀佛.好久没写文章,实在是受不了了.特来填坑,近期实习了(ting)解(shuo)到(le)非常多工业界经常使用的算法.诸如GBDT,CRF,topic model的一些算 ...
- 梯度提升树 Gradient Boosting Decision Tree
Adaboost + CART 用 CART 决策树来作为 Adaboost 的基础学习器 但是问题在于,需要把决策树改成能接收带权样本输入的版本.(need: weighted DTree(D, u ...
- 论文笔记:LightGBM: A Highly Efficient Gradient Boosting Decision Tree
引言 GBDT已经有了比较成熟的应用,例如XGBoost和pGBRT,但是在特征维度很高数据量很大的时候依然不够快.一个主要的原因是,对于每个特征,他们都需要遍历每一条数据,对每一个可能的分割点去计算 ...
- Gradient Boosting Decision Tree
GBDT中的树是回归树(不是分类树),GBDT用来做回归预测,调整后也可以用于分类.当采用平方误差损失函数时,每一棵回归树学习的是之前所有树的结论和残差,拟合得到一个当前的残差回归树,残差的意义如公式 ...
- 后端程序员之路 10、gbdt(Gradient Boosting Decision Tree)
1.GbdtModelGNode,含fea_idx.val.left.right.missing(指向left或right之一,本身不分配空间)load,从model文件加载模型,xgboost输出的 ...
随机推荐
- vba中布尔类型、字符串操作
在vba中,bool类型数据可以参与数学运算,true为-1,false为0 Sub mysub() Dim mybool As Boolean Debug.Print Debug.Print myb ...
- UVa 11427 Expect the Expected (数学期望 + 概率DP)
题意:某个人每天晚上都玩游戏,如果第一次就䊨了就高兴的去睡觉了,否则就继续直到赢的局数的比例严格大于 p,并且他每局获胜的概率也是 p,但是你最玩 n 局,但是如果比例一直超不过 p 的话,你将不高兴 ...
- MongoDB常用命令总结
查看数据库 show dbs; 选择某个库 use db; 查看库下的表(暂且说成是表,mongodb中称表问文档) show collections; 插入数据 db.table.insert( { ...
- hadoop yarn组件介绍
Yarn的产生 mapReduc1.0 1单点故障 2扩展效率低 3资源利用率高 降低运维成本 方便数据共享 多计算框架支持 MapReduce Spark Storm Yarn的架构图 Yarn模块 ...
- Ajax传数据到servlet
//jsp代码 <%@ page language="java" contentType="text/html; charset=ISO-8859-1" ...
- Shell编程-12-Shell脚本规范及调试
目录 Shell脚本规范 Shell脚本调试 Shell脚本规范 良好的代码规范不仅方便阅读,也利于维护和提升开发效率.因此建议大家在编写Shell脚本时养成良好的代码习惯.今天就和大家探讨一 ...
- Codeforces812A Sagheer and Crossroads 2017-06-02 20:41 139人阅读 评论(0) 收藏
A. Sagheer and Crossroads time limit per test 1 second memory limit per test 256 megabytes input sta ...
- Sensor
原理:http://blog.csdn.net/xiaolei05/article/details/18670161 1.Sensor Type 重力感应/加速度传感器 (G-Sensor ...
- Filter查询
Filter查询 filter是不计算相关性的,同时可以cache,因此,filter速度要块于query 数据准备 POST /lib3/user/_bulk{"index":{ ...
- bootstrap2.1
<html> <head> <meta charset="utf-8" /> <title></title> ...