什么是Familywise Error Rate
1.什么是Familywise Error Rate(FWE or FWER)
定义:在一系列假设检验中,至少得出一次错误结论的概率。
换句话说,是造成至少一次Type I Error的概率。术语FWE来自测试系列,这是一系列数据测试的技术定义
2.估计FWE的公式
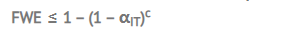
- αIT:一个独立测试的显著水平
- c : 对比次数
举个例子,对于一个10次试验的的序列,显著水平5%,FWE = ≤ 1 – (1 – .05)^10 = 0.401 ,这意味着Type I Error 发生的概率超过了40%,对于只有10次试验而言,是非常高的
3.控制FWE
单步执行,Bonferroni校正
单步程序对每个p值进行相同的调整。这保持了整个alpha水平保持在期望值(例如..05)。该方法被称为被称为Bonferroni校正。
1. 将alpha级别除以正在运行的测试的数量,并将该alpha级别应用于每个单独的测试。例如,如果您的整体alpha水平是.05,并且您正在运行5个测试,那么每个测试的alpha水平将是.05/5=.01。
2. 在每个测试中应用新的alpha级别来查找p值。在本例中,p值必须小于或等于0.01才具有统计意义。
多步执行
Similar to Bonferroni, but makes adaptive adjustments to each p-value. Several sequential methods exist. The easiest is probably the Holm-Bonferroni Method, but several others have been developed including the Sidak-Bonferroni and Holland-Copenhaver.
- Holm-Bonferroni: tests are run and then ordered from lowest to highest p-values. The individual tests are then tested (starting with the one with the lowest p-value) with an overall Bonferroni correction for all tests. See: Holm-Bonferroni Method for a step-by-step example.
- Sidak-Bonferroni (sometimes called the Boole or Dunn approximation): a variant of Bonferroni which uses a Taylor expansion (from calculus)
Type I Error
Type I Error 就是错误地拒绝了一个真实的零假设Ho(null hypothesis)(应该接受的)
null hypothesis :普遍接受的假设
Ho是一个普遍接受的假设;它与备择假设相反。研究人员提出了另一种假设,他们认为这种假设解释了一种现象,然后努力拒绝零假设。
Type II Error
Il型错误(有时称为2型错误)是拒绝虚假零假设的失败。类型ll错误的概率用符号B表示。
reference:https://www.statisticshowto.datasciencecentral.com/familywise-error-rate/
什么是Familywise Error Rate的更多相关文章
- [ZZ] Equal Error Rate (EER)
这篇博客很全面 http://www.cnblogs.com/cdeng/p/3471527.html ROC曲线 1.混淆矩阵(confusion matrix) 针对预测值和真实值之间的关系,我们 ...
- ImageNet: what is top-1 and top-5 error rate?
https://stats.stackexchange.com/questions/156471/imagenet-what-is-top-1-and-top-5-error-rate Your cl ...
- 一张图,关于 Bayes error rate,贝叶斯错误率等的分析
造轮子是那帮搞研究的“科学家”干的事情(类似E&E里的explore),“工程师”的职责是利用已有的东西解决问题(类似E&E里的exploit). 其次,即使以工程师的角色解决业务问题 ...
- 假设检验:p-value,FDR,q-value
来源:http://blog.sina.com.cn/s/blog_6b1c9ed50101l02a.html,http://wenku.baidu.com/link?url=3mRTbARl0uPH ...
- FDR
声明: 网上摘抄 False discovery rate (FDR) control is a statistical method used in multiple hypothesis test ...
- Omnibus test
sklearn实战-乳腺癌细胞数据挖掘(博客主亲自录制视频教程) https://study.163.com/course/introduction.htm?courseId=1005269003&a ...
- P<0.05就够了?还要校正!校正!3个方法献上
P<0.05就够了?还要校正!校正!3个方法献上 (2017-01-03 17:55:12) 转载▼ 分类: 数理统计 (转 医生科研助手 解螺旋 微信公众号) 当有多组数据要比较时, ...
- Holm–Bonferroni method
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录视频) https://study.163.com/course/introduction.htm?courseId=1005269003&u ...
- Turkey HSD检验法/W法
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录视频) https://study.163.com/course/introduction.htm?courseId=1005269003&u ...
随机推荐
- [转]arcgis for server 10.2 下载及安装
转自:https://blog.csdn.net/nominior/article/details/80211963 https://blog.csdn.net/mrib/article/detail ...
- Java统计文件数量
Java统计文件数量 package com.vfsd; import java.io.File; import java.io.IOException; /********************* ...
- PAT 甲级 1073 Scientific Notation (20 分) (根据科学计数法写出数)
1073 Scientific Notation (20 分) Scientific notation is the way that scientists easily handle very ...
- sed替换字符串(变量)
sed “s/查找字段/替换字段/g” echo helloworld|sed ‘s/hello/world/g’ sed 替换字符串以变量形式 1.sed命令使用双引号的情况下,可以使用$var( ...
- Form表单的传递与接收
目录 表单的构建 后端接收 创建model 用Model接收表单的后端 表单的构建 我才知道这个东西,在开发中经常遇到表单的情况.一下子提交一串内容.表单元素 form,里面的内容必须有name字段. ...
- webpack 安装vue(两种代码模式compiler 和runtime)
使用webpack安装vue,import之后,运营项目报错,如下: [Vue warn]: You are using the runtime-only build of Vue where the ...
- DevOps - DevOps精要 - 溯源
1 - DevOps的含义 DevOps涉及领域广泛,其含义因人而异,在不同的理解和需求场景下,有着不同的实践形式. DevOps可以理解为是一个职位.一套工具集合.一组过程与方法.一种组织形式与文化 ...
- 微服务Consul系列之服务部署、搭建、使用
使用Consul解决了哪些问题 是否在为不同环境来维护不同项目配置而发愁 是否有因为配置的更改导致代码还要进行修改.发布因为客流量大了还要规避开高峰期等到半夜来发布 微服务架构下应用的分解业务系统与服 ...
- web端调起Windows系统应用程序(exe执行文件),全面兼容所有浏览器
1. 首先,你要有一个exe可执行文件2. 创建注册表创建注册表有两种方式(以“MyApp.exe”为例): 方式一:可视化编辑Win+R 打开运行,输入 regedit 并回车,进入注册表编辑器新建 ...
- velocity 自定义工具类接入
网上的教程几乎都是同一篇: velocity 自定义工具类 - eggtk - CSDN 博客 但是教程有不完善的地方,我就补充一下. 补充: 引入的jar包和版本要一致.我们项目中因为没有定义确切版 ...