编译+远程调试spark
一 编译
以spark2.4 hadoop2.8.4为例
1,spark 项目根pom文件修改
pom文件新增 <profile>
<id>hadoop-2.8</id>
<properties>
<hadoop.version>2.8.4</hadoop.version>
</properties>
</profile> maven仓库地址增加
<repository>
<id>bilibili-nexus-releases</id>
<url>http://nexus.bilibili.co/content/repositories/releases/</url>
</repository>
<repository>
<id>bilibili-nexus-snapshots</id>
<url>http://nexus.bilibili.co/content/repositories/snapshots/</url>
</repository>
2,在spark home 目录下执行
mvn -T 4 -Pyarn -Phadoop-2.8 -DskipTests clean package
3, 完成 maven编译 进行打包
在spark根目录下执行
./dev/make-distribution.sh --name -hadoop-2.8 --tgz -Dhadoop.version=2.8.4 -Phive -Phive-thriftserver -Pyarn
执行完毕在spark_home 根目录下 即生成相应版本的jar包
若想单独编译某模块 比如编译spark-core

依次执行
mvn clean install //将项目依赖拉到本地
./dev/make-distribution.sh --name hadoop2.8 --tgz -Phadoop-2.8.4 -Phive -Phive-thriftserver -pl:spark-core_2.11 -Pyarn
二 远程Debug
1. 编译远程spark项目下的文件
spark-2.4.0-bin-hadoop2.8/conf/spark-defaults.conf
增加内容如下 这个用来调试spark driver端代码
spark.driver.extraJavaOptions -agentlib:jdwp=transport=dt_socket,server=n,address=你本机的ip:5007,suspend=y
同样调试 excutor也可以如此 只需要 在spark.executor.extraJavaOptions 新增内容即可
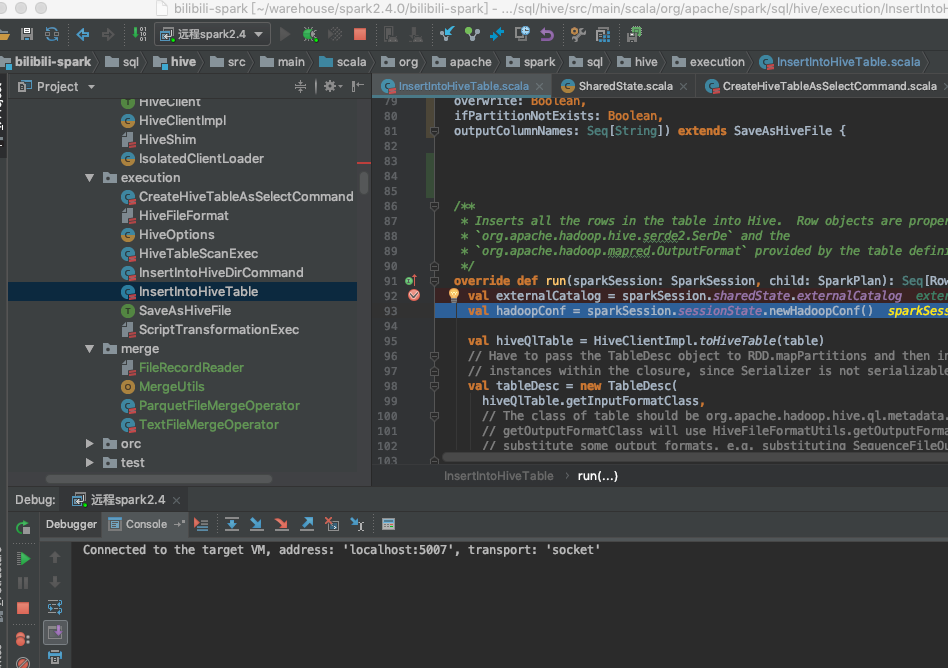
2 我们将spark源码import到idea中
配置远程debug

这里因本地网跟远程不通 所以采用listen模式
先启动本地 idea spark项目 debug 再启动远程的spark任务
如图
下面就是 enjoy yourself
编译+远程调试spark的更多相关文章
- VS混淆/反编译/远程调试/Spy++的Tools工具
VS的Tools工具(混淆/反编译/远程调试/Spy++等) https://blog.csdn.net/chunyexiyu/article/details/14445605 参考:http://b ...
- (二)win7下用Intelij IDEA 远程调试spark standalone 集群
关于这个spark的环境搭建了好久,踩了一堆坑,今天 环境: WIN7笔记本 spark 集群(4个虚拟机搭建的) Intelij IDEA15 scala-2.10.4 java-1.7.0 版本 ...
- Spark代码Eclipse远程调试
我们在编写Spark Application或者是阅读源码的时候,我们很想知道代码的运行情况,比如参数设置的是否正确等等.用Logging方式来调试是一个可以选择的方式,但是,logging方式调试代 ...
- Spark1.4远程调试
1)首先,我们是在使用spark-submit提交作业时,使用 --driver-java-options ”-Xdebug -Xrunjdwp:transport=dt_socket,server= ...
- Spark学习笔记之-Spark远程调试
Spark远程调试 本例子介绍简单介绍spark一种远程调试方法,使用的IDE是IntelliJ IDEA. 1.了解jvm一些参数属性 -X ...
- Spark应用远程调试
本来想用Eclipse的.然而在网上找了一圈,发现大家都在说IntelliJ怎样怎样好.我也受到了鼓励,遂决定在这台破机器上鼓捣一次IntelliJ吧. Spark程序远程调试,就是将本地IDE连接到 ...
- hive,spark的远程调试设置
spark的远程调试 spark-env.sh文件里面,加上下面配置即可: if [ "$DEBUG_MODE" = "true" ]; then export ...
- spark JAVA 开发环境搭建及远程调试
spark JAVA 开发环境搭建及远程调试 以后要在项目中使用Spark 用户昵称文本做一下聚类分析,找出一些违规的昵称信息.以前折腾过Hadoop,于是看了下Spark官网的文档以及 github ...
- Spark远程调试参数
Spark远程调试脚本: #调试Master,在master节点的spark-env.sh中添加SPARK_MASTER_OPTS变量 export SPARK_MASTER_OPTS="- ...
随机推荐
- C++ 2048游戏
2048游戏实现起来还是比较简单的,注意几个细节,调几个bug就好了. 直接上源码,需要的可以拿走(手动滑稽 /*dos windows 25*80*/#include <algorithm&g ...
- Ubuntu 14.04 64bit中永久添加DNS的方法
第一种方法修改如下文件,默认是空的sudo vim /etc/resolvconf/resolv.conf.d/base在里面加入你想添加的DNS服务器,一行一个nameserver 114.114. ...
- Oracle导入数据时出错ORA-39143:转储文件可能是原始的转储文件
dmp文件是使用exp命令导出的,所以使用impdp导入则会报错误. 正确的导入语句为:imp sde/salis@orcl file='E:\sde.dmp' full=y;
- Mybatis generator配置
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE generatorConfiguration ...
- Flutter移动电商实战 --(36)FlutterToast插件使用
https://github.com/PonnamKarthik/FlutterToast fluttertoast: ^3.0.1 category_page.dart页面添加引用 import ' ...
- 《maven实战》笔记(2)----一个简单maven项目的搭建,测试和打包
参照<maven实战>在本地创建对应的基本项目helloworld,在本地完成后项目结构如下: 可以看到maven项目的骨架:src/main/java(javaz主代码)src/test ...
- LC 988. Smallest String Starting From Leaf
Given the root of a binary tree, each node has a value from 0 to 25 representing the letters 'a' to ...
- Rect和RectF函数
1.是否包含点,矩形 判断是否包含某个点 boolean contains(int x,int y) 函数用于判断某个点是否在当前矩形中,如果在,则返回true ,不在则false 2.判断是否包含 ...
- 多位IT专家分享他们离不开的实用工具
本文的 PDF版本可供下载. #1: John Bartow,顾问 John Bartow的工作领域是网络和PC安全,他提供了自己从事的咨询公司, WinHaven Computer Consulti ...
- linux---学习3
1.free命令可以显示当前系统未使用的和已使用的内存数目,还可以显示被内核使用的内存缓冲区. //-m:以MB为单位显示内存使用情况: free -m 2.vmstat命令的含义为显示虚拟内存状态, ...