spark JAVA 开发环境搭建及远程调试
spark JAVA 开发环境搭建及远程调试
以后要在项目中使用Spark 用户昵称文本做一下聚类分析,找出一些违规的昵称信息。以前折腾过Hadoop,于是看了下Spark官网的文档以及 github 上 官方提供的examples,看完了之后决定动手跑一个文本聚类的demo,于是有了下文。
1. 环境介绍
本地开发环境是:IDEA2018、JDK8、windows 10。远程服务器 Ubuntu 16.04.3 LTS上安装了spark-2.3.1-bin-hadoop2.7
看spark官网介绍,有两种形式(不是Spark Application Execution Mode)来启动spark
Running the Examples and Shell
比如说
./bin/pyspark --master local[2]启动的是一个交互式的命令行界面,可以在4040端口查看作业。Launching on a Cluster
spark 集群,有多种部署选项:Standalone。另外还有:YARN,Mesos(将集群中的资源将由资源管理器来管理)。
对于Standalone,
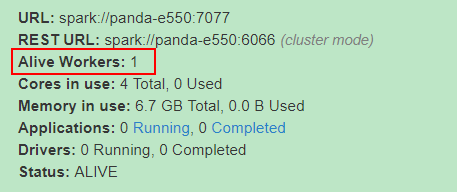
./sbin/start-master.sh启动Master,通过8080端口就能看到:集群的情况。

再通过./sbin/start-slave.sh spark://panda-e550:7077 启动slave:Alive Workers 就是启动的slave。
执行jps:看到Master和Worker:
~/spark-2.3.1-bin-hadoop2.7$ jps
45437 Master
50429 Worker
下面介绍一下在本地windows10 环境下写Spark程序,然后连接到远程的这台Ubuntu机器上的Spark上进行调试。
2. 一个简单的开发环境
创建Maven工程,根据官网提供的Spark Examples 来演示聚类算法(JavaBisectingKMeansExample )的运行过程,并介绍如何配置Spark调试环境。
2.1添加maven 依赖:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.3.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-mllib -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.11</artifactId>
<version>2.3.1</version>
<!--<scope>runtime</scope>-->
</dependency>
2.2 编写代码:
package net.hapjin.spark;
import org.apache.spark.ml.clustering.BisectingKMeans;
import org.apache.spark.ml.clustering.BisectingKMeansModel;
import org.apache.spark.ml.linalg.Vector;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
public class JavaBisectingKMeansExample {
public static void main(String[] args) {
// SparkSession spark = SparkSession.builder().appName("JavaBisectingKMeansExample").getOrCreate();
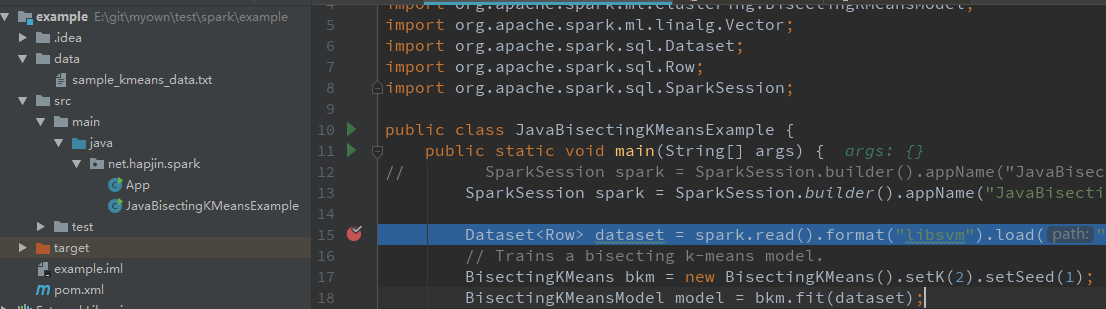
SparkSession spark = SparkSession.builder().appName("JavaBisectingKMeansExample").master("spark://xx.xx.129.170:7077").getOrCreate();
// Dataset<Row> dataset = spark.read().format("libsvm").load(".\\data\\sample_kmeans_data.txt");
Dataset<Row> dataset = spark.read().format("libsvm").load("hdfs://172.25.129.170:9000/user/panda/sample_kmeans_data.txt");
// Dataset<Row> dataset = spark.read().format("libsvm").load("file:///E:/git/myown/test/spark/example/data/sample_kmeans_data.txt");
// Trains a bisecting k-means model.
BisectingKMeans bkm = new BisectingKMeans().setK(2).setSeed(1);
BisectingKMeansModel model = bkm.fit(dataset);
// Evaluate clustering.
double cost = model.computeCost(dataset);
System.out.println("Within Set Sum of Squared Errors = " + cost);
// Shows the result.
System.out.println("Cluster Centers: ");
Vector[] centers = model.clusterCenters();
for (Vector center : centers) {
System.out.println(center);
}
// $example off$
spark.stop();
}
}
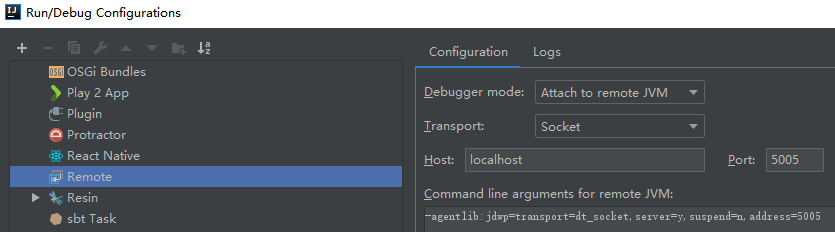
2.3 配置远程调试环境
在IDEA中,"Run"-->"Edit Configurations"-->"Template"--->"Remote",点击 "+"号:
报错:
Could not locate executable null\bin\winutils.exe
去这个github下载对应的Hadoop版本的winutils.exe。

配置windows10环境变量:HADOOP_HOME,并将该环境变量添加到 Path 环境变量下%HADOOP_HOME%\bin。
再次Debug调试,成功进入断点:(如果报拒绝连接的错误,修改一下 conf/spark-env.sh 指定SPARK_LOCAL_IP为机器的IP地址,然后再 修改 /etc/hosts 文件 将主机名与机器IP地址相对应即可)
其实,在本地开发环境(Windows10)连不上远程的服务器时,先在Windows下telnet 一下看一下能不能通。如果不能通,那肯定连不上了。另外,可以在远程服务器上看下相应的端口绑定在哪个IP地址上,是不是绑定到了环回地址上了。比如下面这个spark master默认端口绑定在127.0.1.1上,那你本地的开发环境肯定连不上这个端口了:
~/spark-2.3.1-bin-hadoop2.7$ netstat -anp | grep 7077
tcp6 0 0 127.0.1.1:7077 ::spark JAVA 开发环境搭建及远程调试的更多相关文章
- CUDA并行程序设计 开发环境搭建与远程调试
课题需要用到GPU加速.目前使用的台式电脑只有核心显卡,而实验室有一台服务器装有NVIDIA GTX980独显.因此,想搭建一个CUDA的开发环境,来实现在台式机上面开发cuda程序,程序在服务器而不 ...
- 超全详解Java开发环境搭建
摘自:https://www.cnblogs.com/wangjiming/p/11278577.html 超全详解Java开发环境搭建 在项目产品开发中,开发环境搭建是软件开发的首要阶段,也是必 ...
- Java 开发环境搭建
找到一篇很不錯的Java開發環境搭建的博客, 原文地址為:http://www.cnblogs.com/bribe/p/3377008.html Java 开发环境搭建 一.开发工具获取 1.开发工具 ...
- 开始JAVA编程的敲门砖——JAVA开发环境搭建
从头开始的java编程--JAVA开发环境搭建 一.什么是java的开发环境? 顾名思义java的开发环境是提供并保证整个java程序开发运行的必要的环境,搭建java开发环境是开始java编程的敲门 ...
- 【java系列】java开发环境搭建
描述 本篇文章主要讲解基于windows 10系统搭建java开发环境,主要内容包括如下: (1)安装资料准备 (2)安装过程讲解 (3)测试是否安装成功 (4)Hello Word测试 1 安装 ...
- Windows系统下JAVA开发环境搭建
首先我们需要下载JDK(JAVA Development Kit),JDK是整个java开发的核心,它包含了JAVA的运行环境,JAVA工具和JAVA基础的类库. 下载地址:http://www.or ...
- MAC系统 -java开发环境搭建
MAC - java开发环境搭建 软件: jdk Intellij IDEA:java开发工具 maven:jar包管理 git :源码管理 sourceTree :源码管理GUI客户端 Studio ...
- 初识Java以及JAVA开发环境搭建
目录 JAVA帝国的诞生 C&C++ JAVA JAVA特性和优势 JAVA三大版本 JDK.JRE.JVE JAVA开发环境搭建 JDK下载与安装.卸载 安装JDK 卸载JDK JDK目录介 ...
- Java开发环境搭建的准备工作
Java开发环境搭建的准备工作 网络配置(修改hosts) 什么时候需要 比如我们在安装homeBrew的时候会遇到 curl: (7) Failed to connect to raw.github ...
随机推荐
- WebRtc编译好的vs2015源码
一直想看webrtc的源码,苦于FQ能力有限且整个编译过程耗时巨大,故求助于互联网.在互联网寻找许久编译好的Webrtc源码,好多版本下载下来总是报各种错误,很是失落. 皇天不负有心人,终于寻得一版可 ...
- axios请求本地的json文件在打包部署到子目录域名下,路径找不到
前言: 因为要同时部署两个项目,有一个是部署到域名下面的子目录下,如:https://xxx.com/siot-admin vue 项目中使用axios请求了本地项目的static文件夹下的json文 ...
- 初识shell编程
1.shell编程之为什么学.怎么学 为什么学shell编程 Linux系统批量管理 提升工作效率,减少重复工作 学好shell编程所需要的基础知识 熟悉使用vim编辑器 熟悉SSH终端 熟练掌握Li ...
- WEB框架-Django组件学习-分页器学习
1.分页器基础学习 1.1 补充知识-批量创建 数据库中数据批量创建,不要每创建一个就往数据库中塞一个,会造成撞库,造成大量I/O操作,速速较慢,应该采用一次性创建大量数据,一次性将大量数据塞入到数据 ...
- np.mgrid的用法
功能:返回多维结构,常见的如2D图形,3D图形 np.mgrid[ 第1维,第2维 ,第3维 , …] 第n维的书写形式为: a:b:c c表示步长,为实数表示间隔:该为长度为[a,b),左开右闭 或 ...
- 四:OVS+GRE之网络节点
关于Neutron上的三种Agent的作用: Neutron-OVS-Agent:从OVS-Plugin上接收tunnel和tunnel flow的配置,驱动OVS来建立GRE Tunnel Neut ...
- BZOJ3174 TJOI2013 拯救小矮人 贪心、DP
传送门 原问题等价于:先给\(n\)个人排好顺序.叠在一起,然后从顶往底能走即走,问最多能走多少人 注意到一个问题:如果存在两个人\(i,j\)满足\(a_i + b_i < a_j + b_j ...
- ELement-UI之树形表格(treeTable&&treeGrid)
先上图来一波 支持无限层级,支持新增子级时自动打开父级,支持编辑时自动打开父级,执行操作时自带动画效果,支持初始化时设置全部打开或者关闭,支持一键展开与关闭丝滑般的无延迟 由于基于el-table扩展 ...
- @deprecated 的方法处理
因为需要用到poi,偷懒不太想看官方文档,同时自己的github账号忘记密码了.所以直接在别人博客那拷贝一段代码来模仿修改创建HSSF的xsl文件. 虽然能运行,但发现代码太多横线,可以知道方法被标注 ...
- REST命令控制Player
本文用Postman工具演示通过REST控制Cnario Playr 注意:Player的REST通信默认关闭,使用前需要从Setting>>Remote devices打开Use RES ...