用三台虚拟机搭建Hadoop全分布集群
用三台虚拟机搭建Hadoop全分布集群
所有的软件都装在/home/software下
虚拟机系统:centos6.5
jdk版本:1.8.0_181
zookeeper版本:3.4.7
hadoop版本:2.7.1
1.安装jdk
准备好免安装压缩包放在/home/software下
cd /home/software
tar -xvf jdk-8u181-linux-x64.tar.gz
配置环境变量
vim /etc/profile
末尾添加
export JAVA_HOME=/home/software/jdk1.8.0_181
export CLASSPATH=$:CLASSPATH:$JAVA_HOME/lib/
export PATH=$PATH:$JAVA_HOME/bin
source /etc/profile
检查是否配置成功,查看jdk版本
java –version

2.关闭防火墙
service iptables stop
chkconfig iptables off
3.配置主机名
vim /etc/sysconfig/network
HOSTNAME=qyws
三个节点主机名分别设置为qyws,qyws2,qyws3
source /etc/sysconfig/network
4.改hosts文件
vim /etc/hosts
192.168.38.133 qyws
192.168.38.134 qyws2
192.168.38.135 qyws3
5.重启
reboot
6.配置免密登陆
ssh-keygen
ssh-copy-id root@qyws
ssh-copy-id root@qyws2
ssh-copy-id root@qyws3
7.解压zookeeper压缩包
tar –xf zookeeper-3.4..tar.gz
8.搭建zookeeper集群
cd /home/software/zookeeper-3.4./conf
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
14 行
dataDir=/home/software/zookeeper-3.4.7/tmp
末尾追加
server.1=192.168.38.133:2888:3888
server.2=192.168.38.134:2888:3888
server.3=192.168.38.135:2888:3888
9.将配置好的zookeeper拷贝到另两个节点
scp -r zookeeper-3.4. root@qyws2:/home/software/
scp -r zookeeper-3.4. root@qyws3:/home/software/
10.进入zookeeper目录下创建tmp目录,新建myid文件
cd /home/software/zookeeper-3.4.
mkdir tmp
cd tmp
vim myid
三个节点myid分别设置为1,2,3
11.解压hadoop压缩包
tar -xvf hadoop-2.7.1_64bit.tar.gz
12.编辑hadoop-env.sh
cd /home/software/hadoop-2.7./etc/hadoop
vim hadoop-env.sh
25行
export JAVA_HOME=/home/software/jdk1.8.0_181
33行
export HADOOP_CONF_DIR=/home/software/hadoop-2.7.1/etc/hadoop
source hadoop-env.sh
13.编辑core-site.xml
<!--指定hdfs的nameservice,为整个集群起一个别名-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns</value>
</property>
<!--指定Hadoop数据临时存放目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/software/hadoop-2.7.1/tmp</value>
</property>
<!--指定zookeeper的存放地址-->
<property>
<name>ha.zookeeper.quorum</name>
<value>qyws:2181,qyws2:2181,qyws3:2181</value>
</property>
14.编辑hdfs-site.xml
<!--执行hdfs的nameservice为ns,注意要和core-site.xml中的名称保持一致-->
<property>
<name>dfs.nameservices</name>
<value>ns</value>
</property>
<!--ns集群下有两个namenode,分别为nn1, nn2-->
<property>
<name>dfs.ha.namenodes.ns</name>
<value>nn1,nn2</value>
</property>
<!--nn1的RPC通信-->
<property>
<name>dfs.namenode.rpc-address.ns.nn1</name>
<value>qyws:9000</value>
</property>
<!--nn1的http通信-->
<property>
<name>dfs.namenode.http-address.ns.nn1</name>
<value>qyws:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn2</name>
<value>qyws2:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn2</name>
<value>qyws2:50070</value>
</property>
<!--指定namenode的元数据在JournalNode上存放的位置,这样,namenode2可以从journalnode集群里的指定位置上获取信息,达到热备效果-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://qyws:8485;qyws2:8485;qyws3:8485/ns</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/software/hadoop-2.7.1/tmp/journal</value>
</property>
<!-- 开启NameNode故障时自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!--配置namenode存放元数据的目录,可以不配置,如果不配置则默认放到hadoop.tmp.dir下-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/software/hadoop-2.7.1/tmp/hdfs/name</value>
</property>
<!--配置datanode存放元数据的目录,可以不配置,如果不配置则默认放到hadoop.tmp.dir下-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///home/software/hadoop-2.7.1/tmp/hdfs/data</value>
</property>
<!--配置复本数量-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--设置用户的操作权限,false表示关闭权限验证,任何用户都可以操作-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
15.编辑mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
16.编辑yarn-site.xml
<!--配置yarn的高可用-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--指定两个resourcemaneger的名称-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!--配置rm1的主机-->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>qyws</value>
</property>
<!--配置rm2的主机-->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>qyws3</value>
</property>
<!--开启yarn恢复机制-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--执行rm恢复机制实现类-->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!--配置zookeeper的地址-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>qyws:2181,qyws2:2181,qyws3:2181</value>
</property>
<!--执行yarn集群的别名-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>ns-yarn</value>
</property>
<!-- 指定nodemanager启动时加载server的方式为shuffle server -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定resourcemanager地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>qyws3</value>
</property>
17.编辑slaves
vim /home/software/hadoop-2.7./etc/hadoop/slaves
qyws
qyws2
qyws3
18.把配置好的hadoop拷贝到其他节点
scp -r hadoop-2.7. root@qyws2:/home/software/
scp -r hadoop-2.7. root@qyws3:/home/software/
19.配置环境变量
vim /etc/profile
末尾添加
export HADOOP_HOME=/home/software/hadoop-2.7.
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
20.三个节点启动zookeeper
cd /home/software/zookeeper-3.4./bin
sh zkServer.sh start
查看zookeeper状态
sh zkServer.sh status



21.格式化zookeeper(在第一个节点操作即可):
hdfs zkfc -formatZK
22.在每个节点启动JournalNode:
hadoop-daemon.sh start journalnode
23.在第一个节点上格式化NameNode:
hadoop namenode -format
24.在第一个节点上启动NameNode:
hadoop-daemon.sh start namenode
25.在第二个节点上格式化NameNode:
hdfs namenode -bootstrapStandby
26.在第二个节点上启动NameNode:
hadoop-daemon.sh start namenode
27.在三个节点上启动DataNode:
hadoop-daemon.sh start datanode
28.在第一个节点和第二个节点上启动zkfc(FailoverController):
hadoop-daemon.sh start zkfc
29.在第一个节点上启动Yarn:
start-yarn.sh
30.在第三个节点上启动ResourceManager:
yarn-daemon.sh start resourcemanager
31.查看运行的服务

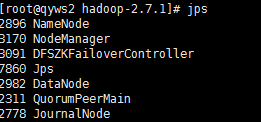
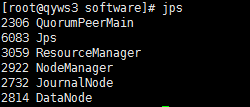
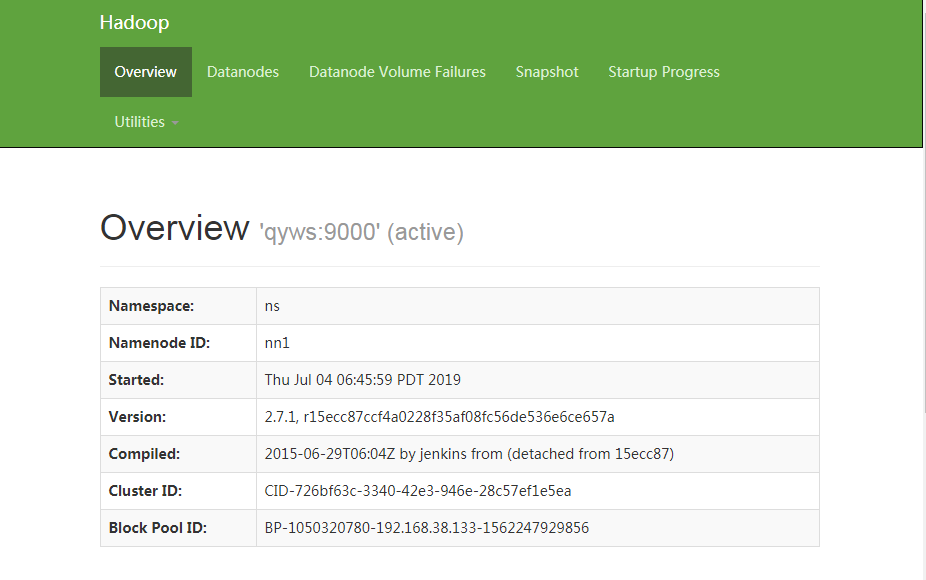
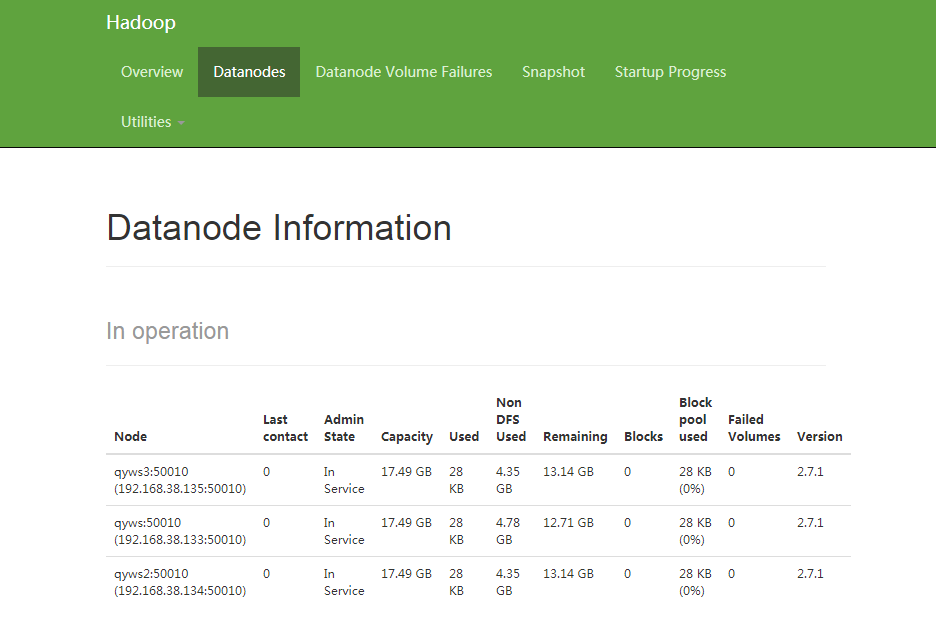
32.查看第一个节点namenode
浏览器输入http://192.168.38.133:50070
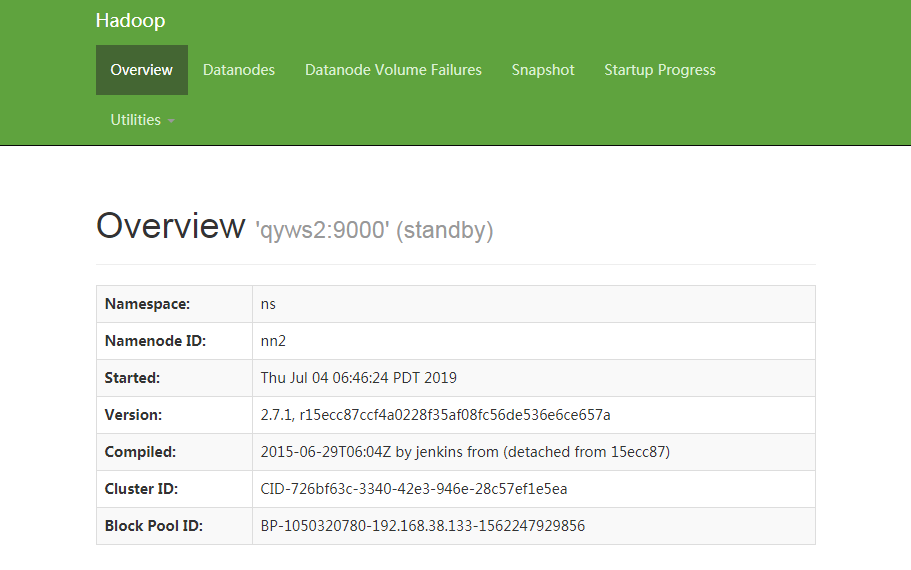
查看第二个节点namenode(主备)
浏览器输入http://192.168.38.134:50070
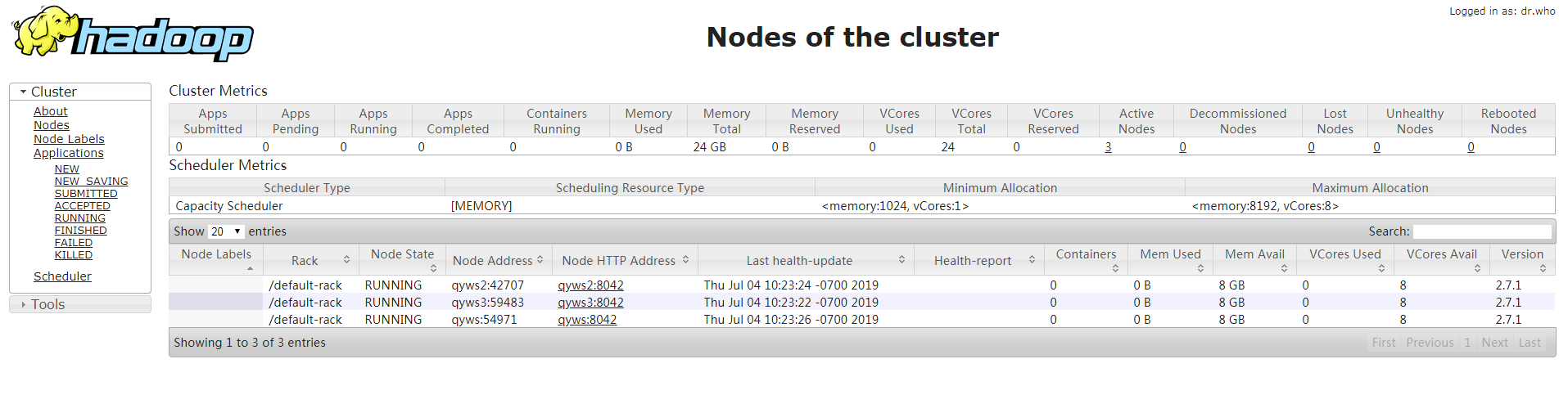
33.访问管理页面http://192.168.38.133:8088
用三台虚拟机搭建Hadoop全分布集群的更多相关文章
- Hadoop(三)手把手教你搭建Hadoop全分布式集群
前言 上一篇介绍了伪分布式集群的搭建,其实在我们的生产环境中我们肯定不是使用只有一台服务器的伪分布式集群当中的.接下来我将给大家分享一下全分布式集群的搭建! 其实搭建最基本的全分布式集群和伪分布式集群 ...
- Hadoop(三)搭建Hadoop全分布式集群
原文地址:http://www.cnblogs.com/zhangyinhua/p/7652686.html 阅读目录(Content) 一.搭建Hadoop全分布式集群前提 1.1.网络 1.2.安 ...
- Kafka1 利用虚拟机搭建自己的Kafka集群
前言: 上周末自己学习了一下Kafka,参考网上的文章,学习过程中还是比较顺利的,遇到的一些问题最终也都解决了,现在将学习的过程记录与此,供以后自己查阅,如果能帮助到其他人,自然是更好的. ...
- 『实践』VirtualBox 5.1.18+Centos 6.8+hadoop 2.7.3搭建hadoop完全分布式集群及基于HDFS的网盘实现
『实践』VirtualBox 5.1.18+Centos 6.8+hadoop 2.7.3搭建hadoop完全分布式集群及基于HDFS的网盘实现 1.基本设定和软件版本 主机名 ip 对应角色 mas ...
- ZooKeeper1 利用虚拟机搭建自己的ZooKeeper集群
前言: 前段时间自己参考网上的文章,梳理了一下基于分布式环境部署的业务系统在解决数据一致性问题上的方案,其中有一个方案是使用ZooKeeper,加之在大数据处理中,ZooKeeper确实起 ...
- vmware10上三台虚拟机的Hadoop2.5.1集群搭建
由于官方版本的Hadoop是32位,若在64位Linux上安装,则必须先重新在64位环境下编译Hadoop源代码.本环境采用编译后的hadoop2.5.1 . 安装参考博客: 1 http://www ...
- hadoop学习笔记(六):hadoop全分布式集群的环境搭建
本文原创,如需转载,请注明作者以及原文链接! 一.前期准备: 1.jdk安装 不要用centos7自带的openJDK2.hostname 配置 配置位置:/etc/s ...
- hadoop学习通过虚拟机安装hadoop完全分布式集群
要想深入的学习hadoop数据分析技术,首要的任务是必须要将hadoop集群环境搭建起来,可以将hadoop简化地想象成一个小软件,通过在各个物理节点上安装这个小软件,然后将其运行起来,就是一个had ...
- ZooKeeper学习之路 (九)利用ZooKeeper搭建Hadoop的HA集群
Hadoop HA 原理概述 为什么会有 hadoop HA 机制呢? HA:High Available,高可用 在Hadoop 2.0之前,在HDFS 集群中NameNode 存在单点故障 (SP ...
随机推荐
- noi 2011
描述 已知长度最大为200位的正整数n,请求出2011^n的后四位. 输入 第一行为一个正整数k,代表有k组数据,k<=200接下来的k行, 每行都有一个正整数n,n的位数<=200 输出 ...
- codeforces#1196F. K-th Path(最短路,思维题)
题目链接: https://codeforces.com/contest/1196/problem/F 题意: 在无向图的所有最短路点对中,求出第$k$大 数据范围: $ 1 \leq k \leq ...
- springMVC课程笔记(二)springMVC组件配置
1.springMVC的DispatcherServlet前段控制器配置,如下图所示在web.xml中配置如下内容: 2.在spring配置文件中,配置处理器适配器HandlerAdapter和映射器 ...
- SDN上机第4次作业
1. 解压安装OpenDayLight控制器(本次实验统一使用Beryllium版本) 1)JDK的安装与环境配置 嗯,装这个东西还得先装JDK: 在线真人手把手教你安装jdk 输入sud ...
- arcgis 面或线要素类上的搜索游标
import arcpy infc = arcpy.GetParameterAsText(0) # Identify the geometry field # desc = arcpy.Describ ...
- 问题解决:fatal error C1083: 无法打开包括文件:No such file or directory
fatal error C1083: 无法打开包括文件:No such file or directory将别的工程直接用VS2010打开出现了该问题,此时必须检查是不是: 1. 如果要引入的这些.h ...
- linux下编译安装ACE-6.4.2(adpative communication environment)
1.环境 CentOS-6.5-x86_64-bin-DVD1.iso VMware_workstation_full_12.5.2 (2).exe ACE-6.4.2.tar.gz 下载链接:htt ...
- 利用phpStudy 探针 提权网站服务器
声明: 本教程仅仅是演示管理员安全意识不强,存在弱口令情况.网站被非法入侵的演示,请勿用于恶意用途! 今天看到论坛有人发布了一个通过这phpStudy 探针 关键字搜索检索提权网址服务器,这个挺简单的 ...
- 使用AWS、Docker与Rancher提供弹性的生产级服务
2017-07-26 开始想你的 RancherLabs AWS Summit 2017 Beijing已经圆满落幕啦!亚马逊公司首席技术官沃纳·威格尔博士莅临现场,分享 AWS 最新云解决方案,把握 ...
- 解决DBGridEh遍历记录后不移动当前行位置的方法
解决DBGridEh遍历记录后不移动当前行位置的方法 在用DBGridEh配合ClientDataSet使用时,需要知道用户选择了哪些记录,可用遍历记录的方法查询选择列是否为真,但在这之后,Clien ...