数据库优化SQL
sql优化规则:
1.对于查询,尽量不要使用全表扫描,尽量在where子句以及order by所对应的字段建立索引。
2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描。
最好不要给数据库留NULL,尽可能的使用 NOT NULL填充数据库.备注、描述、评论之类的可以设置为 NULL,其他的,最好不要使用NULL
一些限制索引的写法如下:
①使用不等运算符(<> !=)
②使用IS NULL或者is notnull做判断。比如NVL等
③使用函数
select t.* from eb_bill_app t where substr(t.apply_id,1,6) =''
④比较不匹配的数据类型.本来该类型为char,却使用int比较,oracle自动调用to_number函数,导致不使用索引(字符型字段为数字时在where条件里不添加引号)。
⑤like "%_" 百分号在前。
⑥not in ,not exist.
⑦单独引用复合索引里非第一位置的索引列
⑧B-tree索引 is null不会走,is not null会走,位图索引 is null,is not null 都会走。联合索引 is not null 只要在建立的索引列(不分先后)都会走。
⑨应尽量避免在 where 子句中使用 or 来连接条件,如果一个字段有索引,一个字段没有索引,将导致引擎放弃使用索引而进行全表扫描
3.select语句中避免使用*,因为oracle在解析过程中会将*转换为所有的列名。
4.尽量多使用commit,,在事务控制允许的范围内,commit有利于释放资源。
5.使用表别名,减少由column引起的歧义。
6.避免使用having
7.对于多张大数据量(这里几百条就算大了)的表JOIN,要先分页再JOIN,否则逻辑读会很高,性能很差。
8.如果使用到了临时表,在存储过程的最后务必将所有的临时表显式删除,先 truncate table ,然后 drop table ,这样可以避免系统表的较长时间锁定。
9.如果数据量过大,优先考虑表分区
改造sql示例:数据库中有600万数据左右,仅仅改造一下子查询。查询出来的时间相差很大
SELECT *
FROM (SELECT ROW_.*, ROWNUM ROWNUM_
FROM (SELECT T.*,
GY.F_NAME applyOperatorName,
CUST.CUST_NAME,
(SELECT COUNT(1)
FROM BL_STOCKBILL BILL
WHERE BILL.BILL_ID IN
(SELECT EXT.BILL_ID
FROM BL_STOCKBILL_EXT EXT
WHERE EXT.PLEDGE_APP_ID = T.PLEDGE_ID
AND EXT.STATUS = '')) AS BILLS,
(SELECT SUM(BILL.BILL_AMT)
FROM BL_STOCKBILL BILL
WHERE BILL.BILL_ID IN
(SELECT EXT.BILL_ID
FROM BL_STOCKBILL_EXT EXT
WHERE EXT.PLEDGE_APP_ID = T.PLEDGE_ID
AND EXT.STATUS = '')) AS BILLTOTALAMT
FROM EB_BL_PLEDGE_APP T, LSGYZD GY, CUST_BASE CUST
WHERE T.APP_OPERATOR = GY.F_GYBH(+)
AND CUST.CUST_CODE(+) = T.CUST_CODE
AND T.SOURCE_MODEL = ''
AND T.STATUS = ''
AND T.APP_OPERATOR = ''
AND T.CUST_CODE = '') ROW_
WHERE ROWNUM <= 10)
WHERE ROWNUM_ > 0;
耗时:
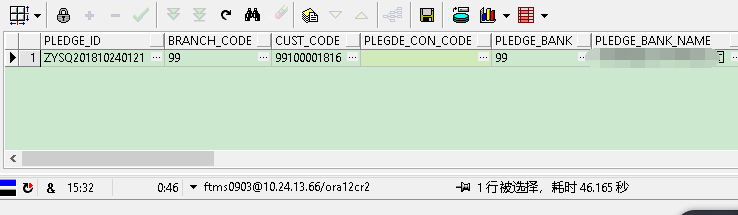
优化后:
SELECT *
FROM (SELECT ROW_.*, ROWNUM ROWNUM_
FROM (SELECT T.*,
GY.F_NAME applyOperatorName,
CUST.CUST_NAME,
TMP.BILLS,
TMP.BILLTOTALAMT
FROM EB_BL_PLEDGE_APP T,
LSGYZD GY,
CUST_BASE CUST,
(SELECT EXT.PLEDGE_APP_ID,
COUNT(1) BILLS,
SUM(BILL.BILL_AMT) BILLTOTALAMT
FROM BL_STOCKBILL BILL,BL_STOCKBILL_EXT EXT
WHERE BILL.BILL_ID =EXT.BILL_ID
AND EXT.STATUS = ''
GROUP BY EXT.PLEDGE_APP_ID) TMP
WHERE T.APP_OPERATOR = GY.F_GYBH(+)
AND CUST.CUST_CODE(+) = T.CUST_CODE
AND T.SOURCE_MODEL = ''
AND TMP.PLEDGE_APP_ID = T.PLEDGE_ID
AND T.STATUS = ''
AND T.APP_OPERATOR = ''
AND T.CUST_CODE = '') ROW_
WHERE ROWNUM <= 10)
WHERE ROWNUM_ > 0;
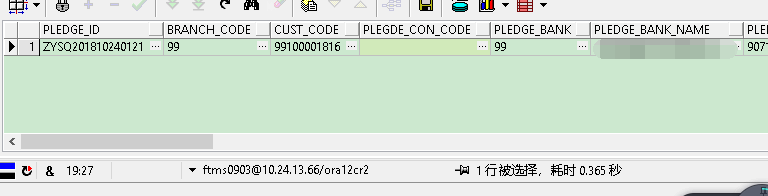
数据库优化SQL的更多相关文章
- 数据库优化 - SQL优化
前面一篇文章从实例的角度进行数据库优化,通过配置一些参数让数据库性能达到最优.但是一些"不好"的SQL也会导致数据库查询变慢,影响业务流程.本文从SQL角度进行数据库优化,提升SQ ...
- 转载 数据库优化 - SQL优化
判断问题SQL判断SQL是否有问题时可以通过两个表象进行判断: 系统级别表象CPU消耗严重IO等待严重页面响应时间过长应用的日志出现超时等错误可以使用sar命令,top命令查看当前系统状态. 也可以通 ...
- 大数据量高并发的数据库优化,sql查询优化
一.数据库结构的设计 如果不能设计一个合理的数据库模型,不仅会增加客户端和服务器段程序的编程和维护的难度,而且将会影响系统实际运行的性能.所以,在一个系统开始实施之前,完备的数据库模型的设计是必须的. ...
- 【转】mysql数据库优化大全
数据库优化 sql语句优化 索引优化 加缓存 读写分离 分区 分布式数据库(垂直切分) 水平切分 MyISAM和InnoDB的区别: 1. InnoDB支持事务,MyISAM不支持,对于InnoDB每 ...
- mysql数据库优化大全
转载:https://blog.csdn.net/weixin_38112233/article/details/79054661 数据库优化 sql语句优化 索引优化 加缓存 读写分离 分区 分布式 ...
- MySQL数据库优化、设计与高级应用
MySQL数据库优化主要涉及两个方面,一方面是对SQL语句优化,另一方面是对数据库服务器和数据库配置的优化. 数据库优化 SQL语句优化 为了更好的看到SQL语句执行效率的差异,建议创建几个结构复杂的 ...
- 数据库优化实践【MS SQL优化开篇】
数据库定义: 数据库是依照某种数据模型组织起来并存在二级存储器中的数据集合,此集合具有尽可能不重复,以最优方式为特定组织提供多种应用服务,其数据结构独立于应用程序,对数据的CRUD操作进行统一管理和控 ...
- 基于Oracle的SQL优化(社区万众期待 数据库优化扛鼎巨著)
基于Oracle的SQL优化(社区万众期待数据库优化扛鼎巨著) 崔华 编 ISBN 978-7-121-21758-6 2014年1月出版 定价:128.00元 856页 16开 编辑推荐 本土O ...
- sql 数据量高并发的数据库优化(转)
Mysql 大数据量高并发的数据库优化 一.数据库结构的设计 如果不能设计一个合理的数据库模型,不仅会增加客户端和服务器段程序的编程和维护的难度,而且将会影响系统实际运行的性能.所以,在一个系统开始实 ...
随机推荐
- ICEM—八分之一球(2D转3D)
原视频下载地址:https://yunpan.cn/cS3UPRtn5rVwY 访问密码 3d8d
- 重读APUE(4)-fcntl和ioctl的区别
fcntl(File Control)-文件控制 ioctl(In/Out Control)-I/O控制 1. fcntl作用于文件,提供对文件的基础控制:ioctl作用于文件和设备对象,一般用来向设 ...
- sqlserver 锁表进程及执行的SQL
--1.查进程select request_session_id spid,OBJECT_NAME(resource_associated_entity_id) tableNamefrom sys.d ...
- cmder的segmentation fault错误修复
Segmentation fault 现场还原 问题出现的原因是我在 cmder的命令行里执行了cmder /register ALL命令,本意是把cmder放到右键菜单里去的 但我没想到的是,各种不 ...
- ffmpeg+nginx搭建直播服务器
Nginx与Nginx-rtmp-module搭建RTMP视频直播和点播服务器 https://zhuanlan.zhihu.com/p/28009037 FFmpeg总结(十三)用ffmpeg基于n ...
- 生成要发送到社区的内核补丁时如何指定发布的版本号(v2,v3...)?
1. 生成一个补丁 git format-patch --subject-prefix=v2 -1 那么生成的patch文件就会有如下类似的信息: Subject: [v2] your descrip ...
- 如何使用git cherry-pick将同一个仓库的某个分支的某些commit合并到当前分支?
答: git cherry-pick <another-branch's commit-id>
- SQL-W3School-基础:SQL DELETE 语句
ylbtech-SQL-W3School-基础:SQL DELETE 语句 1.返回顶部 1. DELETE 语句 DELETE 语句用于删除表中的行. 语法 DELETE FROM 表名称 WHER ...
- SpringBoot 部署到Linux开机自启动和运行
前文 SpringBoot是一个强大的微服务框架,通常都是打包项目成Jar包,并部署到服务器上,本文以Linux服务器部署为主 开机自启动 博文:<https://www.cnblogs.com ...
- getchwd() 函数返回当前工作目录。
getchwd() 函数返回当前工作目录.