pandas -- DataFrame的级联以及合并操作
开发环境
- anaconda
- 集成环境:集成好了数据分析和机器学习中所需要的全部环境
- 安装目录不可以有中文和特殊符号
- jupyter
- anaconda提供的一个基于浏览器的可视化开发工具
import pandas as pd
import numpy as np
级联操作 -- 对应表格
- pd.concat
- pd.append
- pandas使用pd.concat函数,与np.concatenate函数类似,只是多了一些参数:
- objs
- axis=0
- keys
- join='outer' / 'inner':表示的是级联的方式,outer会将所有的项进行级联(忽略匹配和不匹配),而inner只会将匹配的项级联到一起,不匹配的不级联
- ignore_index=False
匹配级联
df1 = pd.DataFrame(data=np.random.randint(0,100,size=(5,3)),columns=['A','B','C'])
df2 = pd.DataFrame(data=np.random.randint(0,100,size=(5,3)),columns=['A','D','C'])
pd.concat((df1,df2),axis=1) # 行列索引都一致的级联叫做匹配级联
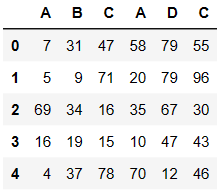
不匹配级联
- 不匹配指的是级联的维度的索引不一致。例如纵向级联时列索引不一致,横向级联时行索引不一致
- 有2种连接方式:
- 外连接:补NaN(默认模式)
- 内连接:只连接匹配的项
pd.concat((df1,df2),axis=0)
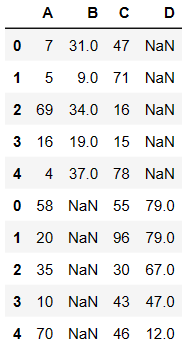
内连接
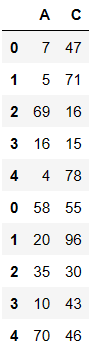
pd.concat((df1,df2),axis=0,join='inner') # inner直把可以级联的级联不能级联不处理
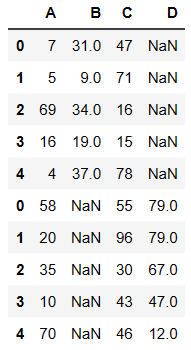
外连接
- 如果想要保留数据的完整性必须使用 outer(外连接)
pd.concat((df1,df2),axis=0,join='outer')
- append函数的使用
df1.append(df2)
合并操作 -- 对应数据
- merge与concat的区别在于,merge需要依据某一共同列来进行合并
- 使用pd.merge()合并时,会自动根据两者相同column名称的那一列,作为key来进行合并。
- 注意每一列元素的顺序不要求一致
一对一合并
from pandas import DataFrame
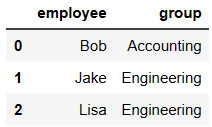
df1 = DataFrame({'employee':['Bob','Jake','Lisa'],
'group':['Accounting','Engineering','Engineering'],
})
df1
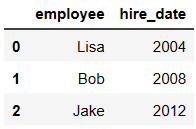
df2 = DataFrame({'employee':['Lisa','Bob','Jake'],
'hire_date':[2004,2008,2012],
})
df2
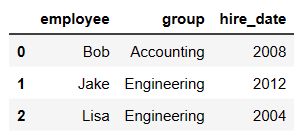
pd.merge(df1,df2,on='employee')
一对多合并
df3 = DataFrame({
'employee':['Lisa','Jake'],
'group':['Accounting','Engineering'],
'hire_date':[2004,2016]})
df3
df4 = DataFrame({'group':['Accounting','Engineering','Engineering'],
'supervisor':['Carly','Guido','Steve']
})
df4
pd.merge(df3,df4) # on如果不写,默认情况下使用两表中公有的列作为合并条件
多对多合并
df1 = DataFrame({'employee':['Bob','Jake','Lisa'],
'group':['Accounting','Engineering','Engineering']})
df1
df5 = DataFrame({'group':['Engineering','Engineering','HR'],
'supervisor':['Carly','Guido','Steve']
})
df5
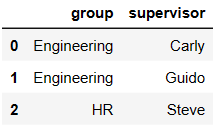
pd.merge(df1,df5,how='right')
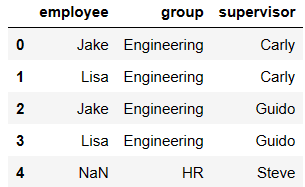
pd.merge(df1,df5,how='left')
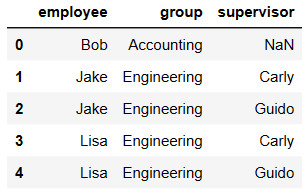
key的规范化
- 当两张表没有可进行连接的列时,可使用left_on和right_on手动指定merge中左右两边的哪一列列作为连接的列
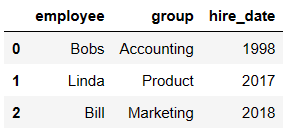
df1 = DataFrame({'employee':['Bobs','Linda','Bill'],
'group':['Accounting','Product','Marketing'],
'hire_date':[1998,2017,2018]})
df1
df5 = DataFrame({'name':['Lisa','Bobs','Bill'],
'hire_dates':[1998,2016,2007]})
df5
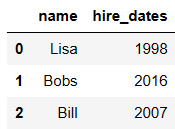
pd.merge(df1,df5,left_on='employee',right_on='name')
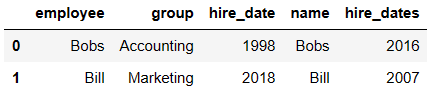
内合并与外合并
- outer取并集
- inner取交集
df6 = DataFrame({'name':['Peter','Paul','Mary'],
'food':['fish','beans','bread']}
)
df7 = DataFrame({'name':['Mary','Joseph'],
'drink':['wine','beer']})
df6
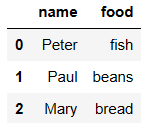
df7

pd.merge(df6,df7,how='outer')
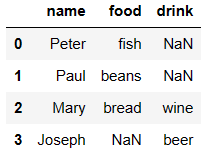
df6 = DataFrame({'name':['Peter','Paul','Mary'],
'food':['fish','beans','bread']}
)
df7 = DataFrame({'name':['Mary','Joseph'],
'drink':['wine','beer']})
df6
df7

pd.merge(df6,df7,how='inner')

pandas -- DataFrame的级联以及合并操作的更多相关文章
- 数据分析03 /基于pandas的数据清洗、级联、合并
数据分析03 /基于pandas的数据清洗.级联.合并 目录 数据分析03 /基于pandas的数据清洗.级联.合并 1. 处理丢失的数据 2. pandas处理空值操作 3. 数据清洗案例 4. 处 ...
- pandas DataFrame的查询方法(loc,iloc,at,iat,ix的用法和区别)
pandas DataFrame的增删查改总结系列文章: pandas DaFrame的创建方法 pandas DataFrame的查询方法 pandas DataFrame行或列的删除方法 pand ...
- pandas 学习 第7篇:DataFrame - 数据处理(应用、操作索引、重命名、合并)
DataFrame的这些操作和Series很相似,这里简单介绍一下. 一,应用和应用映射 apply()函数对每个轴应用一个函数,applymap()函数对每个元素应用一个函数: DataFrame. ...
- Pandas | Dataframe的merge操作,像数据库一样尽情join
今天是pandas数据处理第8篇文章,我们一起来聊聊dataframe的合并. 常见的数据合并操作主要有两种,第一种是我们新生成了新的特征,想要把它和旧的特征合并在一起.第二种是我们新获取了一份数据集 ...
- pandas之合并操作
Pandas 提供的 merge() 函数能够进行高效的合并操作,这与 SQL 关系型数据库的 MERGE 用法非常相似.从字面意思上不难理解,merge 翻译为"合并",指的是将 ...
- pandas DataFrame 数据处理常用操作
Xgboost调参: https://wuhuhu800.github.io/2018/02/28/XGboost_param_share/ https://blog.csdn.net/hx2017/ ...
- Python pandas DataFrame操作
1. 从字典创建Dataframe >>> import pandas as pd >>> dict1 = {'col1':[1,2,5,7],'col2':['a ...
- Python时间处理,datetime中的strftime/strptime+pandas.DataFrame.pivot_table(像groupby之类 的操作)
python中datetime模块非常好用,提供了日期格式和字符串格式相互转化的函数strftime/strptime 1.由日期格式转化为字符串格式的函数为: datetime.datetime.s ...
- pandas.DataFrame的pivot()和unstack()实现行转列
示例: 有如下表需要进行行转列: 代码如下: # -*- coding:utf-8 -*- import pandas as pd import MySQLdb from warnings impor ...
- 如何迭代pandas dataframe的行
from:https://blog.csdn.net/tanzuozhev/article/details/76713387 How to iterate over rows in a DataFra ...
随机推荐
- 如何批量修改 GitHub 代码提交作者
批量修改 GitHub 代码提交作者需要进行以下步骤: 首先,你需要 clone 远程仓库到本地,使用以下命令: git clone <repository-url> ``` 将 `< ...
- 手牵手带你实现mini-vue
1 前言 随着 Vue.React.Angularjs 等框架的诞生,数据驱动视图的理念也深入人心,就 Vue 来说,它拥有着双向数据绑定.虚拟dom.组件化.视图与数据相分离等等造福程序员的优点,那 ...
- Linux安装MongoDB 4.0.3
Linux安装MongoDB 4.0.3 1.准备 CentOS下安装MongoDB 官网提供windows.Linux.OSX系统环境下的安装包,这里主要是记录一下在Linux下的安装.首先到官 ...
- ASIC加速技术在ASIC加速性能优化中的新应用与挑战
目录 1. 引言 2. 技术原理及概念 3. 实现步骤与流程 4. 应用示例与代码实现讲解 5. 优化与改进 1. 引言 随着计算机技术的发展,芯片的性能和面积都得到了极大的提升.为了进一步提高芯片的 ...
- 安装VMware Workstation 16 Pro
下载 官网:https://www.vmware.com/cn/products/workstation-pro/workstation-pro-evaluation.html 注:我是在新毒霸软件管 ...
- 【环境搭建】phpstudy显示目录列表
问题来源 新版本的PHPStudy访问127.0.0.1不再像以前版本一样显示目录列表了 解决办法 打开vhosts.conf 将图中标记出来的一行Options FollowSymLinks Exe ...
- Oracle快速拷贝数据
游标拷贝数据 根据条件进行数据拷贝 -- 游标方式拷贝数据 DECLARE CURSOR cur IS SELECT * FROM JACKPOT WHERE TO_CHAR(JACKPOT.CREA ...
- 长连接:chatgpt流式响应背后的逻辑
一.前言: 提起长连接,我们并不陌生,最常见的长连接非websocket莫属了.即使没有在项目中实际用过,至少也应该有所接触.长连接指在一次网络通信中,客户端与服务器之间建立一条持久的连接,可以在多次 ...
- vue项目node_modules文件过大问题
node_modules目录下.cache下最大文件删除即可(vue-loader)
- Cilium系列-10-启用 IPv6 BIG TCP和启用巨帧
系列文章 Cilium 系列文章 前言 将 Kubernetes 的 CNI 从其他组件切换为 Cilium, 已经可以有效地提升网络的性能. 但是通过对 Cilium 不同模式的切换/功能的启用, ...